
There was a moment a few weeks back that I keep returning to.
I was running the same prompt across three different AI tools nothing exotic, just pulling sentiment signals on a mid-cap token and somewhere between the second and third output, something felt off. Not dramatically wrong. Just... quietly different. One system was consistently skewing bearish on a project that the other two treated as neutral. Small divergence on the surface. But when you are making any decisions based on these outputs, small is everything.
I have spent many time trying to figure out. Checked the prompts, checked the timing, checked whether one model had a stale training window. Nothing obvious. And then I had a thought that should have been obvious from the start: I have absolutely no idea where any of these systems got their information, who contributed that data, or how much any single source is influencing the final output.
That's the thing about most AI systems in crypto right now. They're fast. They're capable. And they're almost entirely opaque.
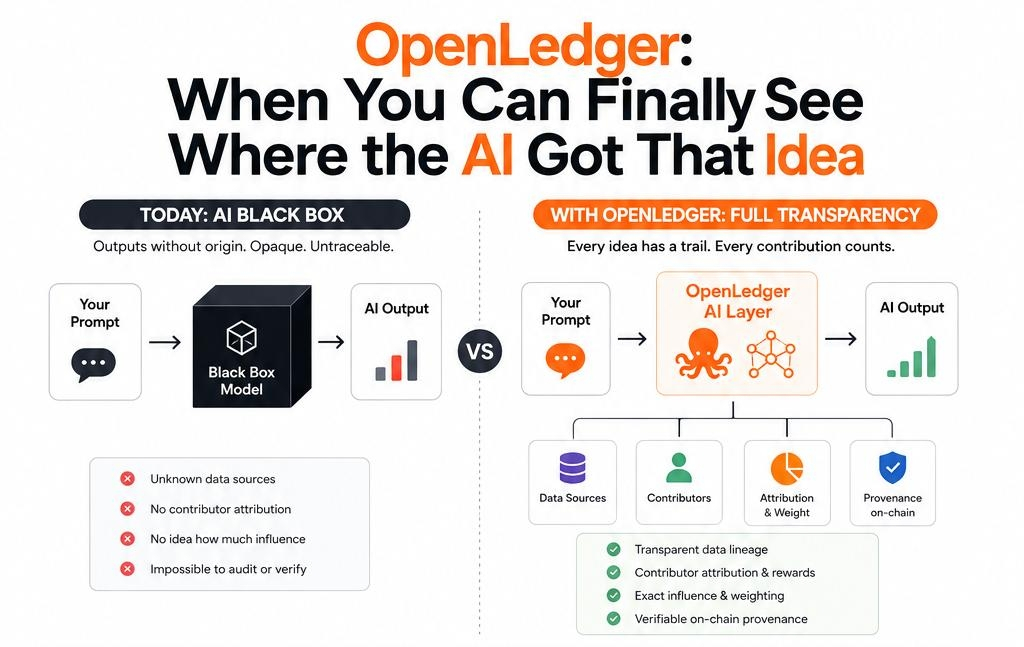
We've spent three years normalizing this. We accept that AI outputs arrive like verdicts from a courtroom we're not allowed to enter. The model trained on something, somewhere, contributed to by someone, weighted somehow and the result appears on our screen as if it descended from a cloud rather than emerged from a messy, human, contestable process of data curation.
I think we've been so dazzled by what these systems can do that we forgot to ask how they're doing it. And in a market where a single misattributed dataset can move a narrative and narratives move prices that's not a philosophical concern. It's a practical one.
This is the part where I usually talk myself into accepting the trade-off. Speed vs transparency. Power vs explainability. Most tools make that bargain feel inevitable, like you're supposed to just pick capability and stop asking uncomfortable questions about the internals.
OpenLedger is the first thing I've spent serious time with that actually refuses that framing.
The $OPEN thesis and I've been skeptical of it for longer than I'd like to admit is fundamentally about making AI's supply chain visible. Not just the output, but the lineage. Who contributed the data, what that data influenced, how much weight it carried, and whether the contributor can be traced and compensated. It sounds abstract until you sit with it for five minutes and realize what it would have meant in the scenario I described earlier. If I could see that one system's bearish skew traced back to three datasets from a single source with a clear short bias, that changes my entire interpretation of the output.
That's not a minor UX improvement. That's a different category of tool.
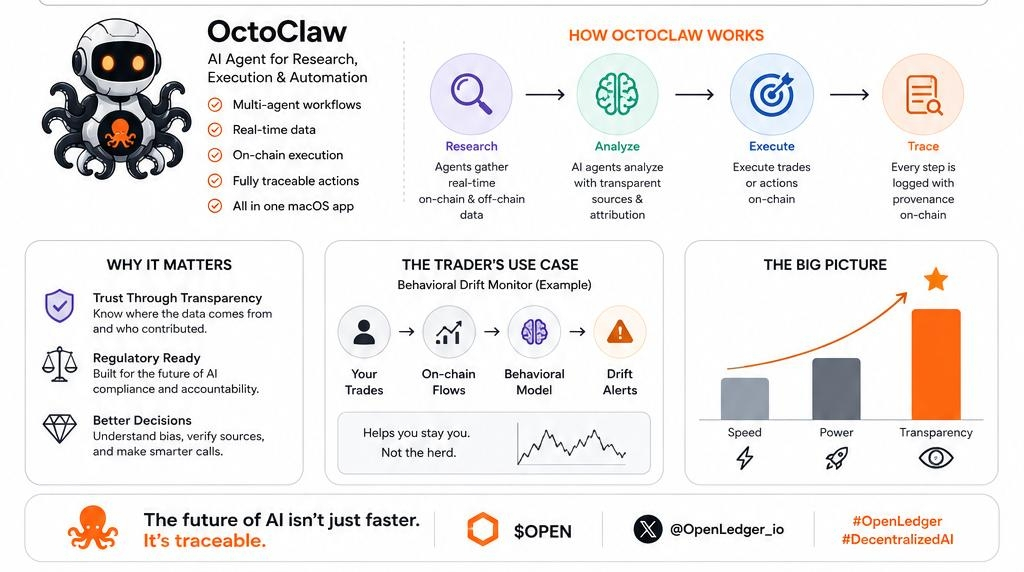
The OctoClaw launch OpenLedger's agent product that just went live on macOS is interesting for this reason more than any other. The pitch is orchestration: research and execution under one roof, multiple agent workflows, on-chain action with real-time data. Technically, it's competitive with a whole stack of tools I currently use separately. But the framing that keeps pulling my attention is the transparency layer underneath it.
