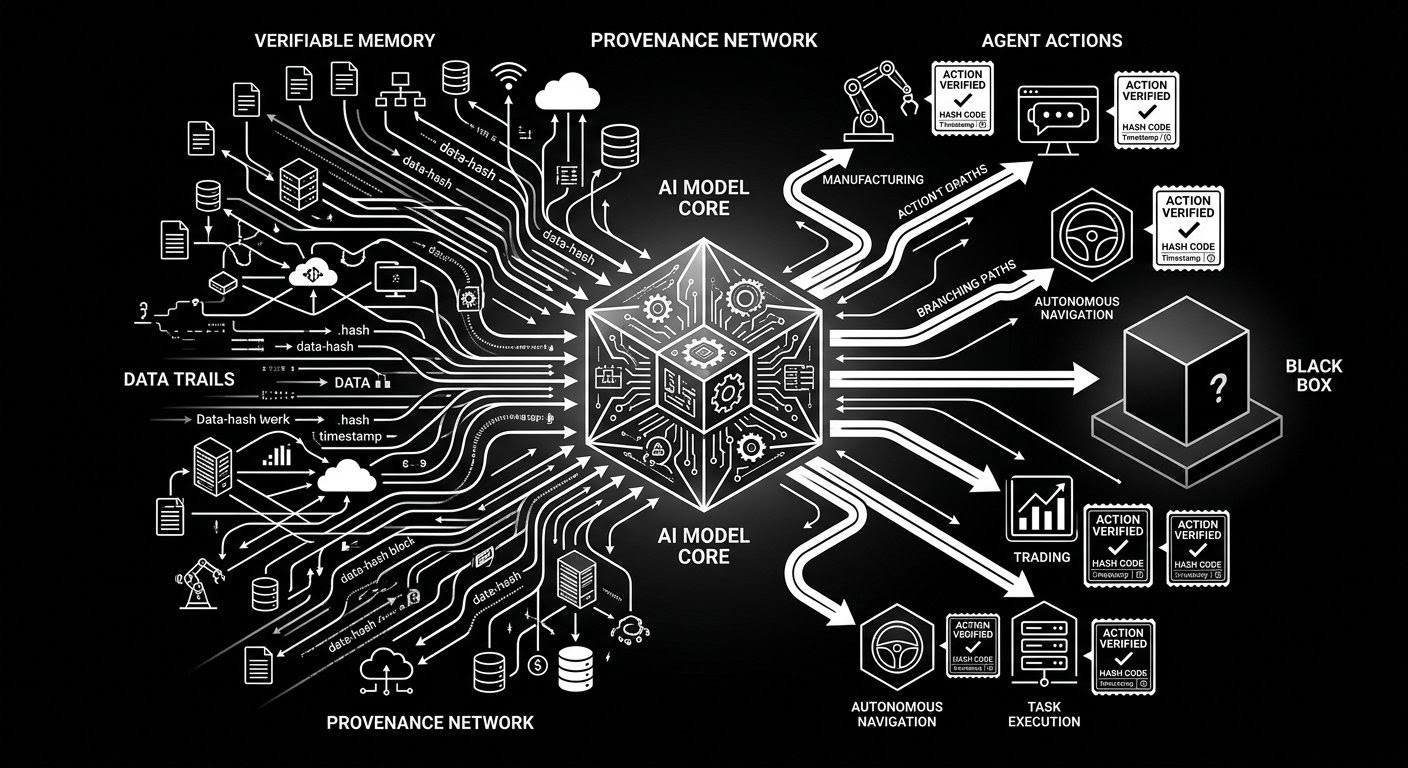

OpenLedger asks the question most AI projects skip. Not how fast can we build models, but whether the systems we build can still be traced once they start taking actions that move real money.
A chatbot giving a wrong answer is a typo you can delete. An AI agent routing capital, executing a trade, or deploying a contract based on hidden influence is a transaction you can’t undo. Typos get edited. Transactions get settled. And once settlement happens, the only thing that matters is whether we can read the trail that led to the decision.

