
其实仔细想想,现在的年轻人为什么不爱买现成的精装房,反而沉迷于去宜家买一堆模块化家具回家自己组装?这事儿有点意思。因为大家要的,往往就是那种我知道这个螺丝钉是我自己拧上去的确定性和掌控感
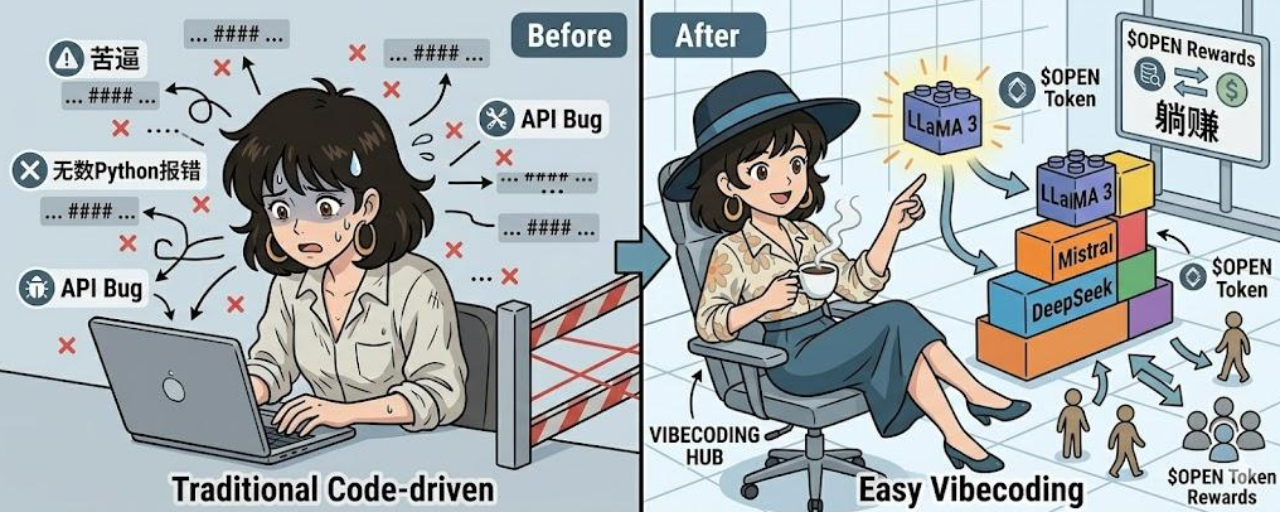
把这套逻辑搬到 AI 圈,就是最近海外特热的 Vibecoding 概念,全凭感觉和需求去构建,别整那些虚的。
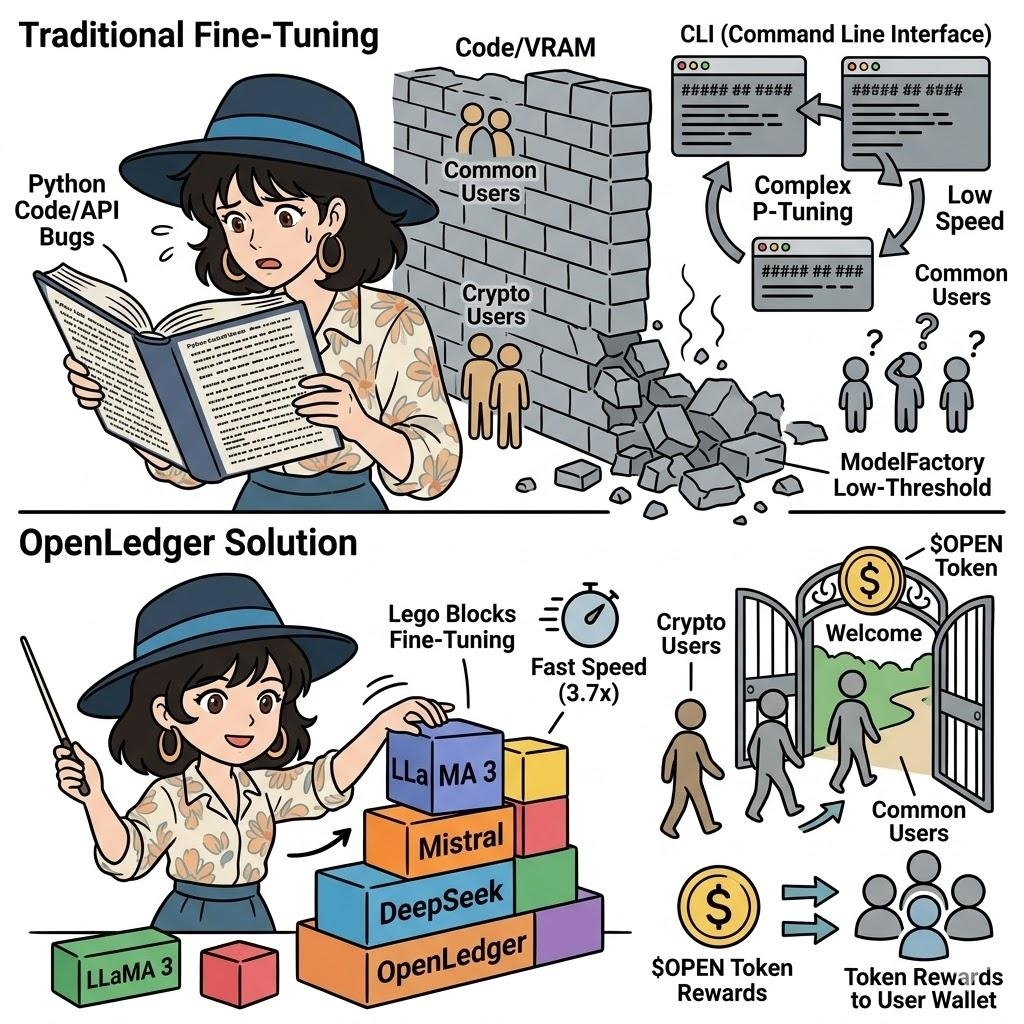
我当时第一反应是,这不就是给咱们散户和撸毛党量身定做的吗?过去一听到模型微调,脑子里出现的画面就是密密麻麻的 Python 命令行和改不完的 API Bug,瞬间被劝退。但当我翻完 OpenLedger 的白皮书,我越看越觉得,这次 ModelFactory 搞的无代码微调,真的有点颠覆
