That Ignored It Are Going To Look Very Unprepared
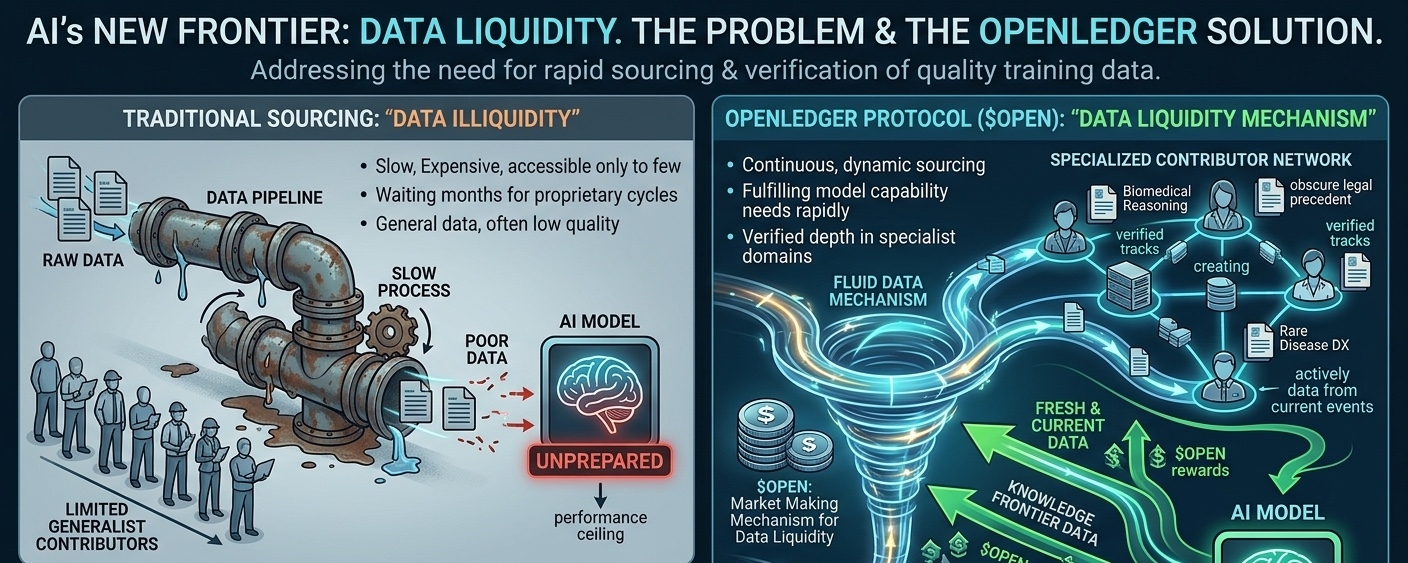
Data liquidity is a term almost nobody in the AI infrastructure conversation uses and I think that absence reveals something important about how poorly the industry understands its own structural constraints. When I talk about data liquidity I mean the ability to rapidly source verify and deploy specific categories of training data in response to a defined model capability need without waiting months for a proprietary collection and labeling cycle to complete. The current state of data liquidity in AI development is approximately what financial market liquidity looked like before electronic trading infrastructure existed which is to say it is slow expensive and accessible only to organizations with significant existing vendor relationships.
This is where @OpenLedger occupies a position that I think will look increasingly strategic as the competitive dynamics of AI development intensify. The protocol is not just a place where data exists it is a mechanism for converting a defined data need into a fulfilled verified dataset through a contributor and validator network that operates continuously rather than on project cycles. That continuous operation is the liquidity mechanism and the $OPEN incentive structure is what keeps that mechanism functioning between periods of high external demand. Most people read the tokenomics as a reward distribution system and miss that its actually a market making mechanism for data liquidity.
