At first, the phrase “AI blockchain” can feel a bit crowded. We have heard a lot of big words around AI, crypto, data, ownership, agents, models, and so on. After a while, some of it starts to sound the same. So I think it helps to slow down and ask a simpler question.
What is actually being tracked here?
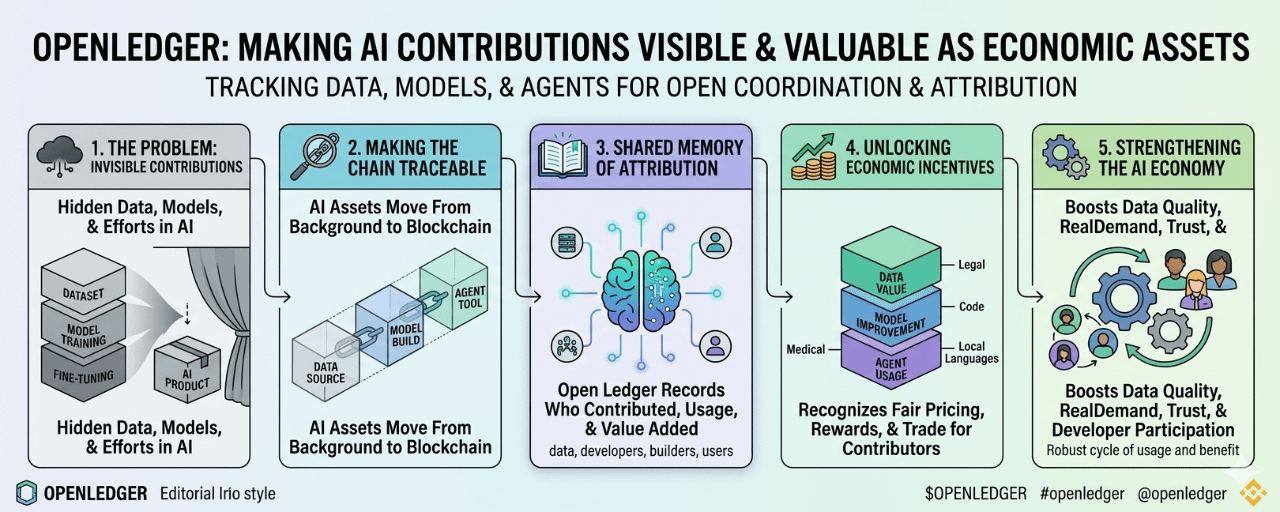
In AI, so much value begins before anyone sees the final product. It starts with data. It comes from people who create, label, organize, clean, or provide useful information. It comes from builders who train models. It comes from developers who shape those models into tools, apps, or agents that people can actually use.
But in most systems today, that chain is hard to see.
You can usually tell when an AI product is useful. You can see the output. You can feel the convenience. But it is much harder to know what went into it. Where did the data come from? Who contributed to the model? Which part added real value? Who should be rewarded when that value keeps being used?
That’s where things get interesting with OpenLedger.
The idea seems to be about making AI contributions more visible and more usable as economic assets. Not just data sitting somewhere. Not just models locked inside closed systems. Not just agents running tasks without any clear connection to the people or resources behind them.
Instead, OpenLedger tries to place these pieces on a blockchain-based system where contribution, usage, and attribution can be recorded more openly.
That sounds technical, but the basic thought is pretty human.
If something helps create value, there should be a way to recognize it.
This is especially important because AI does not grow from nothing. A model is never just a model. It carries traces of the information used to train it, the choices made by developers, the fine-tuning done for specific tasks, and the tools built around it. In many cases, the final output hides all of that work.
And when work becomes invisible, value usually flows in only one direction.
OpenLedger seems to be looking at that problem from a different angle. The question changes from “who owns the final AI product?” to “how do we track the many layers that helped create it?”
That is a quieter question, but maybe a more useful one.
Data, models, and agents are becoming important parts of the AI economy. But they are not always easy to price, trade, or reward fairly. A dataset may be useful only in a certain field. A model may become more valuable after it is trained on expert information. An agent may perform a task well because it depends on several hidden layers underneath.
So the value is there, but it can be difficult to measure.
OpenLedger’s approach is to make these AI assets more traceable. If a dataset is used, that use can be connected back to its source. If a model is trained or improved, that process can be recorded. If an agent depends on certain models or data, those links can become part of the system instead of being lost in the background.
It becomes obvious after a while that this is not just about storage or transactions. It is about memory. A shared memory of contribution.
That matters because AI is moving toward more specialized tools. Not every useful model needs to be huge or general. Some models are valuable because they understand a narrow area well. Medical research, legal documents, finance, code, local languages, industry data — these areas often need focused knowledge.
And focused knowledge usually comes from specific contributors.
If those contributors are ignored, the system becomes weaker over time. People may not want to share high-quality data if they have no way to benefit from it. Builders may not want to improve models if their work disappears into someone else’s product. Users may not fully trust AI systems if the path behind the output is unclear.
OpenLedger seems to be trying to connect these loose ends.
Not in a perfect way, of course. These are still early ideas, and the real test is always in use, not in descriptions. Systems like this have to prove that they can attract real data, real developers, real demand, and real usage. They also have to make the experience simple enough that people do not feel like they are managing infrastructure just to contribute something useful.
That part is important.
Because most people do not care about the chain itself. They care about whether their work can be used, whether they can trust the system, and whether value returns to the right places.
Still, the pattern is worth noticing.
AI is becoming more powerful, but also more concentrated. Blockchain, at its best, is about shared records and open coordination. OpenLedger sits somewhere between those two worlds. It is trying to ask whether data, models, and agents can move through a more transparent system, where contribution does not vanish once the AI starts producing outputs.
Maybe that is the real point.
Not just monetizing data. Not just putting AI on-chain. Those phrases can feel too clean.
The deeper idea is about making hidden work visible enough to matter.
And if AI keeps becoming part of everyday tools, that question will probably keep coming back in different forms. Who contributed? Who benefits? What gets remembered? What gets lost?
OpenLedger is one attempt to answer that, or at least to build around it.
The rest will depend on whether people actually find value in using it, slowly, over time…
@OpenLedger #OpenLedger $OPEN
مقالة
OpenLedger makes more sense when viewed as more than a blockchain.
إخلاء المسؤولية: تتضمن آراء أطراف خارجية. ليست نصيحةً مالية. يُمكن أن تحتوي على مُحتوى مُمول. اطلع على الشروط والأحكام.