说白了,传统的微调方法像 P-Tuning 之类的,不仅慢,还特别吃资源,普通人根本玩不起。而 ModelFactory 搞了个全图形界面(GUI-only),直接把 LLaMA 3、Mistral、DeepSeek 这些圈内顶流模型做成了乐高模块。你不需要懂代码,动动鼠标就能上手微调
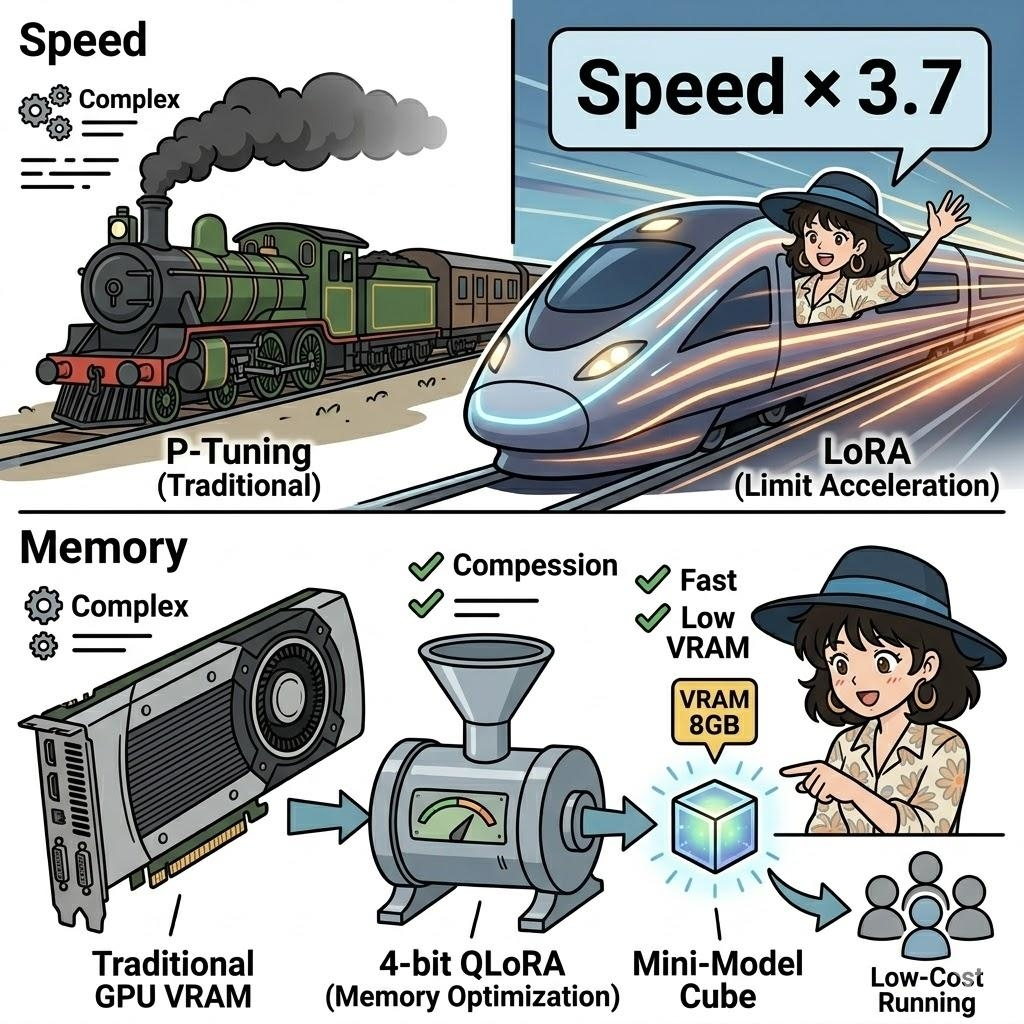
更绝的是它的速度。在 LoRA 技术的加持下,它的训练速度比传统 P-Tuning 快了整整 3.7 倍!这波操作简直就是把绿皮火车换成了高铁
而且大家不用担心显存爆炸,因为它用上了 4-bit 量化的 QLoRA 技术,把 GPU 内存优化到了极致。这意味着,以前需要烧掉几万块显卡的大模型,现在用极低的成本就能跑起来。
不过我觉得,最让人安心的还是它的底层逻辑。很多小模型微调完就像个黑盒,谁也不知道它到底吸收了什么数据。
但 OpenLedger 在它的 Research 论文里抛出了一个杀手锏,闭式影响近似(Closed-Form Influence Approximation)。简单理解就是,它能在极小的 LoRA 参数空间里,用几秒钟的时间就精准算出来某一条数据对模型的贡献
