

When I first started reading the documents and technical explanations around @OpenLedger one thing immediately stood out to me: the team seems more focused on making AI infrastructure actually usable rather than simply adding another layer of complexity to Web3. And honestly, that matters more than most people think.
A lot of crypto infrastructure projects fail for a simple reason. They build impressive systems that regular developers never consistently use. The tooling becomes too fragmented, onboarding becomes painful, and eventually the “innovation” turns into another dashboard people stop opening after the first week.
This problem feels even bigger now in AI and Web3.
Today, developers are dealing with scattered APIs, expensive model access, different hosting environments, and complicated integrations just to test one AI-powered application. Even users experience this indirectly.Most people don’t care what chain,model, or backend powers an app. They only care whether it works smoothly and saves time.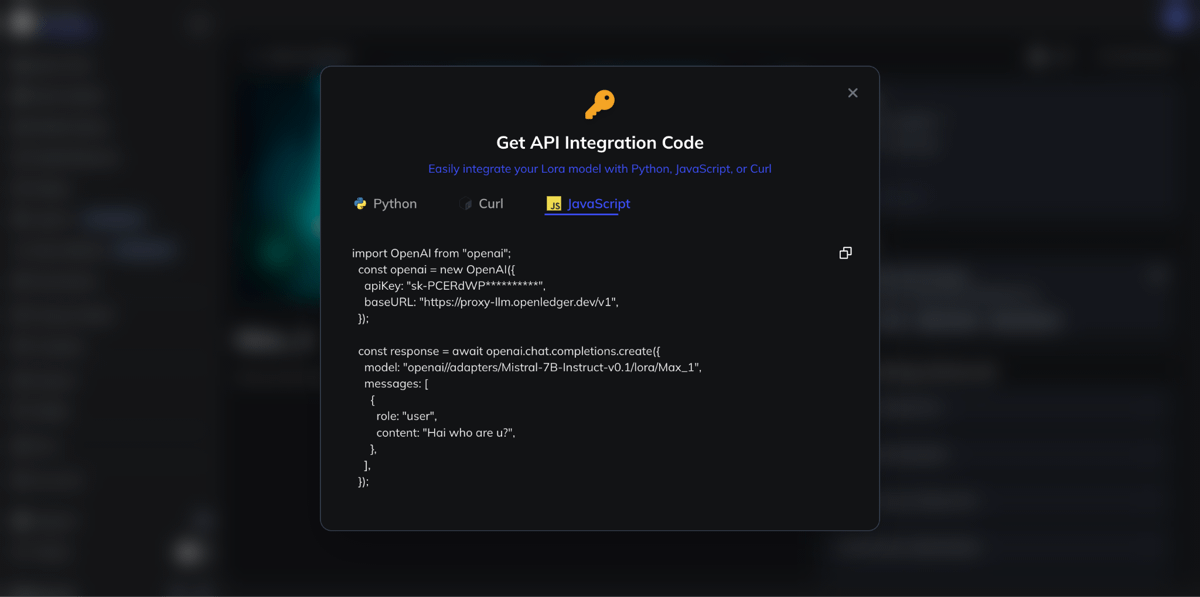
That is why I found the API integration layer of OpenLedger more interesting than the usual infrastructure announcements we see every month.
Instead of treating AI like a separate experimental feature,OpenLedger appears to position it as something developers can access in a practical and structured way.Their API integration approach is surprisingly straightforward.
For example, the Python integration uses the familiar OpenAI client structure.That sounds small, but it reduces friction immediately. Developers already comfortable with existing AI SDK workflows do not need to learn an entirely new architecture.They simply configure a base_url, provide an api_key, and specify the model path connected to OpenLedger-hosted models.
That kind of compatibility matters because most builders do not want to spend weeks adapting infrastructure before testing an idea.
The same pattern continues with their JavaScript and Node.js integrations.Again, the structure feels intentionally familiar. Async workflows, chat completions, and standard request methods make the transition easier for frontend developers and AI tool builders. I think this is one of the smarter decisions OpenLedger made.
Because honestly, developer experience in Web3 is still unnecessarily difficult.
Many infrastructure protocols talk about decentralization but forget that simplicity is what creates repeated usage.If developers cannot integrate quickly, the ecosystem never grows beyond early adopters.
The curl support also caught my attention for a different reason.
Sometimes raw HTTP access is still the best way to test systems, automate workflows, or debug integrations inside production environments. OpenLedger supporting direct request structures without forcing heavyweight SDK dependencies shows they understand real-world usage patterns.
And this connects to a larger question I keep thinking about:
Do AI agents actually improve workflows, or are we just creating more noise?
I think the answer depends entirely on infrastructure quality.
If AI tools increase complexity, users eventually ignore them. But if integrations reduce repetitive tasks, simplify access to models, and allow builders to launch ideas faster, then the infrastructure becomes invisible in the best possible way.
That may be where OpenLedger could realistically fit.
Not as another hype-driven “AI chain,” but as infrastructure that quietly helps builders deploy, test, and manage AI interactions without constantly rebuilding backend systems from scratch.
I also think the on-chain aspect is important, although people should stay realistic about it.
OpenLedger talks about Datanets,model training, deployment, governance, and tokenized interaction. In theory, this creates transparency around how AI systems are built and used. But theory alone is never enough in crypto. Sustainable ecosystems only survive when users repeatedly return because the tools genuinely improve behavior.
That is the difficult part.
Keeping infrastructure reliable in crypto is extremely hard because markets change quickly while developer expectations keep increasing. Many projects launch with strong narratives but fail when maintaining performance, integrations, or community trust becomes expensive over time.
So I do not think success for $OPEN depends on short-term speculation.
I think it depends on whether developers quietly continue building on top of the ecosystem six months later.
Will builders save time?
Will integrations remain stable?
Will AI agents become practical tools instead of distractions?
Will users interact with applications powered by OpenLedger without even noticing the infrastructure underneath?
Those are the questions that matter more than token excitement.
Personally, after reading through the API integration approach and the broader infrastructure direction, I think OpenLedger is at least trying to solve a real operational problem instead of inventing artificial utility.
That does not guarantee success.
There is still execution risk, adoption risk, and the challenge of competing in an overcrowded AI infrastructure market.But compared to many Web3 projects that focus entirely on narratives, OpenLedger feels more grounded in actual developer behavior.
And in the long run, infrastructure usually wins only when people stop talking about it and simply keep using it.
