
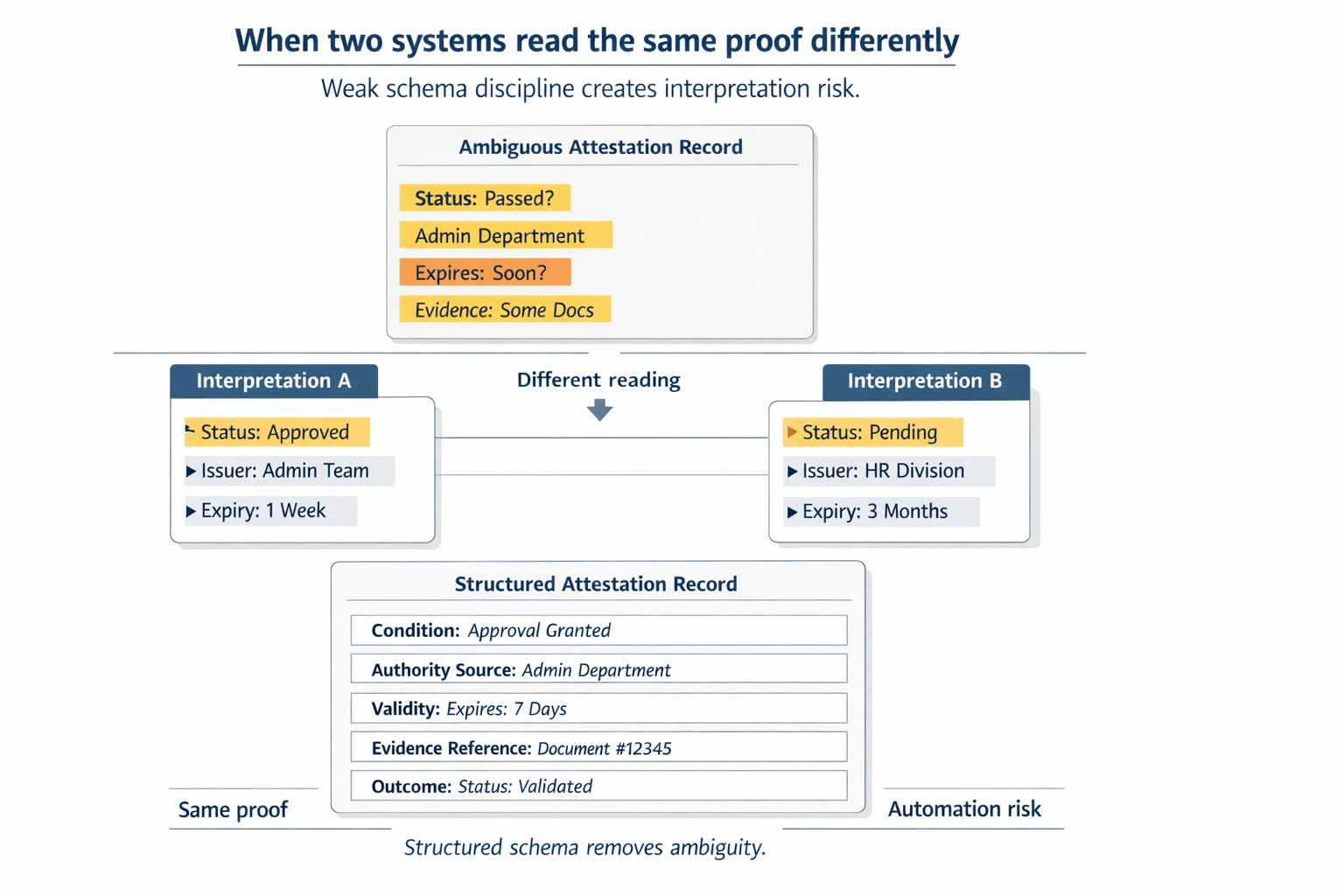
The aspect that continued to lure me back into SIGN was not the signature aspect of it. It was the section immediately preceding that, when a team must make decisions on what is actually being proved, how narrow is that meaning upon being read by other people. I continued to contemplate the fact that many so-called verified systems do not tighten the important part. The record is there, the signature is sound, the hash verifies, but still, two operators may still read the same proof differently, since the fields were too generic, the payload was too flexible, or the app did not force the claim into a format that could survive handoffs. The genuine mess to me seemed to be that.
