When AI gets something wrong, most people blame the model. And honestly, that reaction makes sense. The model is the part we see. It is the one answering questions, explaining ideas, and sounding confident while doing it. So when it gives a false answer, the first thought is usually, “The model failed.” Sometimes that is true. But it is not the whole story.
A lot of AI misinformation starts much earlier, before the answer ever appears on the screen. It starts with the data. The articles, posts, comments, reports, research, opinions, recycled content, and sometimes low-quality information that models learn from or connect to all shape the final output. If that data is biased, outdated, fake, incomplete, or manipulated, the model is already working with weak material.
That is the uncomfortable part. A powerful AI system can still repeat bad information if bad information helped shape it. It may sound polished. It may sound smart. It may even sound more confident than a human expert. But confidence does not equal truth. Bad data goes in, and confident misinformation can come out.
So the real question is not only, “How do we make the model smarter?” The deeper question is, “Who is responsible for the data feeding it?” Because if nobody is accountable for the quality of the data, then misinformation becomes much harder to control.
AI misinformation does not begin when a chatbot writes the wrong sentence. It begins before that. It may begin with an old medical article that was never corrected, biased political content pretending to be neutral, clickbait financial advice being shared again and again, or low-effort AI-generated posts being copied and pushed back online like fresh knowledge.
You have probably seen this happen. One weak claim gets repeated enough times, and suddenly it starts to feel familiar. Familiar begins to feel believable. Then an AI system picks up that pattern, and the same weak claim comes back to users in a clean, confident voice. That is what makes AI misinformation so dangerous. It does not always look messy. It does not always sound like spam. Sometimes it sounds calm, professional, and convincing.
This is why the data layer matters so much. Most AI discussions focus on the model itself. Bigger models, faster models, better agents, stronger reasoning, better benchmarks, and more impressive demos. All of that matters, of course. But data often gets treated like background material, almost like raw fuel that the system simply consumes.
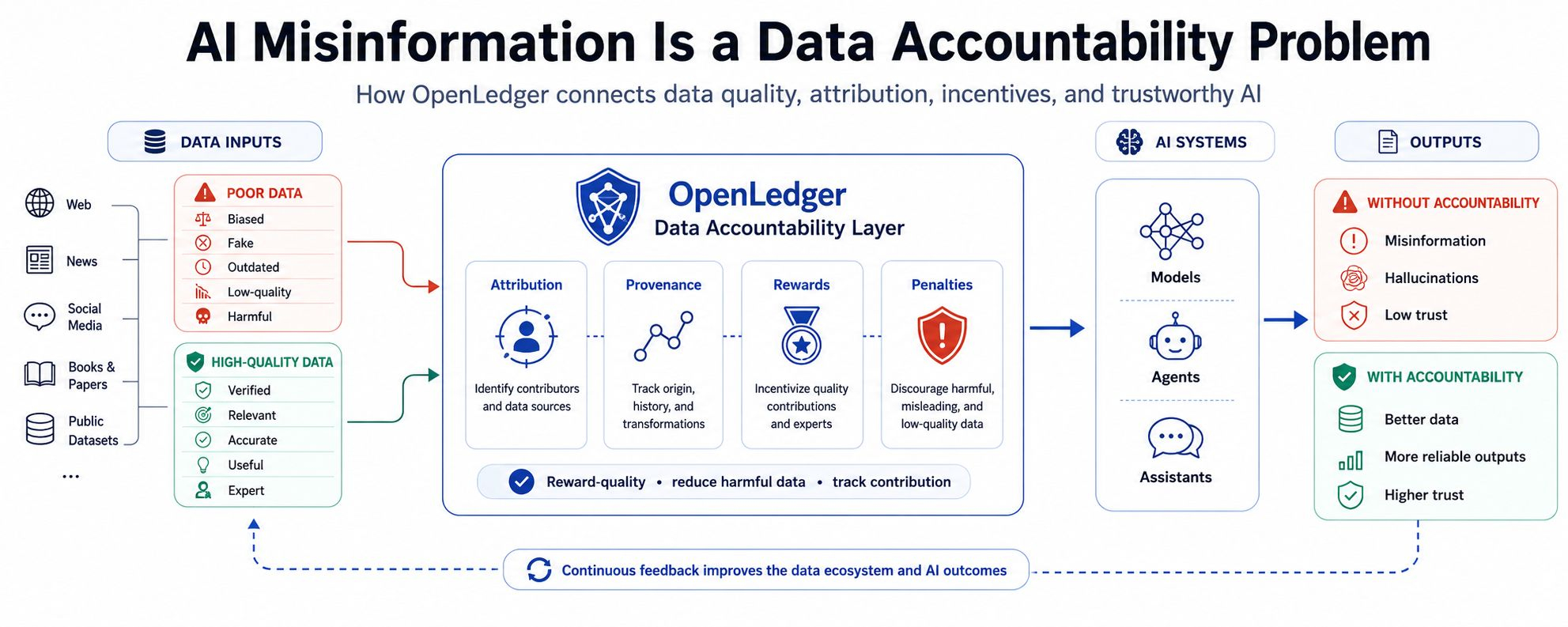
But data is not just fuel. Data comes from people, communities, creators, developers, researchers, platforms, companies, and sometimes bad actors. Some of it is useful. Some of it is weak. Some of it is harmful. Some of it is just noise dressed up as knowledge. If AI systems cannot clearly identify where information came from, who contributed it, whether it was accurate, and whether it helped or harmed the system, then trust becomes very difficult.
