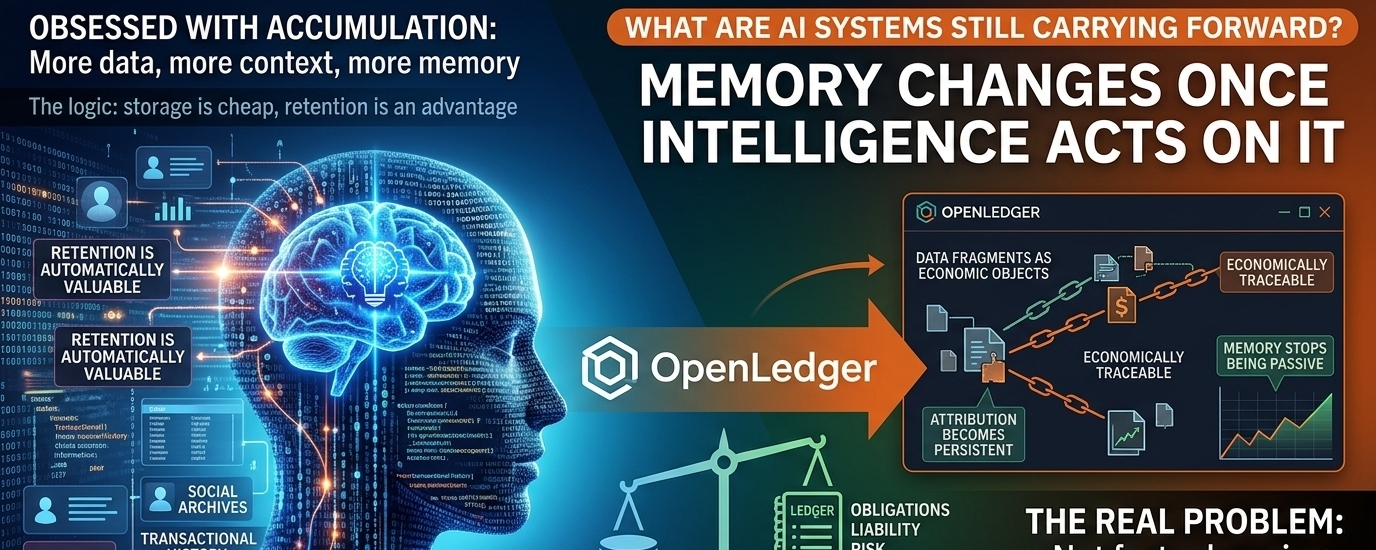
@OpenLedger One thing I keep coming back to whenever I look at AI infrastructure is how obsessed the market is with accumulation. More data, more context, more memory, more behavioral signals, more historical understanding. Almost every major system being built today operates on the assumption that retaining information is automatically valuable. Social platforms archive years of user behavior because it may become useful someday. Financial applications hold records indefinitely because future analysis might depend on them. AI systems absorb conversations, preferences, workflows, and interactions under the belief that intelligence improves as memory expands. For a long time that logic felt reasonable. Storage was cheap, regulation moved slowly, and most companies treated retention as a competitive advantage instead of a liability. But the closer AI moves toward real operational authority, the less confident I am that unlimited memory is actually an asset.
Because memory changes once intelligence begins acting on it.
That is partly why OpenLedger keeps standing out to me, although not in the same way it seems to stand out to most people. The common interpretation is simple enough. OpenLedger is usually described as an AI data infrastructure layer where contributors provide useful datasets, developers build models on top of those contributions, and $OPEN coordinates incentives and attribution across the network. Clean narrative. Familiar crypto structure. Easy to understand. But I think there is a deeper tension sitting underneath the surface that people are barely talking about.
What if the real problem AI infrastructure needs to solve is not helping systems learn faster, but helping them forget correctly?
That sounds philosophical at first, but it becomes extremely practical once you think about how modern AI systems actually function. Information does not remain isolated after it enters a model ecosystem. Data moves through training pipelines, fine-tuning processes, retrieval systems, embeddings, recommendation layers, and behavioral logic. Once something influences a machine’s intelligence, removing it later is not nearly as straightforward as deleting a file from cloud storage. People outside technical circles often imagine deletion as a clean reset. In reality, machine memory behaves more like diffusion. Information spreads into the architecture itself. That creates a very uncomfortable problem: teaching machines is relatively easy compared to making them forget with precision.
