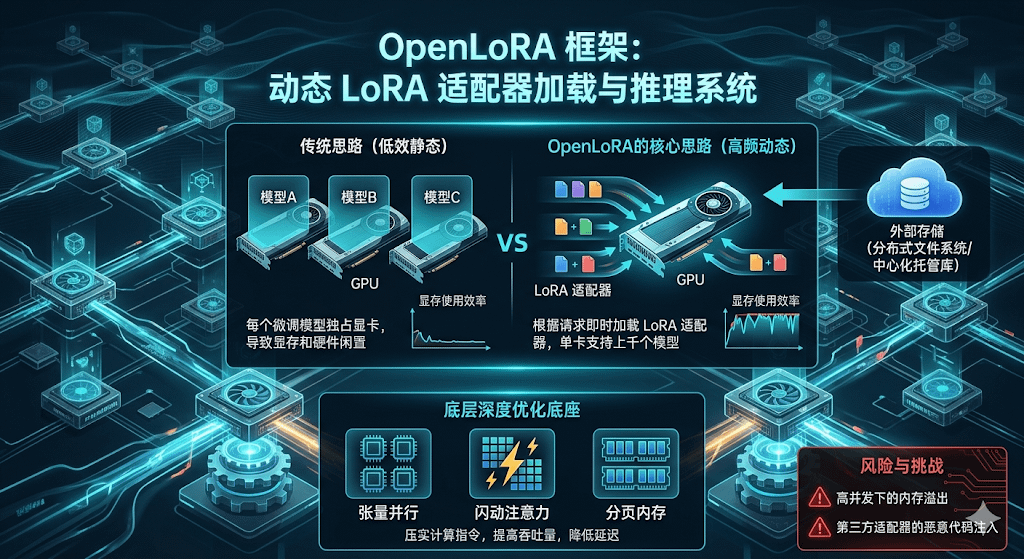

在 2026 年去中心化算力清算的真实博弈中,硬件的闲置和带宽的内耗一直是阻碍分布式 AI 基础设施大规模商业化的最大顽疾。@OpenLedger OpenLedger 这次推出的 OpenLoRA 框架,本质上是在用一套高频的状态调度逻辑,去解决链上多节点在承载海量个性化模型时面临的显存红线问题。传统的思路是每一个微调出来的模型都要在显卡里单独占一个坑,这种低效的堆硬件做法,在强调投入产出比的 Web3 账本里简直就是财务灾难。
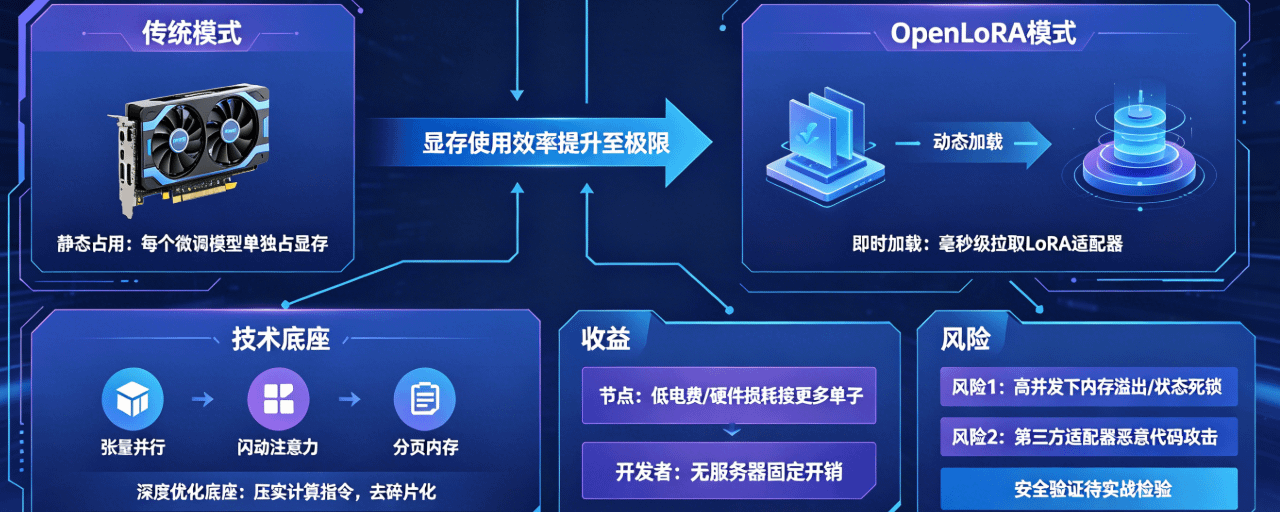
这个框架最核心的解题思路在于它把静态的硬件占用变成了动态的即时加载机制。它允许节点在接收到链上推理请求的毫秒瞬间,直接从外部分布式文件系统或者中心化托管库里,把对应的低秩自适应权重也就是 LoRA 适配器给拉进计算队列。这种即时加载的做法,让单张显卡不需要预先在显存里塞满成百上千个不常用的模型,而是根据实际的流量请求进行高频的切片替换。这直接把显存的使用效率拉到了极限,让散户手里的单张显卡同时跑上千个微调模型变成了一种确定性的工程现实。
为了在极端的网络压力下依然保证清算速度,该框架在底层堆砌了包括张量并行、闪动注意力和分页内存在内的一整套深度优化底座。这些技术手段在实际运行中扮演的角色,就是把原本松散的计算指令集进行无差别的压实和去碎片化,从而在不堆砌物理显卡的前提下,强行拉高了网络的整体吞吐量并缩短了响应时滞。对于那些需要频繁切换模型逻辑的跨链自动化清算协议或者高频游戏代理来说,这种底层的性能释放直接把每一次交互的 Gas 成本和计算溢价给打到了地板上。
通过这种把权重参数拆碎、再进行高频动态并网的玩法,去中心化算力网络终于在账本层面上跑出了具有碾压性的成本优势。贡献算力的节点可以用更低的电费和硬件损耗去接更多的推理单子,而开发者也不用为了发布一个垂直领域的应用去支付昂贵的服务器固定开销。
不过,这种把所有赌注都押在动态加载和高频切换上的架构,在 2026 年如此复杂的网络对抗环境下,也有一些让人捏一把汗的隐患。当成百上千个不同的地址同时发起异构推理请求时,节点在短时间内进行密集的适配器拉取和显存擦写,会不会导致底层驱动发生偶发性的内存溢出或者状态死锁?而且说真的,如何去验证每一次即时拉取的第三方适配器里没有夹带恶意的溢出攻击代码,这套去中心化清算网络可能还得在接下来的高并发实战中多掉几次链子才能真正把安全补丁给打全。$OPEN #OpenLedger