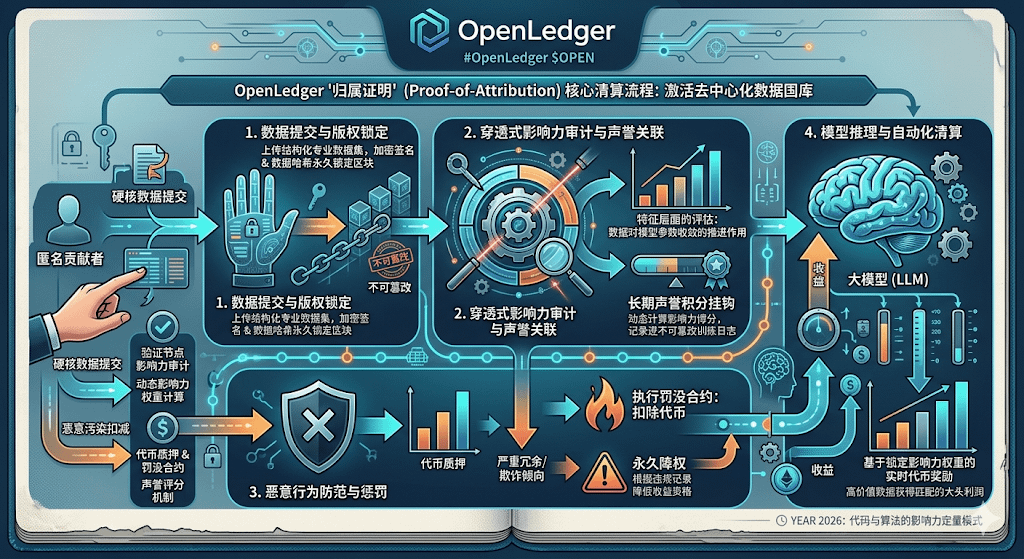
说到底,现在很多人天天在嘴上聊着如何用去中心化网络去对抗科技大厂的中心化大模型,但很少有人能说明白,如何让那些天南海北的匿名贡献者把自家手里真正有价值的专业数据给拿出来。大家最担心的,无非就是自己的核心成果被平台白白拿去喂了算法,最后却分不到半点利润。@OpenLedger OpenLedger 这次抛出来的归属证明机制,本质上是在用密码学手段,给每一个最原始的数据输入和最终的模型推理结果之间,强行焊接了一条不可篡改的账本因果链。
这套清算逻辑在实际跑起来的时候,被拆成了几个极其硬核的确定性步骤。首先在数据提交阶段,贡献者上传的数据集绝对不能是那种从网上随便爬来的垃圾信息,必须是针对特定垂直领域做过结构化处理的干货。而且这个行为本身就是原生的链上事件,你的加密签名和数据哈希会直接在区块里锁死,谁也别想在事后抹去你的版权贡献。
紧接着就进入了最考验算法底层功底的影响力审计阶段。系统不会对所有上传的数据一视同仁,而是会根据元数据进行特征层面的穿透式评估,去算一算你这点数据到底对模型最终的参数收敛起到了多大的推进作用。同时,这个过程还会跟数据提供者地址的长期声誉积分挂钩。这些动态计算出来的影响力得分,会直接作为核心参数被记录进不可篡改的训练日志里,变成后续利益分发的硬性依据。
等到模型开始向外部提供推理调用并产生收益时,真正的链上自动化清算就触发了。系统会根据之前在日志里锁死的影响力权重,把对应的代币奖励实时打进那些早期贡献者的钱包。这种根据实际产出效益来决定分发额度的做法,最大程度地确保了高价值的数据能够拿到与其质量相匹配的绝对大头利润。
不过,最让我觉得这个协议有实战质感的地方,在于它引入了针对恶意污染的扣减惩罚逻辑。去中心化网络最怕的就是羊毛党用各种AI生成的废话或者带有偏见的敌对数据来恶意刷量。在这里,所有的提交行为往往都需要提前进行代币质押。一旦后台的验证节点发现你上传的内容存在严重的冗余或者欺诈倾向,系统会毫不犹豫地直接执行罚没合约,把你的质押代币给扣掉。要是某个地址的违规记录超过了安全阈值,它以后在这个网络里的收益资格就会被永久降权。
这种用经济收益和惩罚高压双向驱动的闭环流程,确实在无需信任的分布式环境下,构建出了一套能够自我净化的数据国库。但说实话,在 2026 年这个复杂的环境下,这种完全由代码和算法来进行影响力定量的模式,还是挺让人捏一把汗的。#OpenLedger $OPEN