Most orchestration tools are sophisticated black boxes. Faster black boxes. Better-designed black boxes. OctoClaw's premise, at least as I understand it, is that the orchestration is traceable. Not just what the agent did, but why, and based on what, and contributed by whom.
That's a harder engineering problem than it sounds. And it changes who actually benefits from the system.
I've thought a lot about what I'd actually build if I had a reliable transparent AI layer under me. Honestly? A behavioral drift monitor. Something that watches my own trading pattern against on-chain flows and flags when I'm starting to herd unconsciously when my thesis is no longer mine but has quietly become a consensus I absorbed without noticing. Every crypto trader has experienced this. You think you're independently bullish on something and then realize you've just been marinating in a group chat for two weeks. The trauma is real.
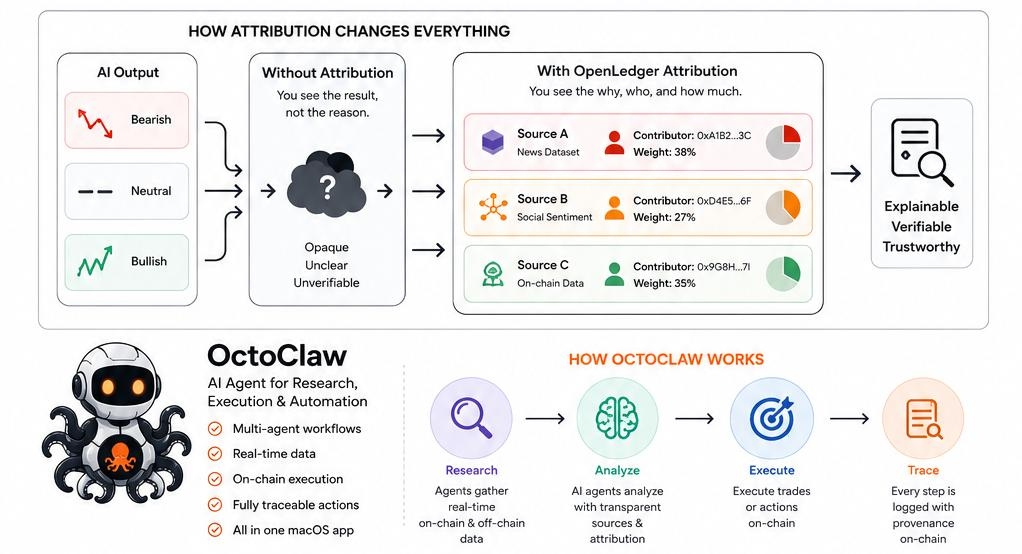
The reason nothing like this exists yet isn't really a data problem. It's a trust problem. To build a tool like that, you need to know that the data informing the behavioral model isn't itself a product of the same consensus you're trying to escape. You need attribution. You need to see the original sources, weighted and labeled, rather than a blended output that launders its own biases into something that looks like objectivity.
Traceable datasets are worth more than fast datasets. I'd argue they're worth dramatically more in a market context, where the provenance of information is often more predictive than the information itself.
The institutional angle on this is something I don't think gets enough attention in retail-facing discussions of OpenLedger. Regulators aren't going to accept "the model said so" as a justification for AI-assisted financial decisions indefinitely. Compliance teams at serious shops already understand that explainability is coming as a regulatory requirement it's not a maybe, it's a timeline question. A platform that builds attribution and traceability into its architecture from the ground up isn't just philosophically interesting. It's potentially the only category of AI infrastructure that survives the next wave of regulatory attention.
That's a different kind of moat than raw performance. And in a market that tends to reward hype cycles over structural advantages, it's the kind of moat that gets massively underpriced until it suddenly doesn't.
I want to be honest about what I don't yet know, though, because I think there's an important open question around OctoClaw specifically.
The agent launched during a period of active incentives, which means usage data right now is noisy by definition. Incentive phases in crypto attract a very specific type of user who is optimizing for points or tokens rather than genuine workflow integration. I've done it myself loaded up a product I'd never normally use because the early participation rewards were too good to ignore, contributed zero real signal, and moved on.
The question I keep sitting with is: when the incentive structure normalizes, will OctoClaw users actually be running meaningful agent workflows, or will the platform discover that it has a very small core of genuine users surrounded by a much larger group of incentive tourists who never really came for the product?
That's not a dismissal. It's the right question to hold before getting too confident in any direction.
The systems are getting more capable faster than most people anticipated. But capability without accountability is, in a financial context especially, just a faster way to make consequential mistakes. The next meaningful jump in AI adoption not in usage numbers, in actual dependence probably doesn't come from making these systems smarter. It comes from making them legible.
The AI stack that earns real institutional and individual trust in the next three years might not be the fastest or the most powerful. It might simply be the one where you can finally see where the idea came from.
That alone might be worth more than everything else combined.