@Mira - Trust Layer of AI 7:12 a.m. Quiet conference room. Laptop teetering on printed contracts. HVAC humming like white noise. I was double-checking an AI summary before a client call, because one wrong citation doesn’t just “need a quick fix”—it can burn an hour and torch trust. And all I could think was: why are we still doing this by hand?
I care about this because my work now depends on machine-written text more than I expected. It shows up as draft emails, policy notes, and quick research briefs. Most of it helps, but the weak spot is the confident line that collapses when I check it. That gap between fluent and true is where “verifiable AI” started feeling practical.
That’s also why Mira, often described as a protocol or network for AI output verification, is getting attention right now. I used to file Mira under “promising, but early.” A mainnet launch that includes staking and governance changes that, because it creates consequences for how the system behaves.
I’m running into the demand for verification in the mundane places—internal notes, support replies, quick briefs—where a single shaky claim can quietly spread. A tool drafts an internal memo and someone forwards it as if it were a source. A support agent pastes an answer that sounds right but cites a policy that changed last quarter. As more teams experiment with semi-autonomous “agents” that call tools and take actions, the cost of a single bad claim goes up, because the mistake can travel faster than my ability to catch it.
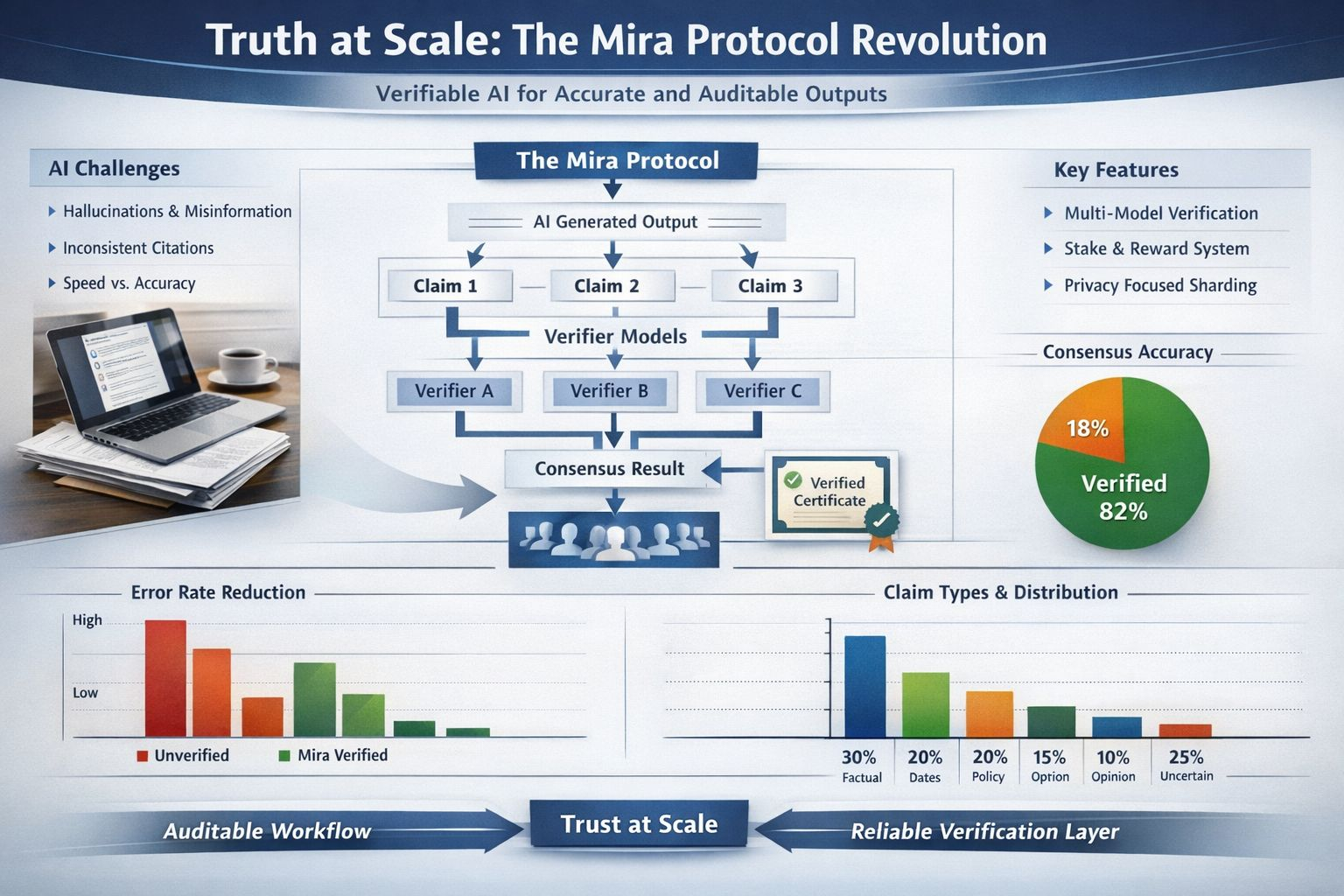
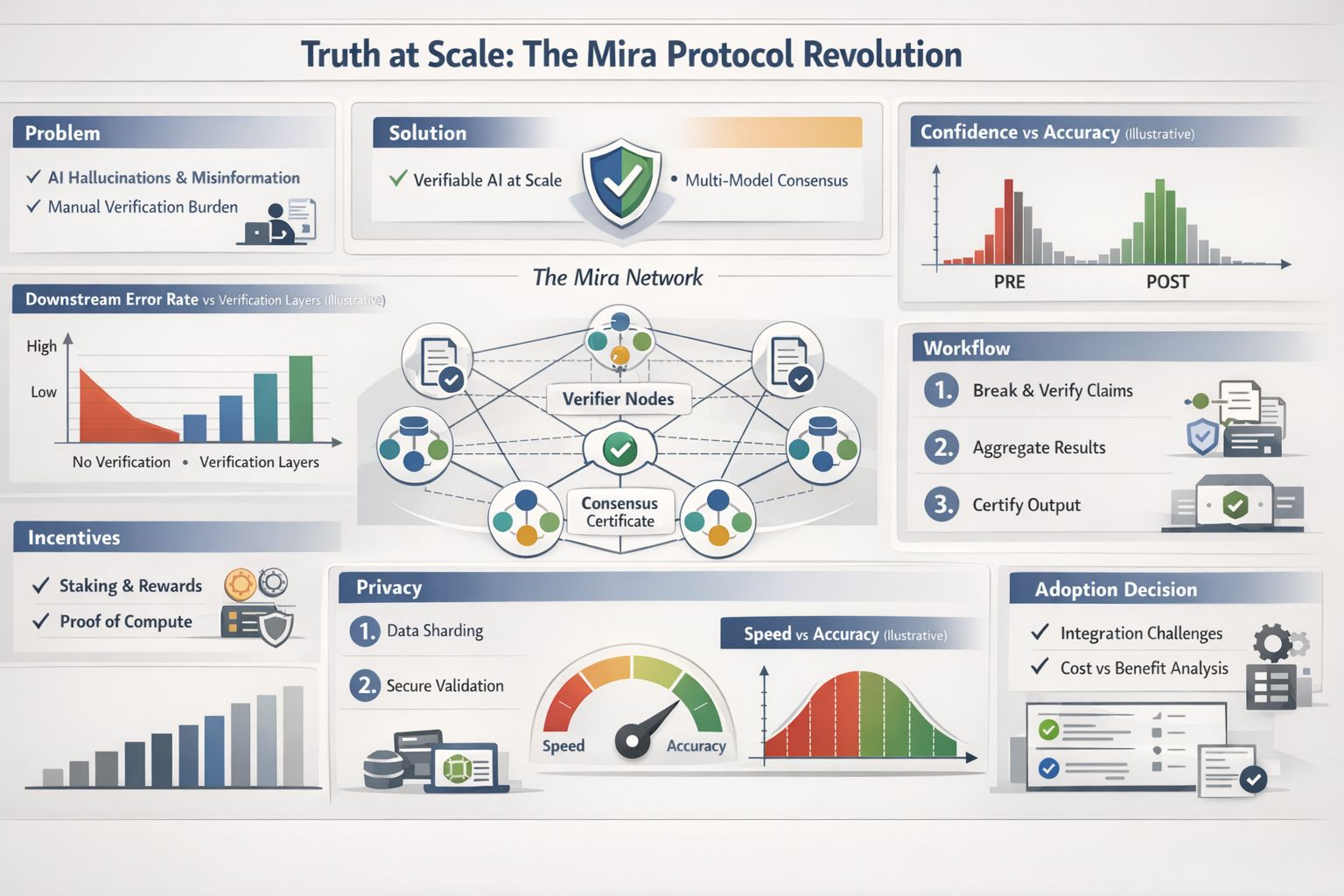
