The AI revolution has created one of the strangest economic imbalances in modern technology. The companies building large models are becoming some of the most valuable organizations in human history, while the people supplying the raw material behind those systems remain mostly invisible. Every AI model is built on an ocean of human contribution: writing, conversations, behavior, code, medical records, financial patterns, images, translations, research, annotations, clicks, corrections, and lived experience. Yet once that information enters the machine, ownership almost disappears. The model becomes valuable. The contributors fade into the background.
That imbalance sits quietly underneath the rise of OpenLedger.
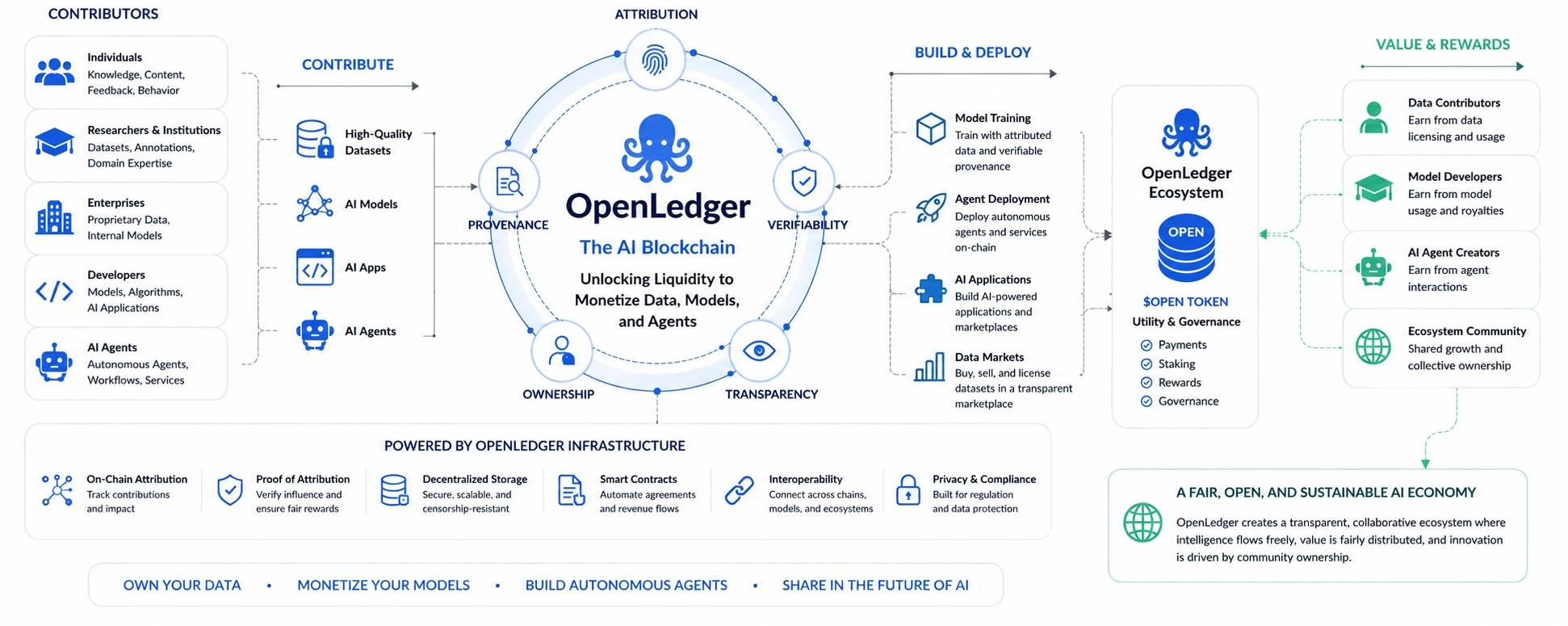
At first glance, OpenLedger looks like another project trying to fuse blockchain and artificial intelligence together, which has become an increasingly crowded space filled with oversized promises and vague narratives. But beneath the surface branding, the project is chasing a much deeper idea. It is trying to redesign how value moves through AI systems. Instead of treating data like disposable fuel that gets swallowed by centralized models forever, OpenLedger wants intelligence to become economically traceable. Its entire philosophy revolves around a simple but powerful belief: if data contributes to intelligence, then the people and systems behind that data should not disappear once the AI becomes profitable.
That changes the conversation completely.
Most AI companies operate like giant extraction engines. They absorb information at massive scale, refine it into models, and then build commercial products on top. The flow of value is mostly vertical. Information moves upward into centralized systems, and revenue follows the same path. OpenLedger is trying to interrupt that cycle by introducing attribution, provenance, and programmable ownership into the AI pipeline itself. In its ideal form, data does not simply vanish into a black box. It leaves fingerprints. Those fingerprints can be tracked, measured, and eventually monetized.
This is why OpenLedger matters beyond the usual crypto narrative. The blockchain component is not really the center of the story. The real story is the attempt to create an economic system for intelligence itself.