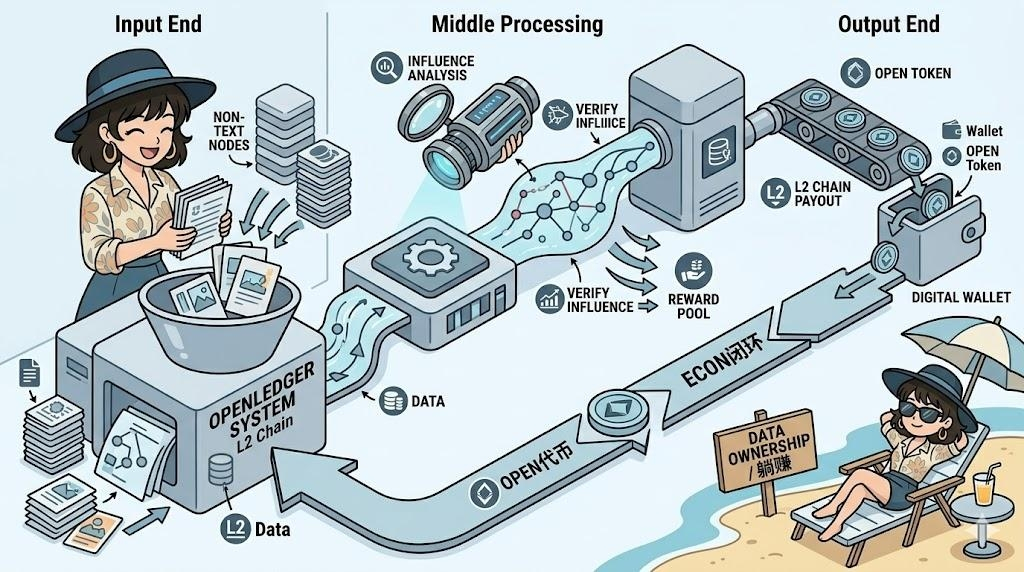
这就像是你做了一道菜,它能瞬间帮你查出来,到底是哪一克盐让这道菜变好吃的。这种 token 级别的透明度,直接把数据变成了能生钱的资产

这时候就不得不提 OPEN 代币的含金量了。在这套生态里,你贡献了数据,系统查出有贡献,直接就会通过 L2 链上把 OPEN 代币作为奖励派发到你钱包里。不管是做任务还是提供垂直领域的语料,只要你的数据被模型吸收并产生了作用,就能持续躺赚。这波经济闭环,算是把数据所有权的饼给真正落了地。
最后我想说,AI 发展到今天,红利不该只被大厂垄断。OpenLedger 这次把大模型微调的门槛直接砍到了地平线,就是想告诉大家,不要过度思考,开始构建就完了。全凭感觉的 Vibecoding 时代已经来了,上车搞个专属自己的 AI 工具,或许才是这轮周期最清醒的打法