Agents Turn Models Into Infrastructure :
For years AI was built to forget. Data flowed in, weights formed, and a model shipped with no memory of who shaped it. That worked when models only answered questions, because questions don’t move wallets. Agents killed that assumption.
Agents don’t just generate text. They research markets, route capital, manage workflows, trigger on-chain actions, and call APIs. The moment an agent acts, the model underneath it stops being a research project. It becomes infrastructure. And infrastructure without provenance is just automation asking for blind faith.
The problem gets sharper because specialized AI runs on specialized data. Finance agents train on corpuses of trading behavior, DeFi strategies, risk histories, and labeled market signals. These aren’t generic internet scrapes. Influence is concentrated. Every fine-tune is a filter that decides which signals get amplified and which get discarded. If there’s no record of those choices, influence becomes invisible. When value flows, or when losses hit, there’s no path for Proof of Attribution to verify who contributed what.
OpenLedger ModelFactory Makes Creation Accountable :
OpenLedger ModelFactory looks like a low code AI tool at first glance. The real shift is deeper. It turns model creation into part of an attribution economy from the first click.
Every quiet decision during the build gets logged before it disappears into weights. Which Datanets were approved and activated. Whose reputation and validation history shaped the dataset. What signals were emphasized during fine tuning. Which OpenLoRA adapters made the model modular, cheap, or temporary. Those choices don’t vanish. They echo forward through inference, through agent execution, through reward distribution, through compliance audits.
This is the line between a model and a model with provenance. One can answer a prompt. The other can be questioned, traced, and settled against when it starts creating economic impact.
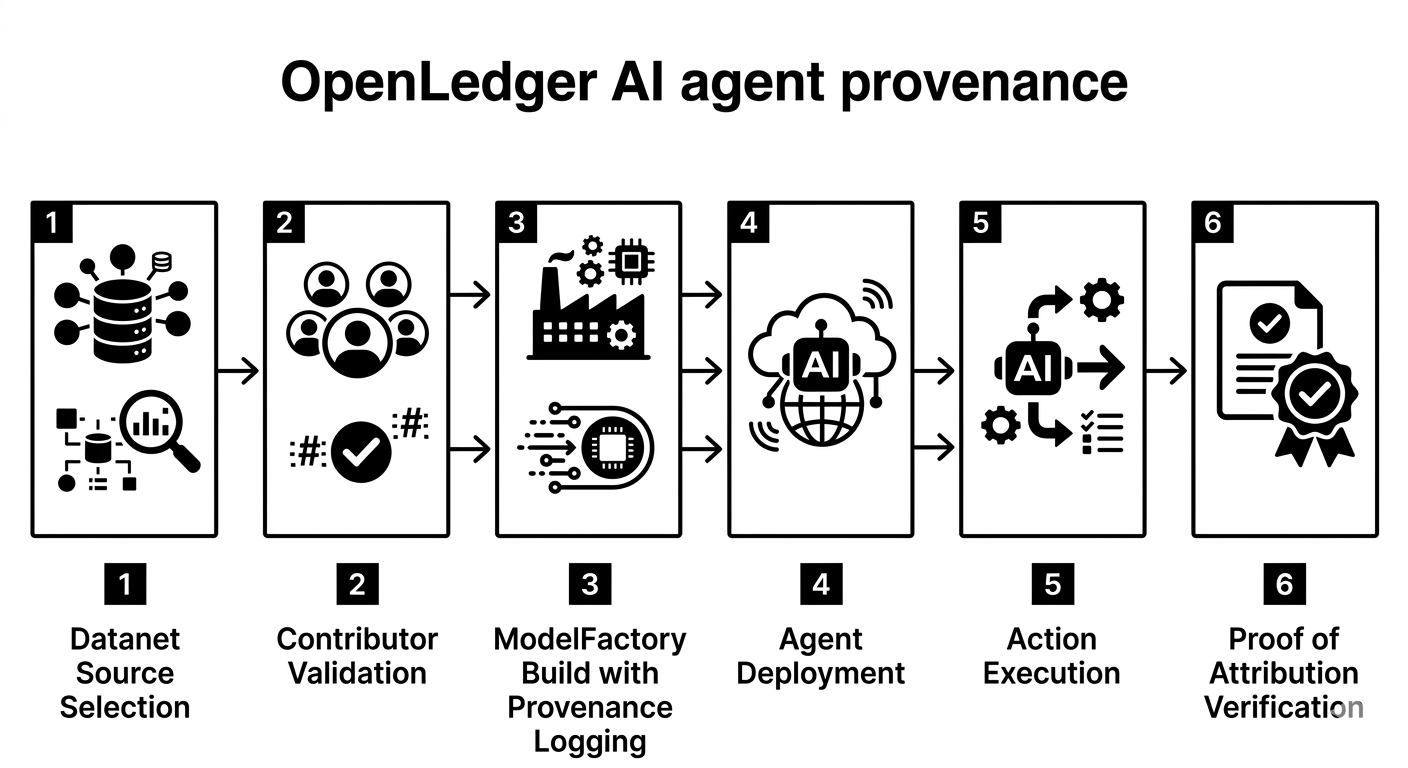
Easier Creation Means Harder Forgetting :
There’s a paradox running through AI right now. As model creation gets easier, accountability becomes more urgent, not less. If building stays hard, only a few centralized teams ship models and the black box stays small. If ModelFactory makes building easy, we get an explosion of niche models, agent-specific models, vertical use cases. That’s the innovation wave the space needs. But without attribution, it’s chaos with a cleaner UI.
