Bigger models. Bigger datasets. More computing power. More parameters. Every few months another company shows up claiming their newest AI can basically handle everything now — writing code, analyzing markets, answering legal questions, summarizing research papers, creating marketing plans, generating images, helping students study, maybe even replacing search engines altogether.
And honestly, when this wave first started, it felt incredible to watch.
You could open a chatbot and ask it almost anything. One minute it was explaining black holes. The next it was helping draft emails or debugging Python code. For a lot of people, it felt like the beginning of some giant universal intelligence that could eventually handle nearly every digital task humans do.
But then something interesting happened once AI started leaving the “cool demo” phase and entered actual industries.
Hospitals started testing AI systems. Financial firms started experimenting with AI-driven analysis. Legal companies began using AI for research and document review. Software teams integrated coding assistants into real development environments. Research organizations started using AI for scientific workflows.
That’s where the conversation started changing.
Because there’s a huge difference between an AI that sounds smart and an AI you’d genuinely trust in situations where mistakes actually matter.
And honestly, I think that’s the point where people started realizing something important:
Maybe the future of AI doesn’t belong to one giant model trying to know everything.
Maybe it belongs to specialized intelligence instead.
The more you think about it, the more logical that idea starts to feel.
Humans don’t become experts by learning everything equally. A surgeon spends years focused on medicine. A lawyer studies legal systems in detail. Financial analysts spend entire careers understanding markets and risk. Software engineers think differently from scientists. Expertise usually comes from depth, not breadth.
AI is starting to run into the same reality.
General AI models are impressive because they can discuss almost anything. But when industries need precision, context, and reliability, broad intelligence alone often isn’t enough.
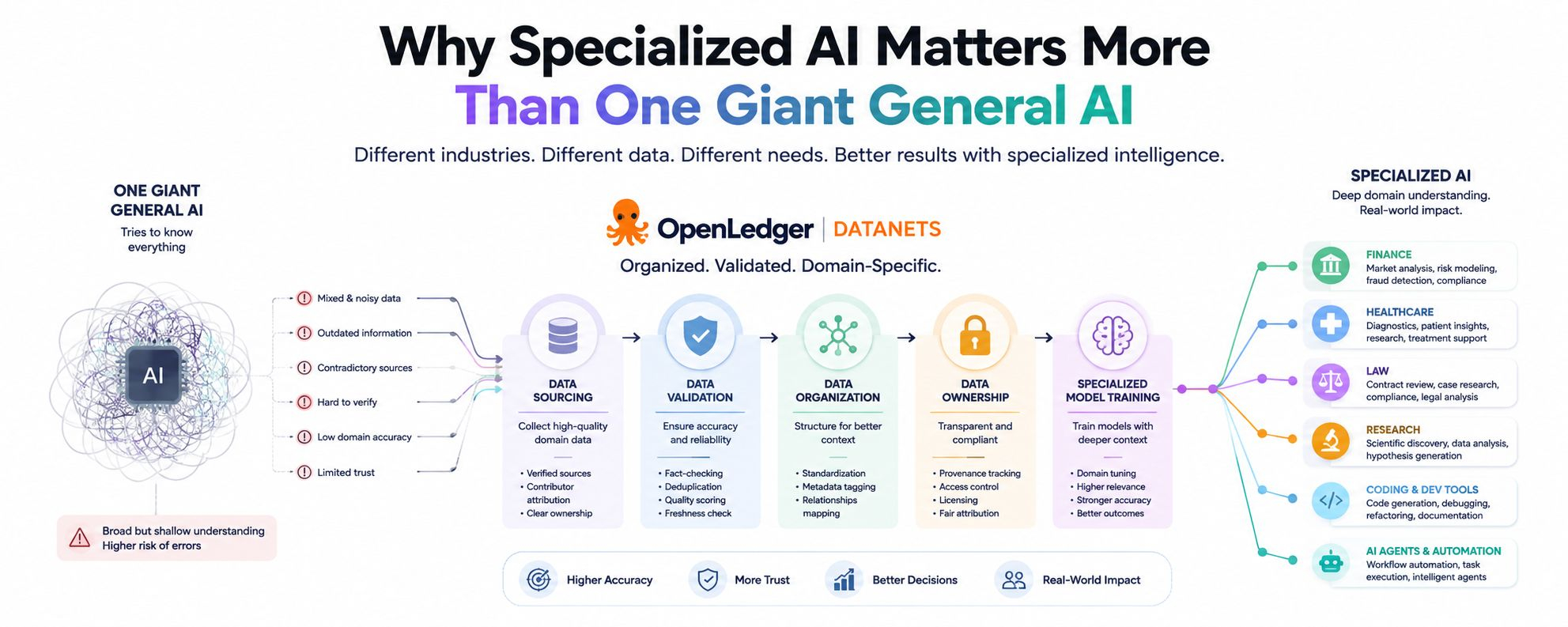
And that’s exactly why projects like and its Datanets concept are becoming interesting. Instead of relying entirely on massive internet-scale data scraping, the focus shifts toward organizing and validating domain-specific datasets designed for specialized AI systems.
