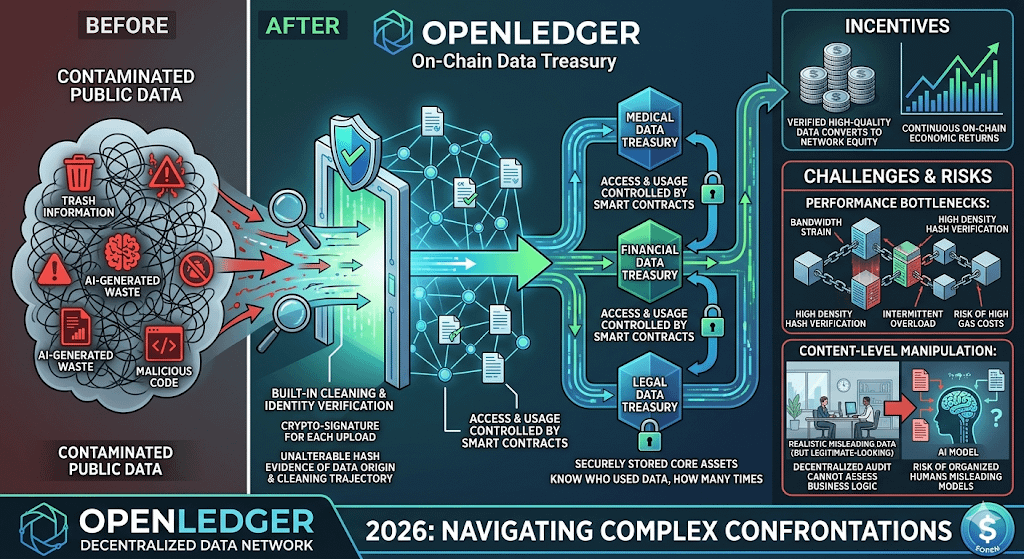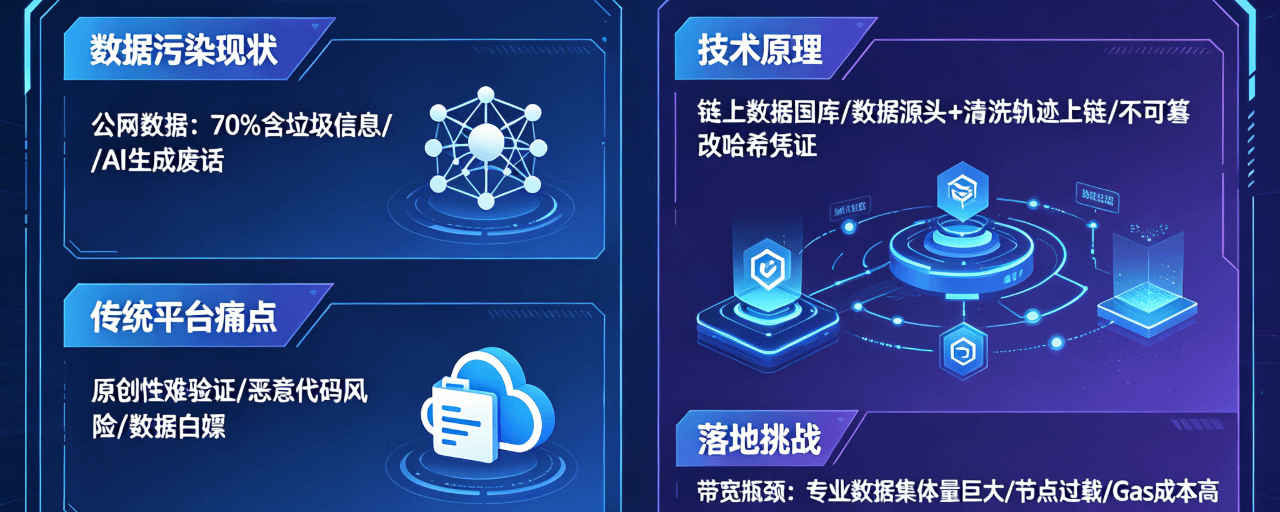

说实在的,现在搞人工智能模型微调,最让人头疼的根本不是算法怎么写,而是上哪儿去找干净、没被污染的专业数据集。现在公网上能爬到的公开数据,大半都被各种垃圾信息和AI生成的废话给污染了。@OpenLedger OpenLedger 这次做的事情,本质上是在用区块链的去中心化共识,去解决特定领域垂直数据的信任度问题。
他们搞出来的去中心化数据网络,你别把它理解成普通的云盘或者分布式存储,它在底层其实是一套自带清洗和身份验证的链上数据国库。过去大家上传数据,平台很难判定这东西到底是不是你原创的,有没有掺杂恶意代码或者伪造的垃圾信息。现在的做法是,每一个上传的行为都必须绑定唯一的加密签名,你的数据源头、清洗轨迹全部都会变成区块里不可篡改的哈希凭证。这种高强度的可验证性,等于是在数据进入训练集之前,先通过原生的密码学手段做了一次无差别的真伪隔离。
有了这套无需信任的准入机制,那些在医疗、金融或者法律等垂直行业手里握着核心干货的专业团队,才敢把自己的核心资产拿出来。因为整个调用和访问的权限都是通过智能合约来控制的,谁用了你的数据集去喂模型、喂了多少次,账本里写得清清楚楚。这就直接杜绝了传统大厂那种把数据拿走之后就翻脸不认账的白嫖行径。每一份经过验证的高质量数据,都会转化为你在该网络中的长期权益证明,持续为你带来链上的经济回流。
不过这种看似完美的去中心化分发逻辑,在实际落地的时候肯定会遇到不少硬骨头。首要的问题就是多节点在对这些海量专业数据进行分布式验证时,底层的通信带宽能不能跟上。你要知道,很多专业数据集的体量是非常恐怖的,单纯靠链上的有限吞吐量去处理这些高密度的哈希校验,很容易造成网络节点的间歇性过载,甚至拉高整体的Gas成本。
再一个,虽然密码学能解决数据的出处和所有权问题,但它目前还是没办法完全坐在办公室里就判定出一段行业数据的业务逻辑到底对不对。万一有利益集团组织了一批高智商的真人去故意上传一些合规但方向错误的误导性数据,这套全自动的去中心化审计机制能不能在模型被带偏之前及时发出警报,这都需要在 2026 年接下来的复杂对抗中去经历真正的实战检验。$OPEN