That is the secret weight I was not able to overcome. Many infrastructure systems consider evidence to be how hard the work starts once the data is stored. I believe that the more difficult failure usually occurs at an earlier place. It occurs when the system allows a claim to be formally recorded in a manner that is operationally soft. approved, eligible, verified, completed, audited, all sound clean until one has to do something real and realizes that the record never narrowed down to a point where it left out any argument. This is the reason that SIGN continues to visit schemas: as it is not cosmetic metadata, but rather the object which stipulates what fields there are, how to encode them, and how to interpret them. When the real money, access or compliance is down-stream, that is a lot larger than it sounds.
One can imagine the workflow in which it begins to hurt painfully. It is a program that is investigating who is fit to get something. The attestation is issued by one team. Another team reads it later. The front end is built very quickly by someone, hence the payload is technically structured but too loose. One of the fields that should have been explicit, is in a free-text string. The record can be found by a verifier, but not compared to be clean. The same claim is read by another operator using a different interface and he arrives at a slightly different interpretation. Then the argument starts. Not whether or not there is the proof, but what the proof actually pledged. When this occurs, human beings begin to populate the gap with judgmental decisions, spreadsheets, screen shots and institutional memory. It is precisely the type of clean up work that causes trust infrastructure to be much less trustworthy in practice.

Then I began to see SIGN getting serious in my mind, as compared to the light pitch of verification. It was not the section where it said you can attest anything. It was the opposite. You must be a good deal more careful what you allow to get attestable in the first place. That is hard pushed by the builder flow of SIGN itself. The schema fields are defined first. The information is likely to be based on such a format. The schema registry provides the verifiers with a stable point of reference of what is expected in the record to mean. And still that is insufficient, there are also schema hooks whereby creation can be verified against other logic and even reverted in case the data or conditions are incorrect. That makes me know that the project realizes that it is not just the issue of authenticity. It is pressurized semantic discipline.
The reason I stuck to that thought was one small piece that continued to haunt me and that is the fact that there is no way to enforce the raw schema by itself and this is where hook logic and validation come in. Such a grotesque fact, that, but that alters the way I read the entire stack. It implies that the protocol is not assuming a schema name will perform magic to interpret the schema. The system offers locations at which the builders can tighten the meaning, feed bad input and prevent weak attestations to enter workflow in the first place. That is what I should like to see instead of sweeping statements, because it is honest where the mess is.
What changed everything was the realization that it is not the question of how we get more proof onchain that is the burden here. It is how can we prevent the poisoning of future decisions by loosely defined proof. After viewing the SIGN subject through that prism, the project seemed more like an anti-ambiguacy layer rather than a verification layer. The records are comparable with the help of the schemas. They can be retrieved in a form that they can be indexed and searched. Hooks allowed builders to reject bad or half baked input rather than inheriting it forever. Such a combination is important since meaning drift is costly. It makes the review slow, undermines automation, and covertly re-introduces critical decisions into human interpretation, where purportedly objective systems begin getting unruly once again.
And it was also the first time that I have found $SIGN more comprehensible in a mechanistic than in a narrative way. The fact that the token is connected to a trust stack does not make it interesting to me. Of interest to me is whether this layer of evidence continues to be utilized in processes where flawed semantics introduce actual cost and more rigid schema and queryable attestation decrease the cost. When the system really is sitting under issuance, verification, replay, and program execution, then the token is important where disciplined evidence manipulation is a repetitively operational activity, and not a demo. That particularly resonates with a CreatorPad campaign in which the site is quite literally prioritizing the quality of project-native content rather than encouraging the generic explanation. The structure itself inclines to sharper and more precise reading as compared to general feature summary, which is the reason why this more limited load becomes important in this case.
I have not yet gotten completely relaxed about it and this is one of the reasons why it is worth viewing. My pressure test is the existence of schema discipline in the face of real builders becoming lazy, accelerated or attempts to squeeze messy business logic into technically but semantically invalid fields. Are hooks and validation frequently used, or do teams continue to pass ambiguity to free-form payloads because it is convenient to do so? Does the common schema layer truly generate similar records amongst the organizations or are all apps created speaking Sign in its own dialect? Then when we enter into the world of private, hybrid, and off-chain payload models, can the system continue to maintain interpretation to the extent that downstream automation can be assured to be reading what it is? Such are the questions which make more of a difference to me than whether the signature is verified.
Since the ugliest failure is not a counterfeit evidence.
It is an actual evidence that was not sufficient enough.
@SignOfficial #SignDigitalSovereignInfra $SIGN