OpenLedger exists in a part of crypto that is still very early, but also very important. Most discussions around AI and blockchain focus on speculation, trading, or the idea that artificial intelligence will somehow “merge” with Web3 in the future. OpenLedger approaches the problem from a different direction. Instead of treating AI as a simple application running on top of crypto, it treats AI as an economic system that needs coordination, ownership, settlement, incentives, and accountability.
That distinction matters more than it first appears.
Today, the global AI industry is heavily centralized. Large technology companies collect massive amounts of data, train models behind closed systems, and monetize the outputs at enormous scale. The people who create the raw value inside these systems often receive nothing. Data contributors are invisible, model trainers are dependent on platform rules, and users have almost no transparency into how outputs are generated. The AI economy functions more like a closed supply chain than an open network.
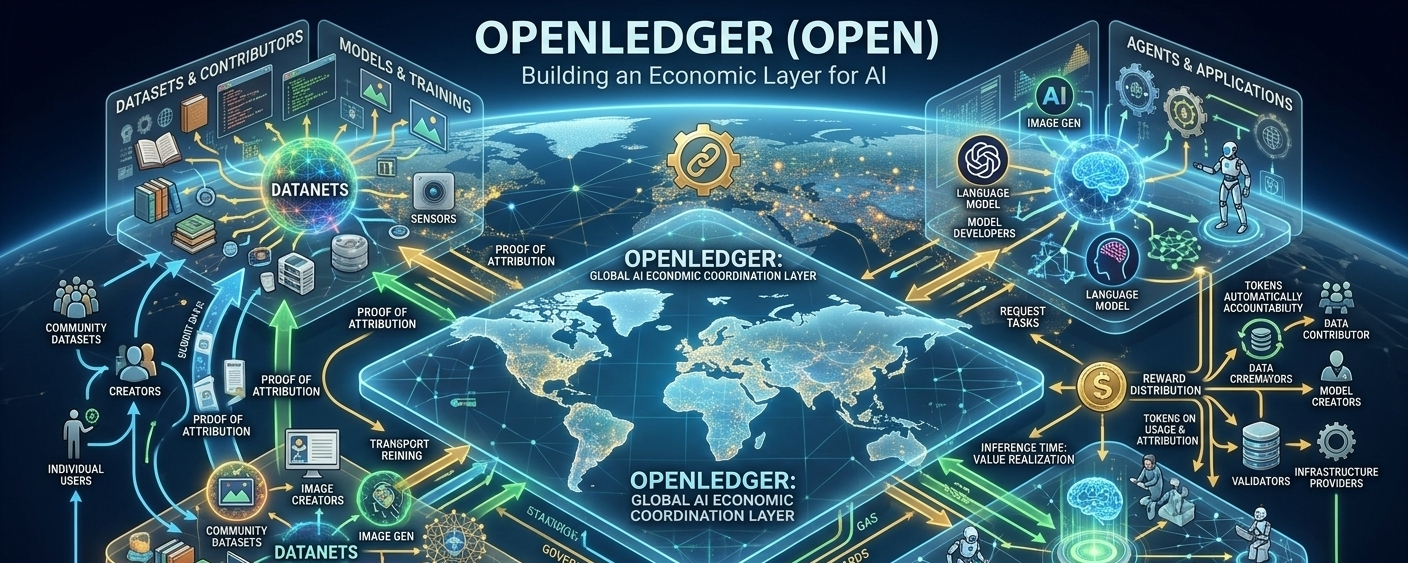
OpenLedger is trying to redesign that structure by placing attribution and settlement directly into blockchain infrastructure. The idea is simple to explain, even if the implementation is difficult. If data helps train a model, and that model later generates economic value, the contributors to that intelligence should be identifiable and rewarded. Instead of AI existing as a black box, OpenLedger wants AI systems to behave more like transparent economic networks where participation, contribution, and ownership can be measured over time.
This changes the role of blockchain inside AI. In many crypto projects, blockchain is mainly used for trading tokens or recording transactions. In OpenLedger, blockchain becomes a coordination layer for intelligence itself. The network records who contributed data, which models were trained from that data, how those models are used, and where value flows after inference occurs. In simple terms, inference means the moment an AI model actually answers a question, generates content, or performs a task for a user.