Convenience usually erases history. Creation gets easier and forgetting gets easier too. Datasets blur together. Credits vanish. Outputs look self born. OpenLedger pushes the opposite principle into the stack: easier creation, harder forgetting. When a model is tied into Datanets and Proof of Attribution from the start, it can’t fully escape its supply chain. It can become useful, profitable, widely deployed, but it still carries the receipt of what helped it get there.
That’s why OpenLedger matters in this movement not as a ticker or decoration, but as settlement language. If a model earns through usage, the reward path has to know what it’s rewarding. Data contributors, model builders, compute participants, agent executors all need to be visible in the flow. Otherwise monetization becomes another word for extraction.
Trust the Trail, Not the Claim
Most people want AI to feel instant. Prompt in, answer out. No ancestry, no baggage, no receipt. OpenLedger’s architecture pushes against that smoothness on purpose. The builder interface can be clean. The system underneath should not be. If someone’s data shaped the behavior, if a Datanet trained the instinct, if a contributor’s work improved the outcome, the system needs enough memory for that to matter later.
A model doesn’t feel dangerous while it’s being built. It feels like a workflow. Some configs, some datasets, a builder clicking through steps. The risk shows up later, when that model sits inside an agent, or a trading flow, or a query API that real capital depends on. At that point the ModelFactory choices become load-bearing. Which Datanet was trusted. Which contributor passed validation. Which data survived fine-tuning. Which piece later gets recognized by Proof of Attribution when rewards distribute.
That’s not backend detail. That’s the future argument. Every model is a future dispute over influence.

Actions Need Receipts, Not Just Answers
A bad answer from a model is one thing. A bad action from a model with hidden influence is something else entirely. If an agent routes capital, triggers a trade, or executes on-chain, the model under it can’t be treated like a blank brain. The action needs a trail too.
An agent execution receipt without model provenance underneath is only half a receipt. OpenLedger ModelFactory is the quiet starting point for that louder problem. It’s not the flashiest part of the stack. But it decides what kind of ancestry the model will have before the model starts acting like it came from nowhere.
Every useful model owes an explanation to the inputs that made it useful. OpenLedger is trying to make that explanation economic, traceable, and harder to fake.