That shift may end up being one of the biggest changes in the entire AI industry.
Because right now, most general AI systems learn from enormous amounts of mixed internet content — articles, books, blogs, forums, social media posts, code repositories, PDFs, random conversations, and everything in between. That broad exposure helps them sound intelligent across many topics.
But there’s a problem people don’t always notice immediately.
The internet is messy.
Really messy.
There’s misinformation everywhere. Outdated information. Contradictory opinions. Low-quality content written purely for clicks. Half-correct explanations repeated thousands of times until they look authoritative. And AI models absorb all of it.
That’s part of why general AI sometimes produces answers that sound polished and confident while still being wrong.
And honestly, that confidence can become dangerous in serious industries.
We’ve already seen cases where lawyers submitted AI-generated legal citations that didn’t actually exist. Medical AI chatbots have provided advice doctors later flagged as inaccurate or risky. Financial summaries generated by AI have included outdated assumptions or incorrect interpretations presented confidently enough that non-experts wouldn’t immediately notice the issue.
That’s the weird thing about modern AI.
The mistakes usually don’t look like mistakes.
They’re written clearly. Smoothly. Confidently.
Which sometimes makes them more convincing than they should be.
If an AI gives you a bad movie recommendation, nobody cares. If it misunderstands a medical condition, a legal contract, or a financial risk assessment, suddenly the stakes become very different.
That’s why industries are slowly shifting toward specialized AI systems trained on domain-specific knowledge instead of relying purely on giant general-purpose models.
Healthcare is probably the clearest example of this.
People talk about AI in medicine almost constantly now, and to be fair, the potential really is enormous. Faster diagnostics. Better patient support systems. Smarter medical research. AI-assisted imaging analysis. Reduced administrative overload for healthcare workers who are already stretched thin.
But healthcare is also one of the least forgiving environments imaginable.
A small mistake can become a serious problem incredibly fast.
If an AI system misunderstands symptoms, mixes up medication interactions, or overlooks something critical in patient records, that isn’t just an annoying software error. Real people can be affected by those mistakes.
So hospitals and medical organizations don’t necessarily want an AI trained on random internet health discussions. They want systems trained on clinical records, peer-reviewed journals, pharmaceutical databases, medical imaging datasets, diagnostic protocols, and structured healthcare workflows.
That difference matters more than people realize.
An AI system built specifically for radiology, for example, can become extremely effective at identifying patterns in X-rays or MRI scans because it’s trained deeply within that environment. Same thing with pathology systems, genomic analysis tools, or drug discovery models.
And honestly, that’s probably how long-term trust gets built in healthcare AI — not through giant “everything models,” but through focused systems that become highly reliable in narrow but critical areas.
Finance runs into almost the exact same issue.
General AI can absolutely help summarize reports, explain economic concepts, or assist with research. But when financial institutions start relying on AI for risk management, trading insights, fraud detection, compliance analysis, or market forecasting, broad internet-trained intelligence starts looking less reliable very quickly.
Finance depends heavily on context. Timing. Structured data. Regulations. Historical behavior patterns. Tiny details can completely change outcomes.
And financial firms don’t just need answers. They need explainability too.
If an AI recommends a certain action involving millions of dollars, institutions need to understand why. Regulators care about transparency. Investors care about accountability. Risk teams need traceable reasoning.
Nobody serious in finance wants to hear:
“The AI thought this looked right.”
That’s why specialized finance AI systems trained on financial filings, trading behavior, economic reports, market data, and regulatory frameworks are becoming increasingly important.
Same thing is happening in law.
From the outside, legal work sometimes looks straightforward. But once you start dealing with real contracts, legal research, compliance rules, or case law, you realize almost everything depends on nuance.
A single sentence can change the meaning of an agreement entirely. Jurisdictions matter constantly. Context matters constantly too.
General AI models can explain legal concepts fairly well. But actual legal work requires a different level of precision entirely.
Lawyers reviewing contracts or preparing filings don’t just need fluent writing. They need accurate references, jurisdiction-specific understanding, consistency, and reliable reasoning.
