My name is Lamiya. When I think about how artificial intelligence learns from human-created content, something doesn’t feel right. People spend hours writing, creating, designing, researching, and sharing their work online.... Then big AI systems use that information, but almost no one ever gets credit for what they made. It feels unfair because those creators should be acknowledged and rewarded when their ideas help powerful tools become smarter. That’s why the whole idea of data attribution matters so much to me.
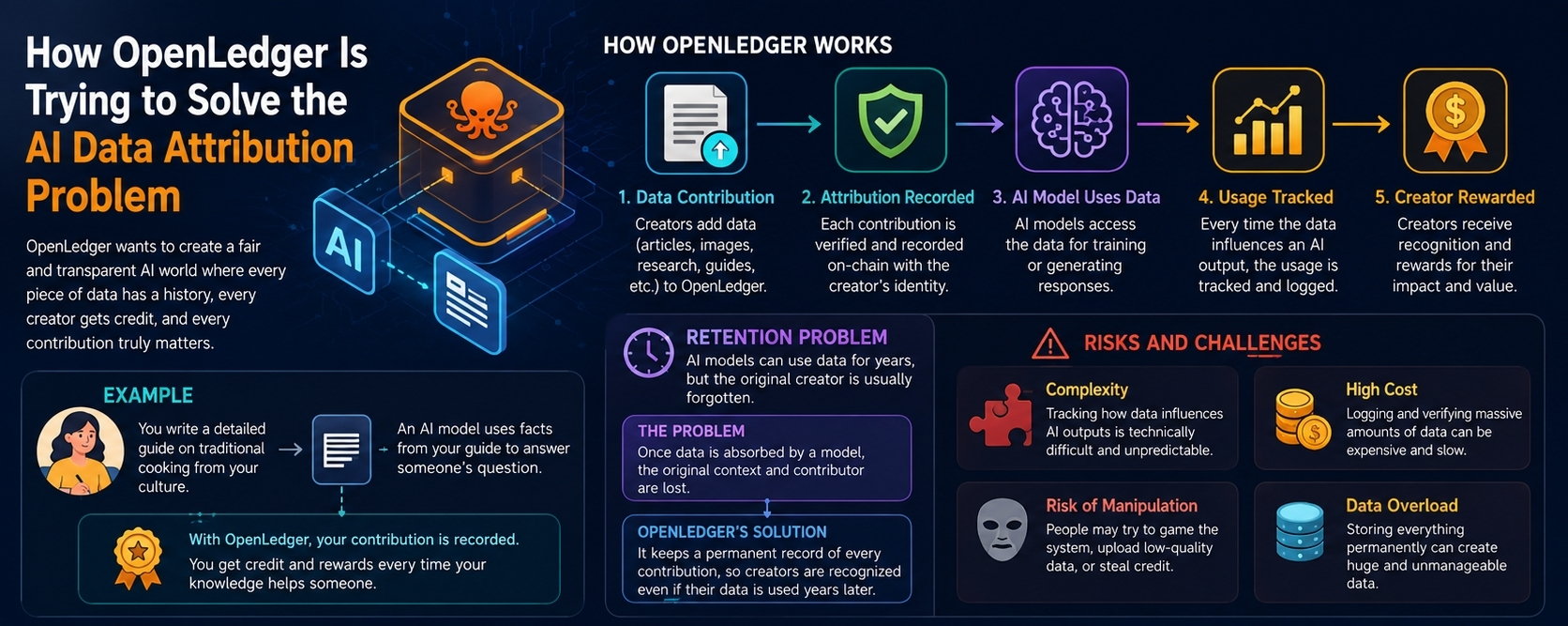
OpenLedger is one of the efforts trying to fix this big fairness problem in AI. Instead of letting AI systems pull information from the world with no record of who made it, OpenLedger wants to build a system where every piece of data used by AI has a clear history attached to it... That means when an AI model uses someone’s knowledge, you can trace it back and see exactly who shared that piece of information. The hope is that this will make AI more fair and transparent, so creators are not invisible but instead acknowledged and rewarded.
At the center of OpenLedger’s idea is something they call attribution tracking. Imagine a huge library of data where each book has the author’s name, proof that they wrote it, and a record of what the book has been used for... That’s basically what OpenLedger is trying to build for AI data. Anyone can contribute data to these structured collections, and every contribution gets recorded in a way that cannot be changed later. When an AI model learns from that data or uses it to generate a result, the system can say exactly which data points helped shape that answer and who created them.
A real-life example might help make this clear. Let’s say you wrote a detailed guide about traditional cooking techniques from your culture and shared it online. In today’s AI world, a large model could read your guide, pull facts from it, and include that knowledge in answers to someone’s questions, but no one would ever know it came from you... With OpenLedger, your guide would be part of a data collection that logs your contribution. Later, every time an AI uses a fact from your guide in its answers, the system would record that your work was involved. Over time, you could receive recognition or rewards for your contribution — not a vague credit buried somewhere, but an actual traceable record linking your name to that influence.
This idea also tries to help with another problem called the retention problem. This means data that was used long ago might still shape AI decisions now and in the future, but traditional systems have no reliable way to keep track of these older connections.. Once information gets absorbed into a model, the original context and contributor are lost. OpenLedger wants to fix this by keeping an ongoing record of every contribution and linking it to model behavior over time... If your data influences an AI answer years after you added it, the attribution record still exists, and you still deserve recognition.
