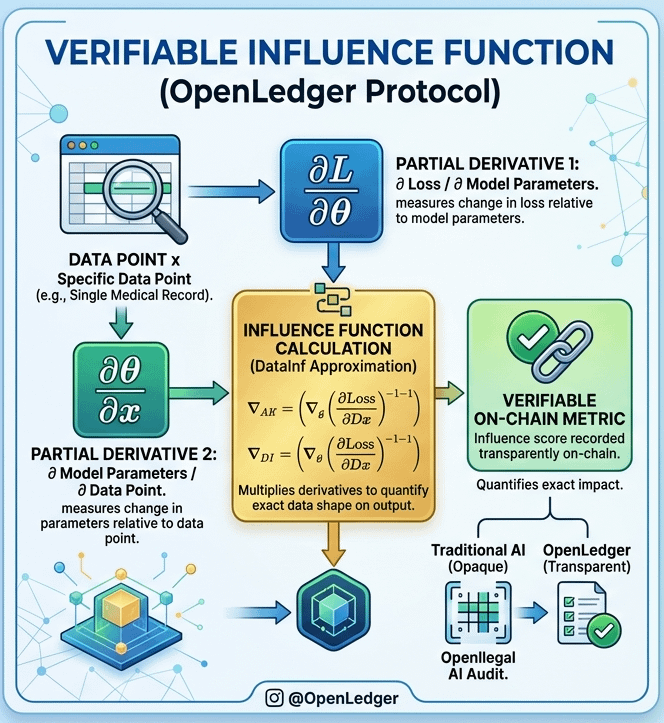
When i first looked into @OpenLedger i expected to see just another blockchain protocol but what truly caught my attention was the mathematics quietly embedded in its whitepaper. buried in the technical documentation is an influence function that multiplies two partial derivatives: the change in loss relative to model parameters and the change in those parameters relative to a specific data point. Individually they measure standard optimization dynamics but when i traced how they work together i realized they produce something the internet has never reliably delivered: a verifiable Onchain metric that quantifies exactly how much a single data point actually shaped a model’s output.
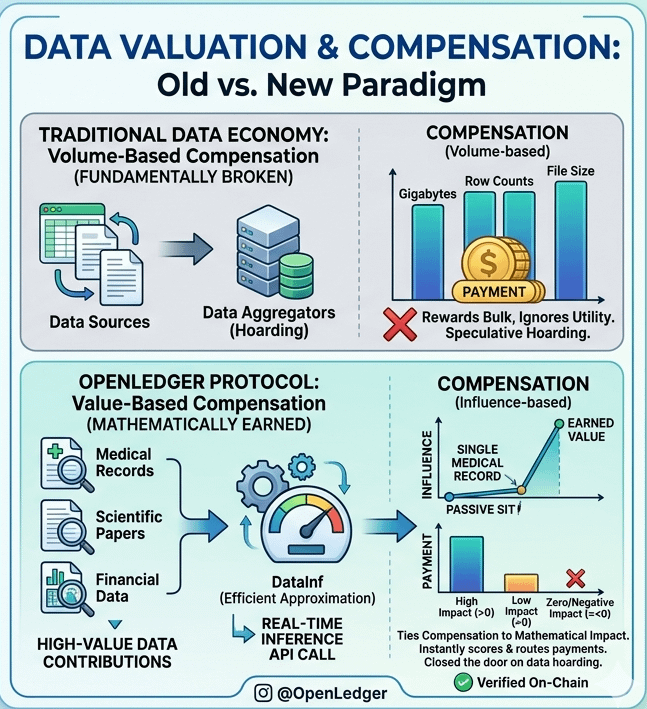
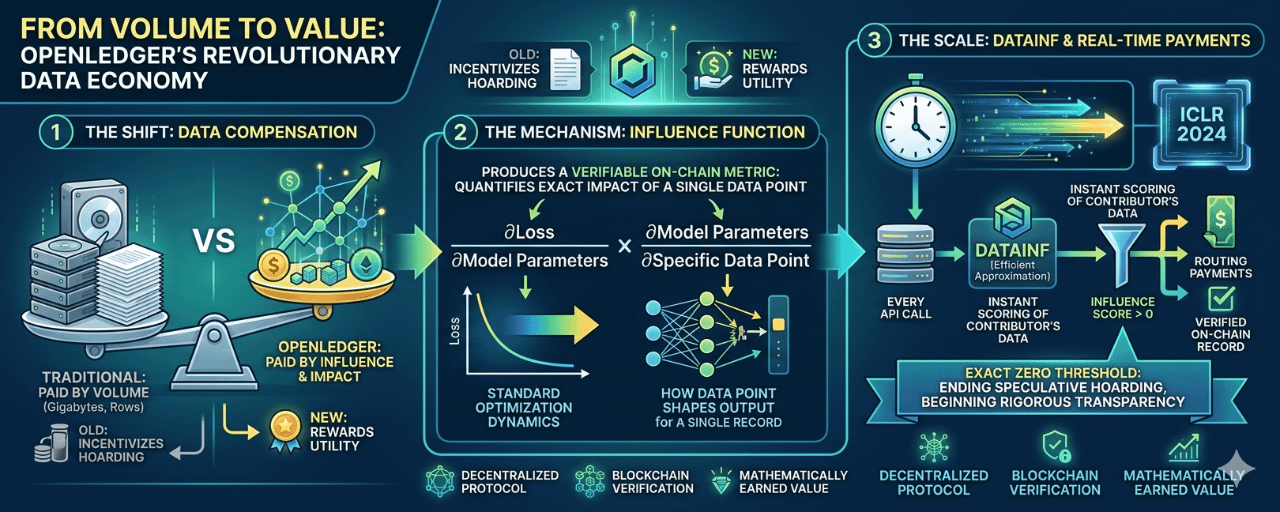
i have spent years watching the data economy operate on a fundamentally broken premise where contributors are compensated strictly by volume rather than value. Pricing datasets by gigabytes row counts or file size feels remarkably like paying writers by the pound rewarding bulk while ignoring actual utility. OpenLedger completely upends this by tying compensation directly to mathematical impact. i find it compelling that under this model a single medical record wouldn’t just be paid for sitting passively in a training set instead it earns value only when it provably shifts a model’s predictions with every contribution verified and recorded Onchain.
to make this theoretically elegant concept practically viable the protocol integrates DataInf an efficient approximation framework published at ICLR 2024 that scales influence calculations to real time inference. from my observation the system triggers this computation with every API call instantly scoring each contributor’s data and routing payments only to those whose influence scores remain above zero. i believe that exact zero threshold marks a definitive turning point finally closing the door on an era of speculative data hoarding and opening one where value is rigorously transparent and mathematically earned.