That idea becomes more important the deeper AI enters society. Right now, most people still think about AI as a product: chatbots, assistants, image generators, recommendation engines. But the technology is gradually becoming infrastructure. It is moving into healthcare systems, financial markets, education, logistics, scientific research, legal analysis, security operations, and autonomous software agents. Once AI becomes embedded into the structure of everyday systems, questions around ownership become unavoidable. Who owns the training data? Who gets compensated when a model becomes commercially successful? Which communities benefit when local knowledge trains global systems? How do institutions share information without surrendering all control over it forever?
These are the kinds of problems OpenLedger is trying to address before they become impossible to untangle.
One of the project’s most interesting concepts is its emphasis on attribution. Traditional AI systems are notoriously bad at preserving provenance. Once information enters a model, tracing exact influence becomes difficult. Data mixes together, compresses, mutates, and reappears in ways that are often impossible to map cleanly. OpenLedger’s vision is built around the idea that future AI ecosystems will require better economic memory. Not just smarter systems, but systems capable of recording where intelligence came from and how value should flow back toward contributors.
If that sounds abstract, think about the music industry. Streaming platforms transformed songs into continuously monetized assets where royalties could theoretically flow back to artists whenever their work generated engagement. OpenLedger imagines something similar for AI. Datasets, models, and agents become living economic entities rather than static digital objects. Instead of one-time extraction, contributors participate in ongoing value creation.
That idea could eventually reshape how organizations interact with AI altogether. A hospital with valuable medical data might contribute information to train specialized healthcare models while retaining visibility and economic participation. A research institution could monetize scientific datasets without completely surrendering ownership. Communities with unique linguistic or cultural knowledge could help train localized AI systems while maintaining a stake in the resulting ecosystem. In this framework, intelligence stops being a closed product and starts behaving more like an open market of contributions.
What makes the timing significant is that the AI industry is entering a phase where data quality matters more than raw quantity. Early models benefited from scraping massive portions of the internet, but that strategy is beginning to weaken. Copyright lawsuits are growing. Publishers are restricting access. Governments are paying closer attention. Enterprises are becoming more protective of proprietary information. The next generation of AI systems will likely depend less on endless public scraping and more on specialized, high-signal, trustworthy datasets. That creates an entirely different economic environment.
OpenLedger appears designed for that transition.
The project’s worldview assumes that future AI competition will not simply revolve around who owns the biggest models. It will revolve around who can coordinate the most valuable ecosystems of data, contributors, agents, and applications. That is a very different way of looking at the future of artificial intelligence. It shifts the focus away from centralized laboratories and toward networked intelligence economies.
There is also a political dimension hidden inside this architecture. AI is rapidly concentrating cognitive power into a handful of companies capable of controlling models, infrastructure, distribution, and increasingly even public information flows. The more advanced these systems become, the more influence accumulates around the organizations that own them. OpenLedger represents a reaction against that concentration. Its philosophy leans toward decentralization not only in a technical sense, but in an economic sense. It imagines a world where intelligence can be shared, attributed, monetized, and distributed more broadly instead of being absorbed into a few opaque systems.
That is an ambitious vision, and ambition alone does not guarantee success.
The technical challenges are enormous. Attribution inside AI systems remains deeply difficult. Models do not naturally expose clear maps showing which pieces of data influenced specific outputs. Measuring contribution at scale is one of the hardest unsolved problems in machine learning. Even if attribution mechanisms improve, incentive systems introduce new complications. Whenever economic rewards exist, participants try to optimize for them. Low-quality data, manipulation, spam contributions, and artificial engagement could become major problems inside open intelligence markets.
Then there is the simple reality of competition. Centralized AI firms move extremely fast because they control massive compute infrastructure, elite research teams, proprietary datasets, and global distribution channels. Decentralized systems often struggle with coordination, governance, and execution speed. OpenLedger is effectively attempting to build an alternative economic framework powerful enough to compete with vertically integrated AI empires. That is not a small challenge. It is a structural one.
Still, the project touches a nerve because it addresses a growing discomfort surrounding the current AI landscape. More people are beginning to realize that the internet’s old extraction model is repeating itself at a much larger scale. Platforms once monetized human attention while returning only fragments of the value back to users. AI risks monetizing human intelligence itself in much the same way. OpenLedger belongs to a broader movement trying to prevent that future from becoming permanent.
Its significance may ultimately have less to do with token prices or speculative cycles and more to do with whether the world begins demanding accountability around intelligence production. Regulators are already asking difficult questions about training data, copyright, bias, transparency, and explainability. Enterprises want auditability. Institutions want traceability. Governments want oversight. Current AI systems often struggle to provide clear answers because they were not designed around provenance in the first place. OpenLedger’s architecture appears aimed directly at that weakness.
In that sense, the project may be less about crypto speculation and more about preparing infrastructure for a future where intelligence itself becomes an asset class. Not software in the traditional sense, but something closer to productive digital capital. Models generate outputs. Agents perform tasks. Data continuously improves systems. Economic rewards circulate across networks instead of terminating inside centralized platforms.
That possibility changes how AI should be understood. The next stage of artificial intelligence may not simply be about building smarter systems. It may be about designing ownership structures around those systems before they become too deeply embedded into society to challenge.
OpenLedger is ultimately trying to answer a question that the technology industry has avoided for years: when machines generate enormous value from human knowledge, who deserves to participate in the upside?
That question is not going away. If anything, it is becoming the defining economic question of the AI age.
