
Most AI projects talk about what intelligence can do.
@OpenLedger seems more focused on where intelligence comes from.
That distinction matters.
I've watched enough market cycles to become skeptical whenever a sector turns into the narrative of the month. The pattern rarely changes. A new theme appears, capital floods in, everyone starts repeating the same talking points, and eventually the market realizes that many projects were selling a story rather than solving a problem.
AI is the dominant narrative today.
Which is exactly why I approach projects like OpenLedger with caution instead of excitement.
The AI pitch is easy. Every project mentions models, agents, data, automation, and machine intelligence. Those words alone don't mean much anymore.
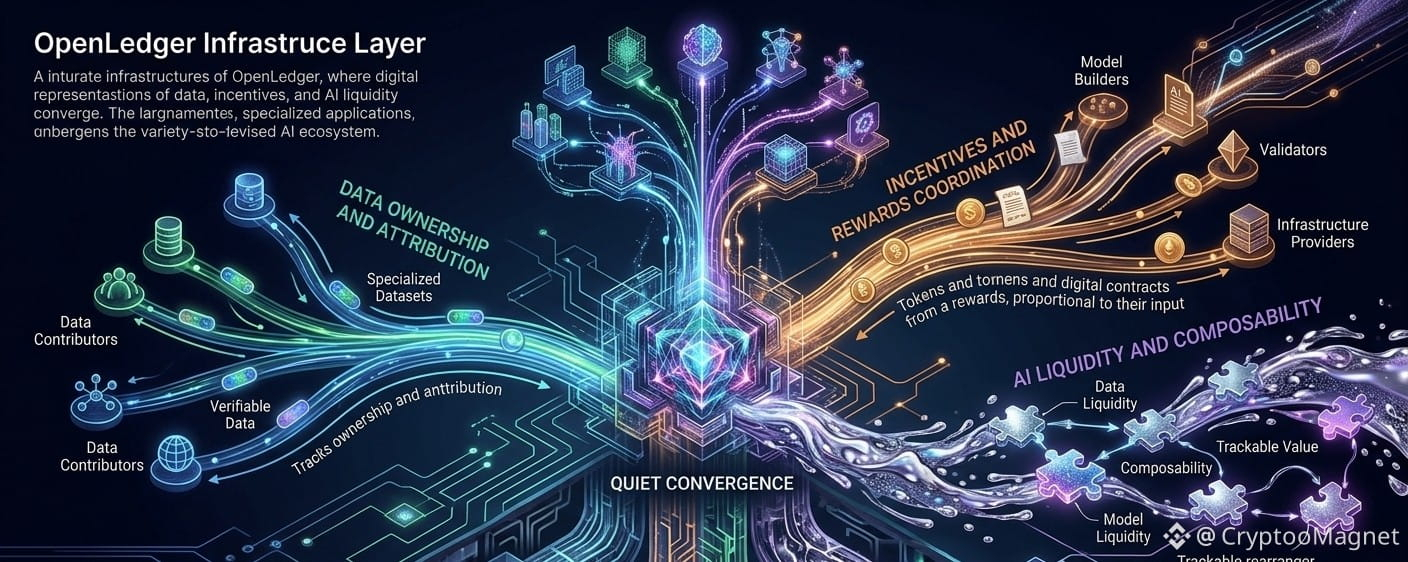
What caught my attention with OpenLedger is that it's focused on a problem most people would rather ignore.
The contribution layer.
Modern AI feels simple from the outside. You ask a question, receive an answer, and move on. But beneath that experience sits a massive web of datasets, model training, fine-tuning, retrieval systems, prompts, feedback loops, and countless contributors whose role often disappears the moment an output is generated.
That's where the friction begins.
As AI becomes a larger part of business, research, finance, software, and automation, questions around ownership and attribution become harder to avoid.
Who supplied the data?
How was it used?
Which inputs actually influenced the result?
Who deserves compensation when value is created?
Today, most of those answers are hidden inside black boxes.
