Hôm qua mình đang lọc danh sách AI blockchain để tìm chỗ để tiền. Không phải nghiên cứu học thuật, không phải vì đam mê công nghệ. Đơn giản là thị trường đang xanh, narrative AI x crypto đang nóng, và mình không muốn bị bỏ lỡ.
OpenLedger xuất hiện trong danh sách. Mình mở whitepaper ra với thói quen cũ: đọc tokenomics trước, xem allocation có đẹp không, rồi đóng lại.
Nhưng lần này mình lỡ đọc trúng trang có công thức toán học.
Phản xạ đầu tiên là lướt qua. Cái cảm giác quen thuộc: đây chắc là phần để dự án trông "legit," không ai đọc thật đâu. Nhưng mình dừng lại vì nhận ra một điều khác. Toàn bộ mô hình kinh tế của OpenLedger, gồm rewards, incentives, ai được trả tiền bao nhiêu, đều phụ thuộc vào một con số duy nhất mà whitepaper ký hiệu là I(di, y). Nếu con số đó sai, mọi thứ phía sau sai theo.
Vậy họ tính con số đó như thế nào?
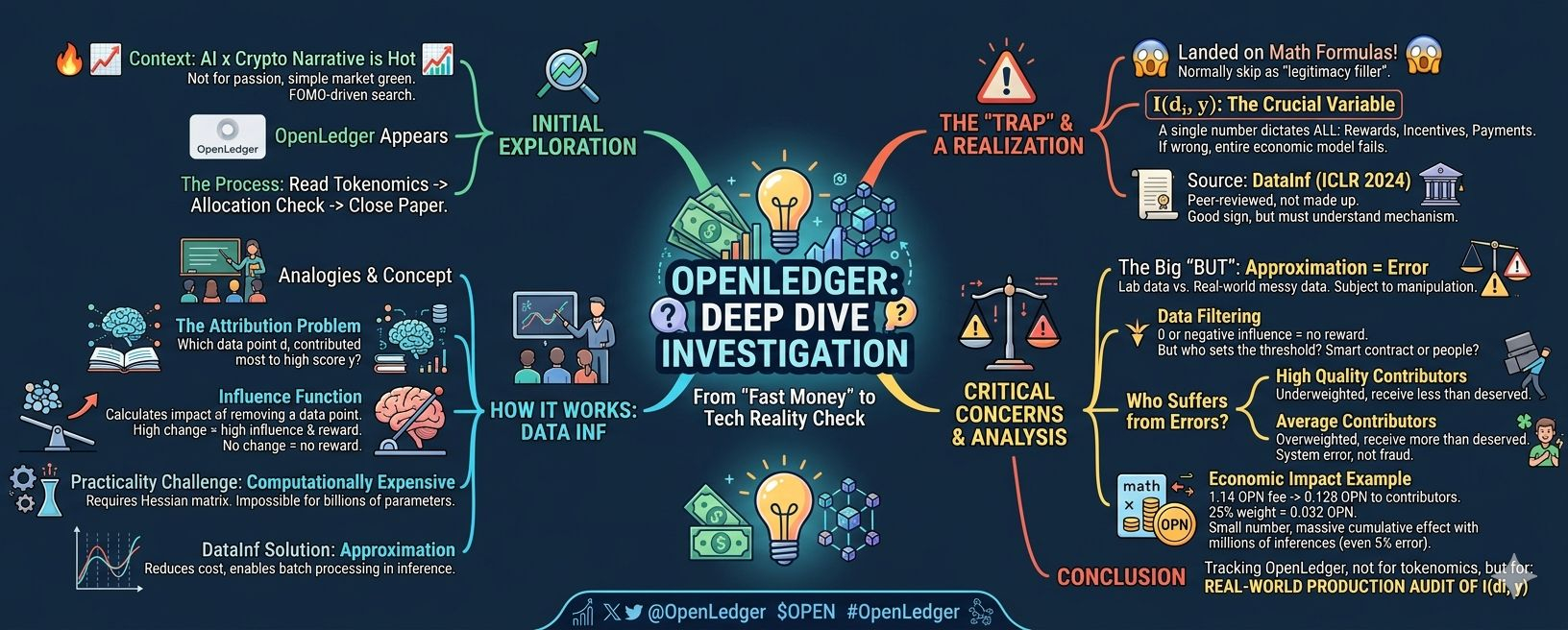
OpenLedger dùng một phương pháp gọi là influence function, cite từ paper DataInf công bố tại ICLR 2024. Ý tưởng không phải của họ tự phát minh, đây là nghiên cứu học thuật đã được peer-review. Đó là điểm cộng, không phải điểm trừ. Nhưng hiểu cơ chế vẫn quan trọng trước khi để tiền vào bất cứ đâu.
Hãy hình dung thế này. Bạn đang dạy một học sinh. Mỗi ngày bạn cho học sinh đó đọc một tài liệu khác nhau. Sau một tháng, học sinh thi đạt 90 điểm. Câu hỏi là: trong 30 tài liệu đó, tài liệu nào đóng góp nhiều nhất vào kết quả 90 điểm ấy?
Đây chính xác là bài toán attribution trong AI. Model được train trên hàng triệu data points. Khi nó trả lời một câu hỏi, câu trả lời đó bị ảnh hưởng bởi vô số inputs từ quá khứ. Influence function cố gắng lượng hóa điều đó: nếu bỏ data point di này ra, output của model thay đổi bao nhiêu? Nếu thay đổi nhiều, di có influence cao và người đóng góp di được trả nhiều hơn. Nếu gần như không thay đổi, di gần như không đóng góp gì và nhận về gần bằng không.