Without accountability, good contributors can disappear into the machine without recognition. Bad contributors can pollute the system without real consequences. And the model keeps learning from whatever is available. That does not feel sustainable. Honestly, it never really did.
This is where OpenLedger’s angle becomes important. The idea is not only about the model or the final AI output. It is about the data underneath. OpenLedger focuses on data accountability, meaning high-quality data should be recognized and rewarded, while low-quality, fake, or harmful data should not be treated the same way.
That sounds obvious, but the internet has often worked in the opposite direction. Online systems usually reward volume. Post more, generate more, get clicks, push content, keep attention. Whether the content is actually useful often becomes secondary. AI does not need more noise. It needs better signals.
A better AI data system should reward accuracy, usefulness, originality, and real value. If someone contributes data that helps improve AI performance, that contribution should matter. If someone contributes harmful or weak data, there should be a way to reduce its influence or penalize it. That changes the incentive game. Instead of rewarding people simply for producing more content, the system can reward people for contributing information that actually makes AI more reliable.
Think about healthcare for a moment. If an AI assistant learns from poor medical information, the result is not just a harmless mistake. It can become dangerous. Imagine someone asking about symptoms, medicine, or treatment options. The AI responds calmly and sounds reasonable. Maybe even reassuring. But if the underlying information came from outdated or unreliable health content, the advice could be wrong.
That is the scary part. Bad advice does not always sound bad. A better system would give more weight to verified medical knowledge, expert-reviewed information, and reliable health data. Fake cures, outdated claims, and random misinformation would lose influence. Would that fix everything? No, of course not. AI would still need human oversight, especially in serious fields. But it would create a cleaner and safer starting point.
The same idea applies to finance, law, education, news, and politics. In any area where wrong information can affect real decisions, data quality is not a small detail. It is the foundation. If the foundation is weak, the final answer can become weak too.
Of course, accountability is not easy. AI attribution is messy. A model usually does not pull from one neat source and say, “This exact answer came from this exact data point.” One response may be shaped by thousands or even millions of examples. So deciding who gets credit, how much credit they get, and based on what rules is complicated.
There is also the gaming problem. If rewards are connected to data influence, some people will try to manipulate the system. That is just how online incentives work. Someone always looks for the shortcut. That is why a data accountability system needs verification, reputation, review, rules, and strong safeguards. Attribution alone is not enough.
Governance also matters. Who decides what counts as high-quality data? Who decides what is harmful? Who handles disputes? Who makes sure the system itself does not become biased? These are not side issues. They are the hard part. Still, even with all these challenges, the direction makes sense because ignoring the data layer is clearly not working.
Better AI needs better incentives. If the system rewards low-effort content, people will create more low-effort content. If it rewards accuracy, originality, usefulness, and real expertise, people have a reason to contribute better information. That is not complicated. It is human behavior.
AI builders need to stop treating data like something that can be endlessly collected without responsibility. Data should be treated like critical infrastructure. It should be checked, ranked, attributed, and valued. Contributors should not remain invisible. If someone’s knowledge helps an AI model produce better answers, there should be a way to recognize that value.
Users also have a role, even if it is smaller. We need to become more comfortable asking where AI answers come from. Not every answer needs deep research behind it, obviously. But for health, money, law, safety, or anything serious, sources and data quality matter. A confident answer is not the same as a trustworthy answer.
AI misinformation is not just a technical bug. It is a trust problem. And trust will not be fixed only by making models bigger, faster, or more impressive. If poor data enters the system, unreliable outputs will follow. If valuable contributors are ignored, the best information may not get the value it deserves. If harmful data has no penalty, misinformation becomes easier to scale.
That is why the data accountability angle matters. It shifts the conversation from “How smart is the model?” to “How responsible is the data ecosystem behind it?” And honestly, that may be one of the most important questions in AI right now. The future of AI will not depend only on intelligence. It will depend on accountability too.