Even though this vision sounds good, it comes with a lot of challenges and risks. One big risk is complexity.. Tracking exactly how each piece of data influences model outputs is a hard technical problem. AI models mix and reuse information in ways that can be messy and unpredictable. If the attribution system is not accurate or secure, people might get credit they do not deserve, or worse, try to take credit for someone else’s work. That would make the whole system unfair in a new way.
Another risk is cost and performance. Systems that log a lot of data and verify every step could slow things down or require expensive infrastructure. If every tiny detail had to be permanently stored, it might create huge amounts of data that are hard to manage. Finding the right balance between transparency and efficiency would be essential. If the system becomes too slow or costly, few developers or creators will want to use it.
There is also the danger of people trying to game the system. Whenever rewards or recognition are involved, there will always be attempts to manipulate the rules. Someone might upload low-quality or copied data just to get rewards, or find ways to trick the attribution system into believing their contribution was more important than it really was. Safeguards would have to be very strong to reduce fraud and make sure the system stays credible.
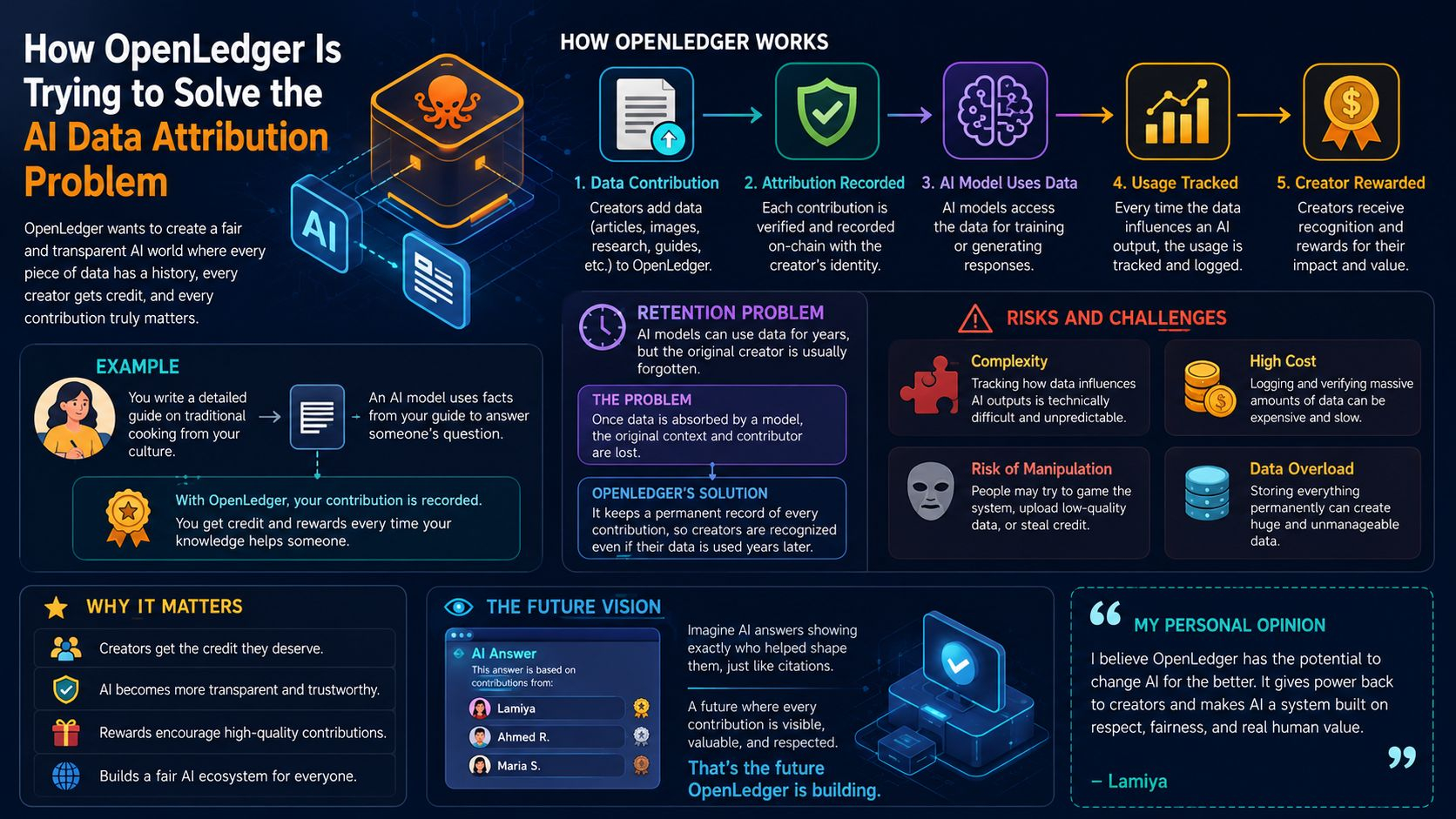
Despite these concerns, I think OpenLedger’s approach is worth exploring because it pushes AI toward fairness and accountability. Right now, most AI models feel like invisible machines that learn from the world but never show who helped make them smarter... If creators had a clear way to show their contribution and even get compensated, it would encourage more people to share high-quality data. The result could be richer, more transparent AI that benefits not just a few big companies, but many individuals and communities who helped build it.
In the future, I imagine a world where AI answers can show you exactly which creators helped shape them, just like citations in a research paper... Not only would this bring respect to content creators, but it would make AI outputs more trustworthy and explainable. Instead of a mysterious black box, AI would become a network of human contributions, each one visible and acknowledged. That feels like a much more human and fair direction for the technology to grow.