When I read Mira’s whitepaper, I noticed it treats hallucinations as a property of single models, not as a glitch. The core move is straightforward: break an output into separate factual claims, send those claims to different verifier models, and aggregate their judgments into a consensus result. A certificate can then record which models took part and what they concluded.
The “truth at scale” problem isn’t only about accuracy rates; it’s about workflow. I can’t hand-audit every line of a long answer, but I also can’t ignore risk when the content will be reused in a report or a decision. Mira Verify, the developer-facing API, is framed around that tension: multi-model checks plus an auditable trail for each verification. In my world, an audit trail matters because it turns “trust me” into something I can review later.
What holds my interest is how the design takes incentives seriously. The whitepaper describes a hybrid security model that mixes “prove you did real compute” with “stake value you can lose,” and it worries about validators who might guess their way through tasks. That’s not paranoia; it’s just acknowledging that any repeated process will attract shortcuts unless the system makes shortcuts painful.
Privacy is another place where details matter. If I’m verifying something sensitive, I don’t want the full text passed around widely. Mira’s design notes talk about sharding content into smaller pieces so no single node can reconstruct the whole submission, and about keeping verifier responses private until consensus is reached. I treat those as goals, not guarantees, but they’re the right goals.
I’m also aware that “verification” changes meaning depending on what’s being checked. A clean fact like a date or a number is one thing. A claim that depends on context, a legal interpretation, or a value judgment is something else. The moment I split a paragraph into claims, I’m already choosing what counts as checkable. So the most honest early use, to me, is to verify the parts that can be grounded, flag the parts that can’t, and keep humans in the loop.
Mira isn’t alone in using ensembles. Research on model consensus has shown that multiple models validating answers can raise precision in some setups, even while adding cost and latency. It was a good reminder: verification layers have to pay for themselves by catching real errors, not by sounding smart.
Even if Mira works as designed, I still have to decide when verification is worth the delay. Some tasks can tolerate a few extra seconds; others can’t. That choice will actually shape adoption.
Where this gets practical is integration. The Mira Network SDK pitches a single interface across multiple models with routing and load balancing, which is basically an admission that teams already juggle a messy stack. If verification becomes routine, it has to fit into that stack without turning every request into a mini research project. I don’t want a new ceremony; I want fewer surprises and a clear log when something goes sideways.
I’m not ready to treat any protocol as a universal truth machine, and I don’t think that’s the right expectation anyway. What I do take seriously is the idea that reliability can be engineered as a layer, not only trained into a single model. If Mira’s bet works, I’ll spend less time doing frantic last-minute checks and more time deciding what to do with information I can actually defend. The question I’m left with is simple: will the added friction feel like insurance, or will it feel like another tool I quietly stop using?