That moment is economically important because it is where value becomes real. Most AI systems today only reward the platform owner at inference time. OpenLedger attempts to split that value between infrastructure providers, model creators, data contributors, validators, and other participants involved in the lifecycle of the model. The network calls this process “Proof of Attribution,” which is one of the central ideas behind the project.
The deeper reason this matters is because AI is becoming dependent on increasingly large pools of data, compute resources, and human interaction. As models grow larger, the question is no longer only about creating intelligence. The question becomes who owns the economic rights surrounding that intelligence. Most internet users contribute to AI systems every day without compensation. Search activity, conversations, uploaded media, behavioral patterns, and feedback loops continuously improve centralized AI products. Yet the economic rewards remain concentrated at the platform level.
OpenLedger tries to create a different structure where data behaves more like productive capital. Instead of remaining trapped inside corporate silos, datasets can become reusable economic assets inside decentralized markets. This concept is sometimes described as “data liquidity,” but underneath that phrase is a broader economic idea. Liquidity is not only about trading. It is about making previously locked resources usable across systems. OpenLedger is effectively trying to make intelligence composable in the same way decentralized finance made capital composable.
The project introduces something called “Datanets,” which are shared datasets contributed and maintained by communities or organizations. These datasets can then be used to train specialized AI models. The important part is that contribution history and attribution remain attached to the data itself. That means when models generate value later, the network can theoretically trace which datasets contributed to the output and distribute rewards accordingly.
From a systems perspective, this is extremely ambitious because attribution inside AI is difficult. Modern AI models are complex statistical systems with billions of parameters interacting at once. Determining exactly which data point influenced a particular output is not straightforward. OpenLedger’s attempt to solve this through blockchain based attribution is one of the most important parts of the project, but also one of its greatest technical risks.
If attribution systems fail, the entire economic structure weakens. Contributors will not trust reward mechanisms if they believe payouts are inaccurate or manipulable. This is one of the hidden realities of decentralized AI. Many projects can launch tokens and marketplaces, but very few can reliably measure value creation across distributed intelligence systems. OpenLedger’s long term survival depends less on marketing and more on whether its attribution layer can remain credible under real economic pressure.
The OPEN token sits at the center of this coordination system. According to the project’s token documentation, OPEN is used for network gas, governance, inference payments, model deployment, and attribution rewards. The total supply is capped at one billion tokens, with a large portion allocated toward community and ecosystem participation over multiple years.
What matters more than the supply number itself is how the token connects incentives across the network. In many crypto systems, tokens exist mainly for speculation. In OpenLedger, the token is attempting to represent economic coordination between multiple groups that would normally operate separately. Data providers want compensation, model developers want monetization, validators want fees, users want useful AI services, and the network itself requires sustainable infrastructure funding. The token becomes the accounting mechanism linking all these actors together.
This creates a more complex economy than traditional Layer 1 blockchains. In a normal blockchain, users mostly pay for transaction execution and security. In OpenLedger, payments may need to support model inference, data attribution, compute resources, staking systems, governance decisions, and cross application interactions simultaneously.
One interesting aspect of the project is its focus on AI agents. AI agents are autonomous systems capable of performing tasks without constant human instruction. In theory, these agents could interact with applications, use services, generate outputs, or even transact economically. OpenLedger introduces staking mechanisms tied to these agents, meaning operators may need to lock tokens as a form of accountability.
This is an important design decision because autonomous systems create new coordination problems. If AI agents become economically active, networks must determine how reliability, trust, and punishment operate. Traditional software does not usually require economic collateral to function. But decentralized systems often rely on staking because open networks cannot assume trust between participants. OpenLedger is effectively applying blockchain security logic to AI behavior itself.
The broader crypto industry has already explored similar coordination structures in decentralized finance, where staking and slashing mechanisms help maintain honest behavior among validators. OpenLedger extends that logic toward machine intelligence. Whether this model succeeds remains uncertain, but it reflects a deeper trend inside Web3, where networks are increasingly trying to govern not only financial activity but also information systems and autonomous computation.