The depth of the contributor specialization layer is something I want to examine because I think it is more architecturally significant than the surface-level coverage suggests. OpenLedger is not designing for a uniform contributor base where every participant produces every type of data interchangeably. The protocol is building toward a segmented contributor network where participants develop documented on-chain expertise in specific data categories and their reward weights reflect the demonstrated quality of their contributions within those categories specifically. A contributor who has built a verified track record producing high-quality structured data in biomedical reasoning tasks earns premium rewards for that category and lower weights outside it. That segmentation creates a contributor marketplace with real specialization depth rather than a flat pool of generalist data workers.
I find this design choice genuinely smart even though I remain skeptical of the execution timeline. The reason specialized contributor depth matters to serious AI buyers is that the hardest training data problems are almost always in narrow high-stakes domains where general knowledge is insufficient and domain expertise is essential. Anyone can label images of cats. Training a model to reason accurately about rare disease differential diagnosis or obscure jurisdictional legal precedent requires contributors who actually know those domains and can produce data that reflects genuine expertise rather than surface familiarity. If @OpenLedger can build verified depth in even a handful of high-value specialist domains it will command pricing power that general-purpose data marketplaces simply cannot match.
My hot take on the broader AI data market right now. The entire industry is operating on an assumption that hasnt been seriously stress-tested which is that the current approach to training data sourcing is good enough to get frontier models to wherever they need to go. I think that assumption breaks within the next two years as model capability improvements from scaling alone start to flatten and the performance differentiation between models increasingly comes from data quality and curation rather than parameter count and compute budget. When that shift becomes visible in benchmark results the premium on verified curated attributed training data is going to reprice dramatically and every infrastructure project positioned in that space will be evaluated on whether it can actually deliver at scale.
But the part of the OPEN design I keep returning to is the economic relationship between data freshness and reward weighting. The protocol creates financial incentives for contributors to produce data that reflects current real-world conditions rather than just submitting archival content that already exists in the public domain. A contributor who synthesizes structured training data from recent developments in a rapidly evolving technical field earns higher rewards than a contributor recycling well-documented historical information because the marginal value of fresh verified data to an AI developer is substantially higher than the marginal value of another copy of something the model probably already encountered during pretraining. Thats not just a quality mechanism its a market signal about where genuine value creation happens in the data economy.
And the implications of that freshness incentive extend further than the immediate reward calculation. It means the OpenLedger contributor network is structurally oriented toward producing data that sits at the knowledge frontier rather than the knowledge center. Training data at the knowledge frontier is exactly what models need to reason accurately about emerging situations novel problems and recently developed technical concepts and it is exactly what is hardest to source through conventional data collection methods because by definition frontier knowledge hasnt yet been widely documented indexed and scraped. The network design aligns contributor incentives with the hardest and most valuable data problem in the industry and I think that alignment is more intentional than accidental.
I want to be direct about the competitive risk I watch most carefully with this project. The major AI labs are not passive observers of the decentralized data infrastructure space. Organizations like Google DeepMind and Anthropic have the resources to build internal versions of the data quality and attribution infrastructure that OpenLedger is developing as a public protocol and they have strong competitive reasons to keep that infrastructure proprietary if it creates a meaningful quality advantage. The question is whether they will bother doing so or whether regulatory pressure around data attribution will make a shared public protocol more attractive than a proprietary system that invites scrutiny. I genuinely dont know which way that resolves but the answer matters significantly for the addressable market @OpenLedger can realistically capture.
What I think gets underweighted in almost every analysis of open is the network effect dynamic that operates on the validator side rather than the contributor side. Most network effect discussions in crypto focus on user growth and liquidity concentration but the validator reputation network in OpenLedger compounds in a specific way that becomes increasingly hard to replicate as it matures. A validator who has accumulated two years of accurate quality assessments across thousands of submissions in a specialized domain has built something that a new entrant to the validation market simply cannot purchase or shortcut. That accumulated judgment represents genuine institutional knowledge about what high-quality training data looks like in specific domains and it creates a quality assurance layer with real defensibility that improves as the network ages rather than degrading as most early mover advantages do.
Im more engaged by this project today than I was six months ago and that direction of travel matters to me more than any single technical feature. The problem is real. The architecture is getting more sophisticated not less. And the market conditions that would accelerate adoption are strengthening. That combination is rare enough that I note it when I see it.