And The Continuous Data Problem Is Where OpenLedger Makes Its Most Underrated Case
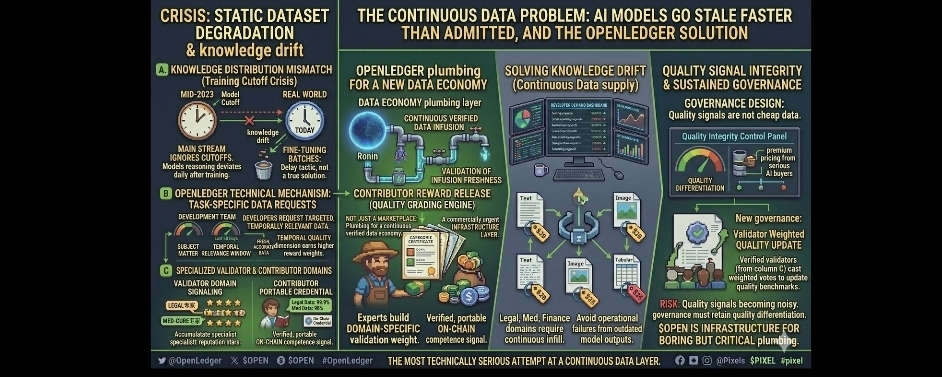
Static datasets are a quiet crisis nobody in the mainstream AI conversation wants to address. A model trained on data collected through mid-2023 is already operating with a knowledge distribution that looks increasingly different from the real world it is being asked to reason about and the gap between what the model knows and what is actually true widens every single day after that training cutoff. The industry response to this problem has mostly been to fine-tune on small update batches and hope the degradation isnt visible enough to matter commercially but that is not a solution it is a delay tactic dressed up as an engineering decision.
This is the angle on OpenLedger that I think almost nobody is covering and it deserves serious attention. A decentralized contributor network that continuously produces verified attributed human-sourced data is not just a marketplace for building models from scratch. Its potentially the infrastructure layer that keeps deployed models accurate and current without requiring the kind of full retraining cycles that cost millions of dollars in compute and months of engineering time. The continuous data supply problem is arguably more commercially urgent than the initial training data sourcing problem and @OpenLedger is structurally positioned to address both simultaneously.
The technical mechanism that makes this relevant is the task-specific data request system I have been watching evolve in the protocol design. AI development teams can submit targeted data requests to the OpenLedger contributor network specifying not just subject matter but the temporal relevance window they need meaning they can request data that reflects current real-world conditions rather than historical snapshots. Contributors who can consistently produce fresh accurate data within specific knowledge domains earn higher reward weights than contributors submitting information with no clear temporal relevance. That temporal quality dimension is something I have not seen prioritized in any other open data network at the protocol incentive level.
My honest read on why this matters more than people think. The organizations deploying AI in production environments are already experiencing what engineers internally call knowledge drift where model outputs in specialized domains start diverging from ground truth at a rate that creates real operational problems. Legal AI tools give advice based on superseded regulations. Medical AI tools reference treatment protocols that have been updated. Financial AI tools reason from market structure assumptions that no longer reflect current conditions. The solution to knowledge drift is continuous verified data infusion and the market for that specific capability is going to be significant.
But I want to address something that bothers me about how $OPEN gets positioned in most retail-facing commentary. The framing is almost always about passive income for contributors and token rewards for participation and while those mechanics are real and matter for network bootstrapping they obscure what I think is the more important story which is that OpenLedger is building the plumbing for a data economy that doesnt currently exist in any functioning form. Plumbing is not exciting. Plumbing does not trend on social media. But every major technology platform ever built eventually became dependent on infrastructure that was boring to talk about when it was being constructed.
The validator specialization dynamic is something I find technically compelling in a way that goes beyond the basic quality assurance function. As the OpenLedger network matures validators are able to develop and signal specialization in specific knowledge domains meaning a validator with demonstrated expertise in legal data assessment or biomedical literature curation accumulates reputation weight specifically within those domains rather than just across the network generally. That domain-specific validator reputation creates the possibility of a trusted expert review layer for highly specialized training data that simply cannot be replicated by general crowdsourced validation. I dont know another open data protocol that has architected validator incentives with that level of domain specificity.
And the contributor side of domain specialization creates something interesting that I think will take time to fully surface. A researcher with genuine expertise in a specialized field who contributes structured knowledge to the OpenLedger network is building an on-chain record of domain expertise that is verifiable and portable in a way that no existing professional credential system provides. The on-chain contribution history is not just an economic record its a competence signal and I think the secondary uses of that signal for professional credentialing knowledge work compensation and AI development team hiring are underappreciated externalities of the network that nobody is modeling into the long-term value discussion around $OPEN.
Im going to say something that might be unpopular. I think the biggest risk to OpenLedger is not technical failure or regulatory headwinds or even competitive pressure from centralized data providers. The biggest risk is premature commoditization of the contribution layer where the protocol succeeds in bootstrapping a large contributor base but fails to maintain the quality differentiation that makes the data valuable enough to command premium pricing from serious AI buyers. If the network grows fast but quality signals become noisy the whole value proposition collapses into just another cheap undifferentiated data source and there are already plenty of those. Quality signal integrity is the one variable I watch more closely than anything else and it requires sustained governance discipline that most decentralized networks historically struggle to maintain past the initial community enthusiasm phase.
What keeps me engaged despite that concern is that @OpenLedger appears to understand this risk better than most projects understand their own critical vulnerabilities. The governance design around quality standard updates gives established validators meaningful weight in determining how quality benchmarks evolve over time rather than leaving those decisions entirely to a core team that could be captured by short-term growth incentives. Thats not a perfect solution but its a more honest architecture for quality preservation than I usually see.
The project is at a stage where the thesis is coherent the architecture is defensible and the market timing looks better than it did eighteen months ago. Im not calling it proven. Im saying its the most technically serious attempt I have seen at solving a problem that is going to become impossible to ignore.