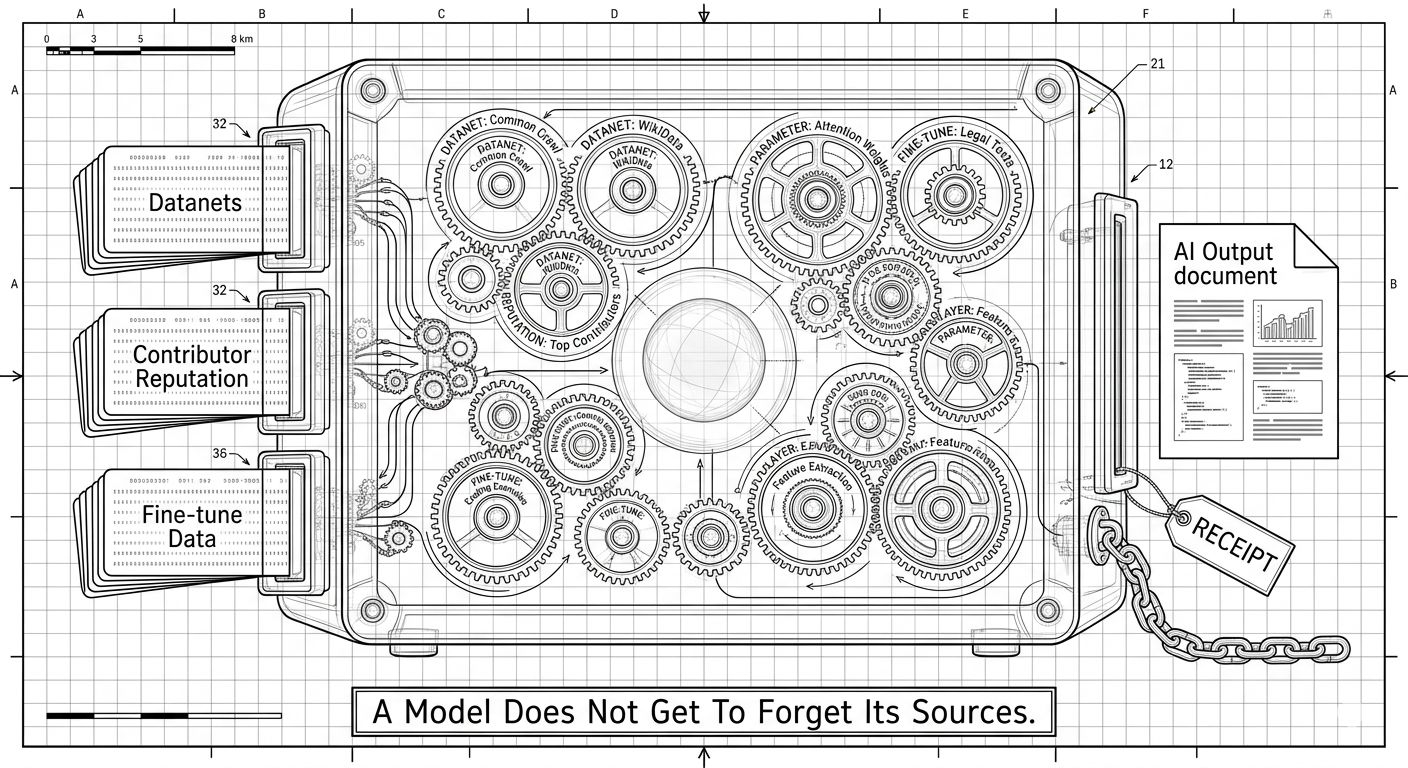
Verifiable Memory Beats Raw Intelligence :
The uncomfortable truth is that OpenLedger doesn’t just ask whether AI can be built faster. It asks whether the thing being built can still be traced after it starts making money. Some models will carry clean trails. Some will carry messy ones. Some will look smart until Proof of Attribution shows what actually moved inside them.
That distinction is the point. If AI is going to become an economy, models can’t get to act like orphans.
With OpenLedger, every agent action has a receipt. Every receipt has a source. Every source has a Datanet.
Verifiable memory beats raw intelligence. Because when agents start acting, you trust the trail, not the claim.