And hallucinations become especially dangerous in legal environments because fabricated information often looks legitimate at first glance.
That’s why specialized legal AI systems trained on verified legal databases and structured regulatory material are becoming much more valuable than broad conversational models alone.
Once you look across industries, the pattern becomes hard to ignore.
Healthcare needs medical expertise.
Finance needs financial expertise.
Law needs legal expertise.
Research needs scientific expertise.
Coding systems need deep technical understanding.
Different industries require different kinds of intelligence because they operate with different rules, risks, and expectations.
And honestly, this is where the conversation around AI starts becoming less about model size and more about data quality.
A couple years ago, most AI discussions focused on parameter counts and compute power. Bigger models were automatically viewed as smarter models.
Now the industry is slowly realizing something less flashy but probably more important:
Better data often matters more than bigger scale.
A smaller AI model trained on highly relevant, carefully validated, domain-specific information can outperform a massive general-purpose model in specialized tasks.
That changes the economics of AI completely.
Because computing power can eventually be replicated. Open-source AI keeps improving rapidly. Model architectures spread quickly across the industry.
But trusted, high-quality, domain-specific datasets?
Those are much harder to copy.
And that’s partly why structured data ecosystems like are getting attention. The entire idea revolves around organizing and validating specialized datasets so AI systems can operate with stronger relevance, clearer ownership, and better contextual understanding.
Honestly, the timing for this shift makes sense.
The AI industry still has major unresolved questions around data:
Who owns training data?
Was it verified?
Is it current?
Can contributors benefit from it?
How reliable are the underlying sources?
How do you ensure accountability?
Those questions become more important every time AI moves deeper into enterprise operations.
Because eventually businesses stop caring about flashy demos and start asking harder questions:
Can this system actually be trusted?
What was it trained on?
Can we verify its reasoning?
Can it operate safely inside our workflows?
And trust usually starts with the quality of the data underneath everything.
AI agents make this even more important.
Right now, one of the biggest trends in AI involves autonomous or semi-autonomous agents — systems capable of handling tasks, coordinating workflows, interacting with software, automating operations, and making decisions with minimal human involvement.
That sounds exciting. It also raises the stakes dramatically.
Because an AI agent managing healthcare administration, research analysis, legal workflows, or financial operations can’t rely on shallow internet-level understanding. If those systems make mistakes repeatedly at scale, automation quickly becomes a liability instead of an advantage.
The smarter AI agents become, the more important specialized infrastructure becomes too.
And honestly, we’ve already seen specialized AI systems outperform broader models in important areas.
DeepMind’s AlphaFold became one of the biggest breakthroughs in biology because it focused deeply on protein structure prediction using specialized scientific datasets. That wasn’t general intelligence trying to do everything. It was focused intelligence solving one difficult scientific problem extremely well.
Bloomberg created BloombergGPT specifically for finance-related tasks using financial datasets and market terminology. Naturally, it performed strongly in financial contexts because it was designed for that environment.
Even coding assistants like GitHub Copilot work largely because they’re deeply connected to software engineering workflows and programming-related data.
Developers don’t just need generic text generation. They need syntax awareness, debugging support, dependency management, framework understanding, and architecture-level reasoning.
That’s specialized intelligence.
And the more examples like this appear, the less realistic the “one AI that masters everything equally well” vision starts to feel.
Maybe the future of AI isn’t one giant universal system replacing all expertise.
Maybe it’s networks of specialized systems working together instead.
Honestly, that feels much closer to how humans operate anyway.
Of course, specialized AI comes with its own challenges too.
Building high-quality domain-specific datasets is difficult. Sometimes extremely expensive. Many industries protect their data aggressively for competitive or privacy reasons. Healthcare data becomes complicated quickly because of regulations and patient confidentiality. Financial data is sensitive. Legal systems vary across jurisdictions.
Then there’s the infrastructure side of everything.
Managing multiple specialized AI systems requires governance layers, security controls, integration frameworks, validation processes, and oversight mechanisms. None of that is particularly glamorous, but it matters enormously.
Still, despite those challenges, the specialized AI direction feels more grounded than expecting one universal AI model to perfectly understand every industry, every workflow, every regulation, and every context all at once.
General AI will absolutely continue to matter. Probably a lot.
Most people will interact with broad AI assistants daily because they’re flexible, fast, and genuinely useful across many casual tasks.
But underneath those systems, the real long-term value may increasingly come from specialized intelligence built on trusted data ecosystems.
Not the AI that vaguely knows everything.
The AI that understands the right things deeply enough to actually be reliable when it matters most.p