I remember reading discussions around machine unlearning some time ago, and what struck me was not the sophistication of the research, but the implication behind it. The entire field quietly acknowledges that modern AI systems are becoming capable of carrying information in ways that are difficult to unwind. That matters far more now than it did even a couple of years ago because AI is no longer confined to experimental tools and consumer novelty. It is moving into environments tied to identity, payments, internal enterprise operations, compliance systems, healthcare workflows, legal review, and eventually decision-making structures where mistakes carry financial or regulatory consequences.
At that point the conversation changes completely.
The question is no longer whether a model performs well. The question becomes what exactly that model is still carrying forward from the past.
That is where OpenLedger becomes genuinely interesting to me. If attribution becomes persistent and economically traceable, then retained memory stops being free infrastructure. Memory becomes an accountable economic object. And once memory becomes economically visible, retention itself starts carrying weight.
That changes incentives in a way I do not think the broader market has fully priced yet.
Right now the AI economy largely rewards retention. More context means better personalization, smoother continuity, stronger outputs, and more adaptive systems. The assumption underneath everything is that remembering is beneficial. But once contributors, provenance, ownership, and compensation become attached to retained intelligence, memory stops being passive. It starts generating obligations. And the moment memory generates obligations, forgetting becomes economically rational instead of technically inconvenient.
That shift feels much bigger than most people realize.
Imagine an enterprise AI assistant trained partly on sensitive customer interactions. Months later, a client changes permission terms. Regulations evolve. A compliance department decides that historical interactions create exposure. Suddenly the issue is not simply whether logs can be removed from storage. The deeper issue is whether intelligence shaped by those interactions should still remain active inside the system itself. That is a far messier problem than most AI narratives currently acknowledge.
Healthcare probably makes this tension even more uncomfortable. Financial advisory systems too. But honestly, even ordinary autonomous agents create the same structural issue. The more software learns behavioral patterns about users, counterparties, transaction habits, negotiation styles, or operational history, the more valuable that memory becomes. At the exact same time, the risk attached to that memory also increases. Useful memory and dangerous memory often look identical right up until something breaks.
Oddly enough, crypto people may understand this contradiction earlier than most industries because blockchain already experienced its own collision between permanence and reality. Immutable ledgers sounded revolutionary when the conversation was mostly theoretical. But once privacy, regulation, and legal accountability entered the picture, permanence stopped sounding universally positive. AI may be approaching a similar realization now. Systems built to remember everything eventually run into environments where forgetting becomes necessary.
And OpenLedger sits surprisingly close to that pressure point.
Attribution systems do something subtle but important. They make memory legible. Once memory becomes legible, it becomes challengeable. Ownership disputes emerge. Compensation claims emerge. Compliance questions emerge. Liability becomes easier to identify. None of that automatically guarantees OpenLedger solves these problems, of course. I think markets often move too quickly from elegant architecture diagrams to assumptions of inevitability. Tracking provenance is one challenge. Enabling meaningful machine forgetting without destabilizing intelligence is a completely different one.
The economics are not simple either.
A lot of crypto infrastructure projects sound compelling until the uncomfortable demand question appears. Why does the token sustain long-term organic pressure instead of temporary speculation? If $OPEN becomes deeply tied to attribution persistence, access coordination, or data-linked economic routing, then perhaps there is a real structural loop supporting it. But there is also a real possibility that incentive systems become too complicated for practical adoption. Enterprises often choose operational simplicity over ideological elegance. If attribution creates recurring compensation complexity around every retained contribution, some operators may decide private infrastructure is easier to control.
That risk feels very real to me.
I also think the governance side becomes incredibly difficult once forgetting carries economic consequences. Who ultimately decides what should remain active inside a system? The original contributor? The model developer? The enterprise using the model? Regulators? Compliance teams? Those groups are not going to agree consistently, especially when financial incentives are attached to retention.
Which is exactly why this conversation matters.
The AI market still behaves as though intelligence itself is the scarce resource. Smarter outputs, larger models, stronger reasoning, more capable systems. But increasingly I think responsibility may become scarcer than intelligence. Models will continue improving. Computational power will continue scaling. Data generation will continue accelerating. The harder challenge may become controlling what systems are allowed to carry forward and who becomes accountable for the consequences of retained memory.
That is why OpenLedger feels more important than the surface-level narrative suggests.
Maybe it remains exactly what most people currently describe it as — a tokenized AI contribution network with attribution infrastructure attached to it. That alone would already place it inside an important category. But the more interesting possibility is much less comfortable. OpenLedger may eventually become part of the infrastructure layer that determines what AI systems are allowed to remember, how long they are permitted to remember it, and who continues benefiting economically while that memory remains alive.
And honestly, markets usually underestimate uncomfortable problems right until they become unavoidable.