Another important part of OpenLedger is interoperability. The project appears designed to operate across Ethereum compatible infrastructure while supporting bridges and broader ecosystem integrations. This matters because isolated AI chains would struggle to survive long term. AI economies require liquidity, users, datasets, applications, and external demand. Networks that cannot connect to broader ecosystems often become economically stagnant.
OpenLedger therefore sits inside a larger movement toward decentralized infrastructure for AI. Projects like Bittensor, Render, and Artificial Superintelligence Alliance are also attempting to decentralize parts of the AI stack, whether compute, model coordination, or machine intelligence marketplaces. What makes OpenLedger somewhat different is its strong focus on attribution and settlement rather than pure compute markets.
That distinction is critical because the future AI economy may depend less on raw intelligence and more on trusted coordination between contributors. The internet already has enough information. The harder problem is determining ownership, permission, reliability, and economic distribution across increasingly autonomous systems.
Still, the project faces serious challenges.
The first challenge is technical scalability. AI systems consume enormous computational resources. Recording too much activity directly on-chain can become inefficient and expensive. OpenLedger therefore needs to balance transparency with practical throughput. Many blockchain systems struggle under heavy transactional load even without AI level complexity.
The second challenge is attribution accuracy. As mentioned earlier, proving exactly how data contributes to model outputs is an unsolved problem at scale. If attribution becomes too vague, reward systems may drift toward unfairness or centralization.
The third challenge is data quality. Open systems attract both honest and malicious participants. If contributors upload low quality, manipulated, copyrighted, or poisoned data, models can degrade rapidly. OpenLedger must therefore maintain incentive structures that reward useful data while discouraging spam and abuse. This is harder than it sounds because AI systems are highly sensitive to training quality.
The fourth challenge is economic sustainability. Many crypto projects distribute large token rewards during early growth phases, but struggle once speculative attention fades. OpenLedger’s long term viability depends on whether real demand for AI inference and decentralized datasets emerges at sufficient scale. If usage remains low, token incentives alone may not sustain the ecosystem.
The fifth challenge is regulation and legal uncertainty. AI data ownership is becoming politically sensitive worldwide. Governments are increasingly examining copyright, consent, identity, and training transparency in AI systems. OpenLedger operates directly in the middle of these debates because it attempts to tokenize and monetize data contribution itself. Future regulations around AI datasets could significantly impact decentralized AI networks.
There is also a philosophical risk that many people underestimate. Open systems are not automatically fair systems. Blockchain can improve transparency, but transparency alone does not solve concentration of power. Large token holders, dominant model developers, or wealthy compute providers could still accumulate disproportionate influence over network governance and economic flows. The project therefore faces the same long term governance questions that affect most decentralized systems.
Despite these risks, OpenLedger represents something larger than a single token or blockchain. It reflects an important shift happening across the internet economy. For years, crypto focused mainly on decentralized money. Now the industry is slowly moving toward decentralized coordination of computation, identity, information, and intelligence.
This transition matters because AI is becoming infrastructure. It is no longer just software. AI increasingly shapes search results, communication, financial systems, content generation, productivity tools, and decision making processes. As intelligence becomes embedded into everyday systems, the economic rules governing AI become more important than the models themselves.
That is ultimately where OpenLedger becomes interesting.
The project is not simply asking whether AI can run on blockchain. It is asking whether intelligence itself can become economically accountable inside open systems. That is a much deeper question.
If future AI economies remain completely centralized, most value creation will continue flowing toward a small number of platforms controlling data and computation. But if decentralized coordination systems become viable, intelligence may evolve more like public infrastructure, where contributors, operators, and users share economic participation across open networks.
Whether OpenLedger succeeds or fails, the problem it is trying to solve is real. AI already depends on invisible labor, hidden data extraction, and opaque ownership structures. Those tensions will only grow as AI systems become more autonomous and economically important.
Under real world stress, during periods of market instability, political pressure, infrastructure failures, or concentrated platform control, systems with transparent coordination and resilient incentive structures tend to survive longer than systems dependent on blind trust. OpenLedger is attempting to build that kind of coordination layer for AI. The difficult part is not launching the network. The difficult part is proving that decentralized attribution, settlement, and economic accountability can continue functioning when incentives become large enough for participants to exploit the system
That is the real test for decentralized AI, and it is the reason projects like OpenLedger matter far beyond short term narratives or token prices.