Most AI projects try to impress people with outputs.
Faster answers, smarter agents, cleaner demos, better automation.
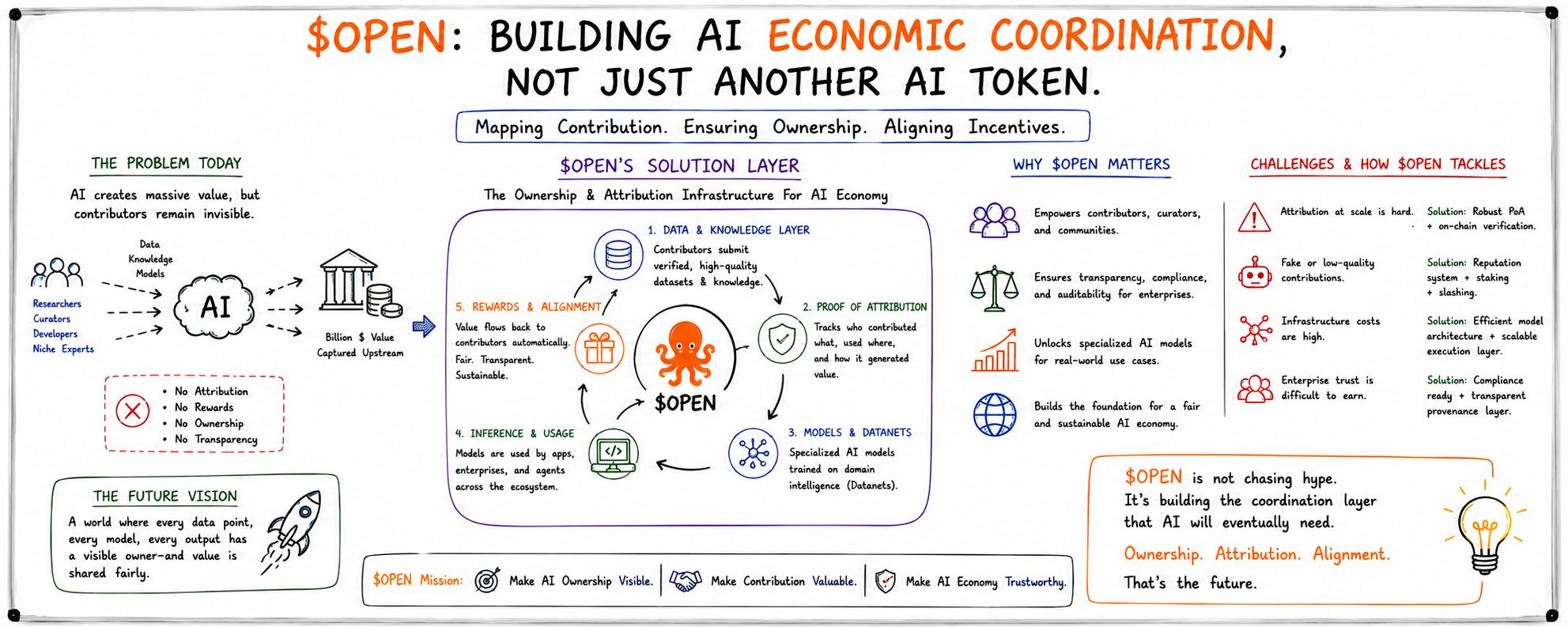
But the deeper I looked into @OpenLedger , the more I felt they are focused on something underneath the output itself… ownership coordination.
That difference matters more than people think.
Right now the AI industry moves in a strange direction.
Models become more powerful every month, but the people contributing data, niche knowledge, fine-tuning, and behavioral context still remain mostly invisible economically.
AI keeps absorbing value from everywhere.
Communities, researchers, creators, traders, developers.
But very few systems can actually track where that value originated from once the model starts producing useful outputs.
That’s where #OpenLedger started making sense to me differently.
The project does not feel like another “AI assistant” narrative.
It feels more like infrastructure for mapping contribution itself.
The interesting part is not only Proof of Attribution rewards.
I think the bigger idea is reducing uncertainty around AI systems.
If enterprises eventually depend on AI for finance, healthcare, legal workflows, or autonomous coordination, then questions become much more serious.
Where did the training data come from?
Who influenced the model behavior?
Can outputs be audited later?
Can contributors be verified?
Can institutions trust the system enough to build on top of it?
Most crypto AI discussions still focus only on intelligence speed.
OpenLedger feels focused on intelligence accountability.
That changes the angle completely.
Their Datanets model also feels underrated to me.
Instead of treating data like passive storage, OpenLedger turns specialized knowledge into an active economic layer where contributors, models, and applications stay connected through attribution.
And honestly, that feels closer to where AI is heading.
The future probably does not belong only to giant general-purpose models.
It may belong to highly specialized systems trained on verified domain intelligence.
Finance AI.
Medical AI.
Legal AI.
Gaming AI.
Localized language models.
Those systems need trusted datasets more than hype narratives.
That’s why $OPEN feels more connected to infrastructure demand than temporary attention cycles.
Of course there are risks.
Attribution at scale is difficult.
AI coordination becomes messy when incentives enter the system.
Spam datasets, fake contribution farming, and weak verification could damage trust quickly.
But at least OpenLedger seems aware of those problems early.
The positive part is that their architecture already revolves around provenance, registries, attribution tracking, and transparent contribution flows instead of treating them like optional features later.
That gives the ecosystem more long-term depth in my opinion.
Maybe OpenLedger fails.
Maybe the market is still too early for AI ownership infrastructure.
But I genuinely think most people are still underestimating how important attribution, accountability, and specialized data economies may become once AI systems start handling real economic activity globally.
And if that shift happens, projects building invisible trust layers early could matter far more than people expect today.