Vấn đề là tính toán này cực kỳ tốn kém. Phương pháp gốc cần tính ma trận Hessian, chi phí tăng theo bình phương số lượng tham số của model. Với model hàng tỷ parameters, đây là bất khả thi trong thực tế. DataInf giải quyết bằng cách xấp xỉ, giảm chi phí xuống mức có thể chạy được theo batch. OpenLedger áp dụng xấp xỉ này để tính attribution trong quá trình inference.
Vẫn nghe ổn. Nhưng đây là chỗ mình dừng lại lâu nhất.
Xấp xỉ có nghĩa là sai số. Sai số có thể nhỏ với model tiêu chuẩn trong điều kiện lab. Nhưng trong thực tế, data trên OpenLedger đến từ nhiều nguồn khác nhau, chất lượng không đồng đều, và hoàn toàn có thể bị manipulate có chủ đích. Whitepaper nêu rằng data points với influence score bằng 0 hoặc âm sẽ không nhận rewards, đây là cơ chế lọc data xấu. Nhưng ngưỡng đó ai đặt ra? Smart contract tự động hay có người can thiệp?
Và câu hỏi thật sự quan trọng: nếu influence score bị tính lệch, ai chịu thiệt?
Người đóng góp data chất lượng cao nhưng bị underweight sẽ nhận ít hơn thực tế họ xứng đáng. Người đóng góp data tầm thường nhưng tình cờ được overweight sẽ nhận nhiều hơn. Không ai gian lận. Hệ thống chỉ đang đo sai.
Với ví dụ cụ thể trong whitepaper, một inference request tạo ra 1.14 OPN phí tổng, trong đó 0.128 OPN phân phối về phía contributors. Một người đóng góp có weight 25% nhận 0.032 OPN cho một lần inference. Con số nhỏ, nhưng nhân lên với hàng triệu inference mỗi ngày, sai số attribution dù chỉ 5% cũng tạo ra chênh lệch kinh tế tích lũy rất lớn theo thời gian.
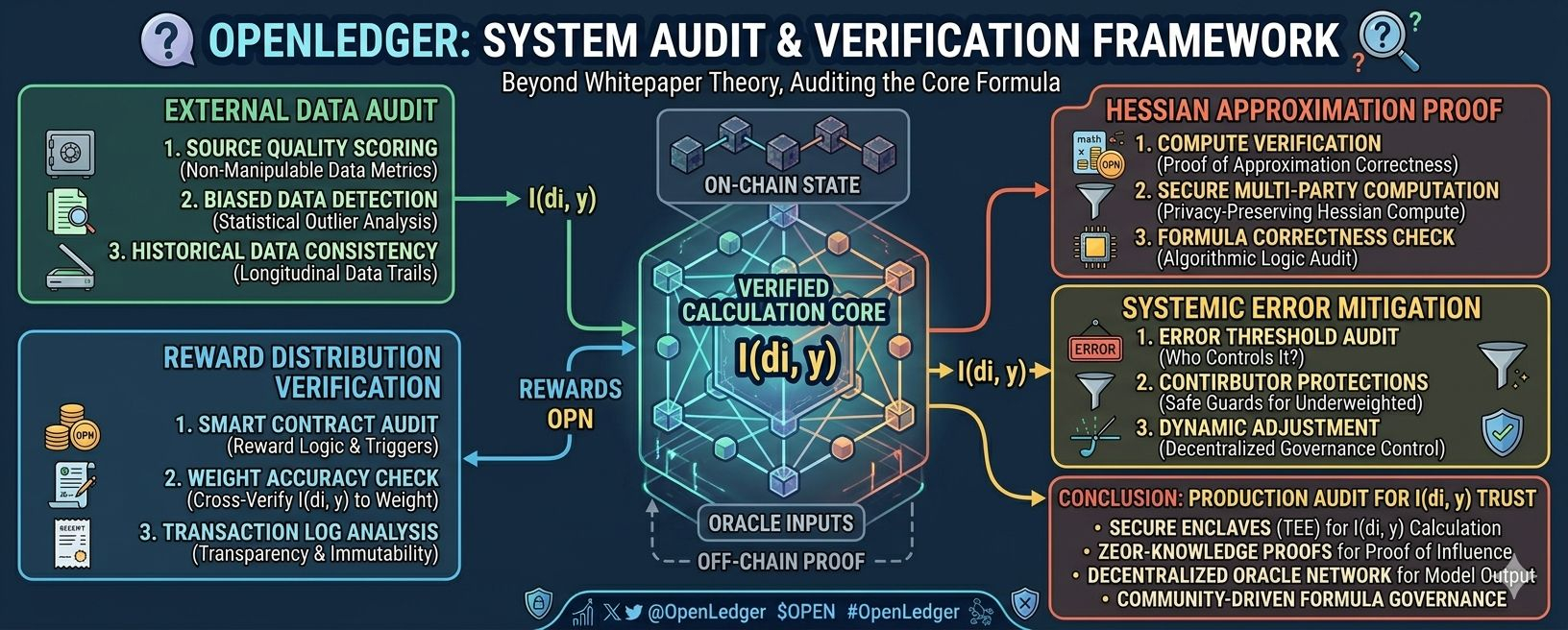
Mình vẫn đang theo dõi OpenLedger. Nhưng không phải vì tokenomics đẹp.
Mình đang chờ xem ai là người audit cơ chế tính I(di, y) trong môi trường production thật, không phải trong whitepaper.