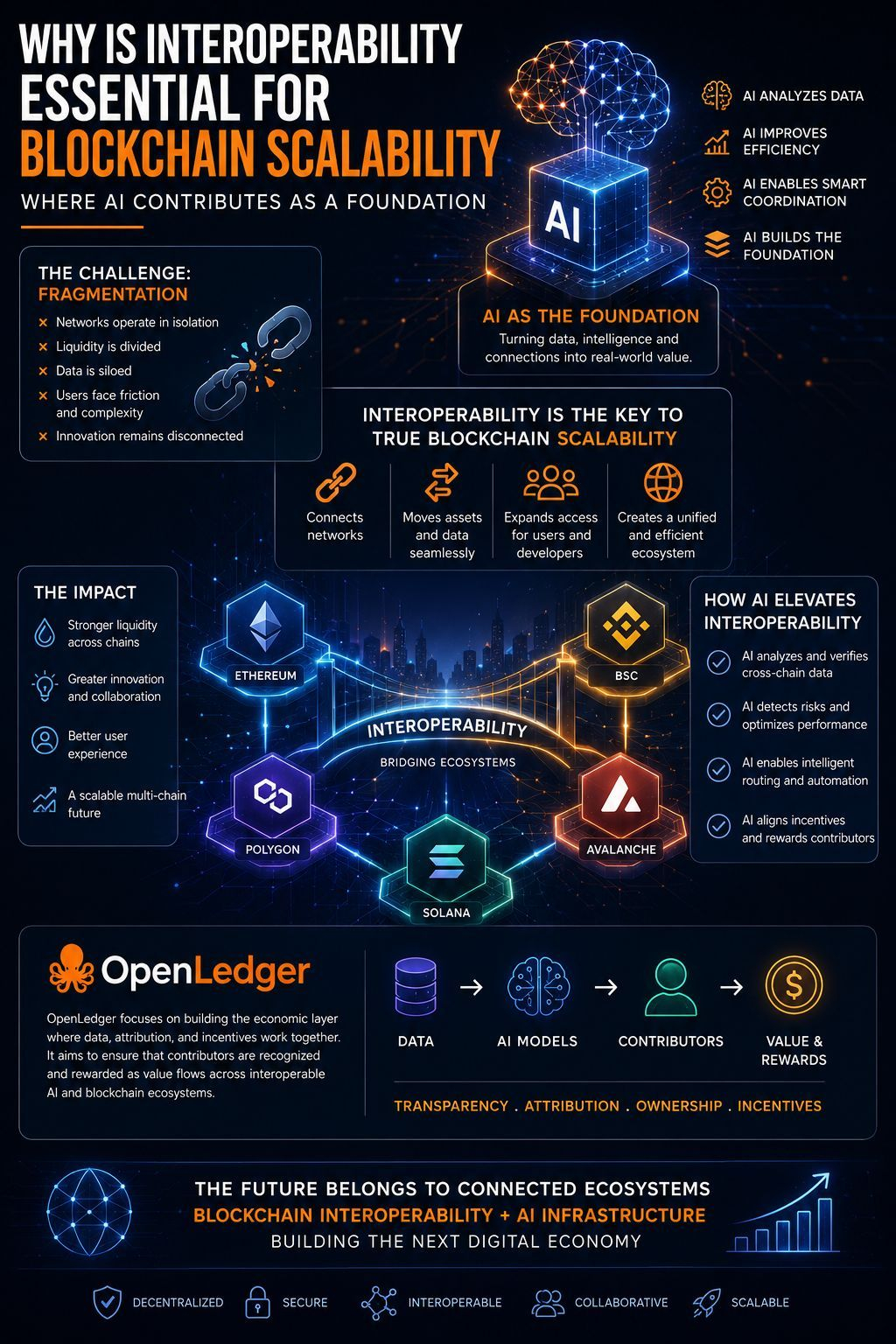
OpenLedger is attempting to make that process more transparent.
Not through marketing slogans, but by building systems designed to track contribution across the AI stack.
That's an ambitious goal.
And frankly, it's far more difficult than many people realize.
Attribution sounds straightforward until you try to implement it in practice.
A single AI output may be influenced by training data, retrieval systems, model architecture, fine-tuning, user interactions, agent decisions, and countless other variables.
Determining who contributed value—and how much—isn't a simple accounting exercise.
It's a complex coordination problem.
That's why I'm less interested in the narrative and more interested in the edge cases.
How does the system handle spam submissions?
How does it prevent reward farming?
How does it separate valuable information from noise?
How does it balance transparency with privacy?
How does it ensure incentives attract useful contributors instead of opportunists?
Those are the questions that ultimately determine whether a system survives.
What makes OpenLedger interesting is that it appears to be building around those challenges rather than pretending they don't exist.
The Datanets concept is a good example.
Not all data carries the same value.
Financial datasets have different requirements than healthcare records.
Legal information behaves differently from research archives.
Code repositories are fundamentally different from creator-generated content.
Treating all data as one giant pool creates inefficiencies.
Creating specialized environments where data can be sourced, verified, and attributed independently feels far more practical.
Because the future of AI probably isn't about collecting the most data.
It's about identifying the most useful data.
Quality, provenance, and accountability may end up being more important than sheer volume.
That is where OpenLedger's thesis becomes interesting.
The project isn't simply asking how AI can become smarter.
It's asking whether AI can become more traceable.
Whether contributors can remain visible.
Whether value can flow back toward sources instead of disappearing into a closed system.
Whether attribution can become economic rather than symbolic.
Those aren't easy problems.
In fact, they may be some of the hardest infrastructure problems in AI.
But they're real problems.
And I'd rather see a project attacking difficult, unsolved issues than launching another AI narrative built entirely around buzzwords.
The market will eventually decide whether OpenLedger succeeds.
The real test won't be social engagement, token speculation, or narrative strength.
It will be adoption.
Do builders use it when incentives disappear?
Do contributors continue providing valuable data?
Do models and agents benefit from traceable inputs?
Does attribution remain useful when the system scales?
Because if those answers are no, then it's just another theory.
If those answers become yes, OpenLedger could end up building something much more important than another AI application.
It could become part of the infrastructure layer that makes the AI economy more accountable, transparent, and sustainable.
And that's the part worth watching.
#OpenLedger @OpenLedger $OPEN $XLM
