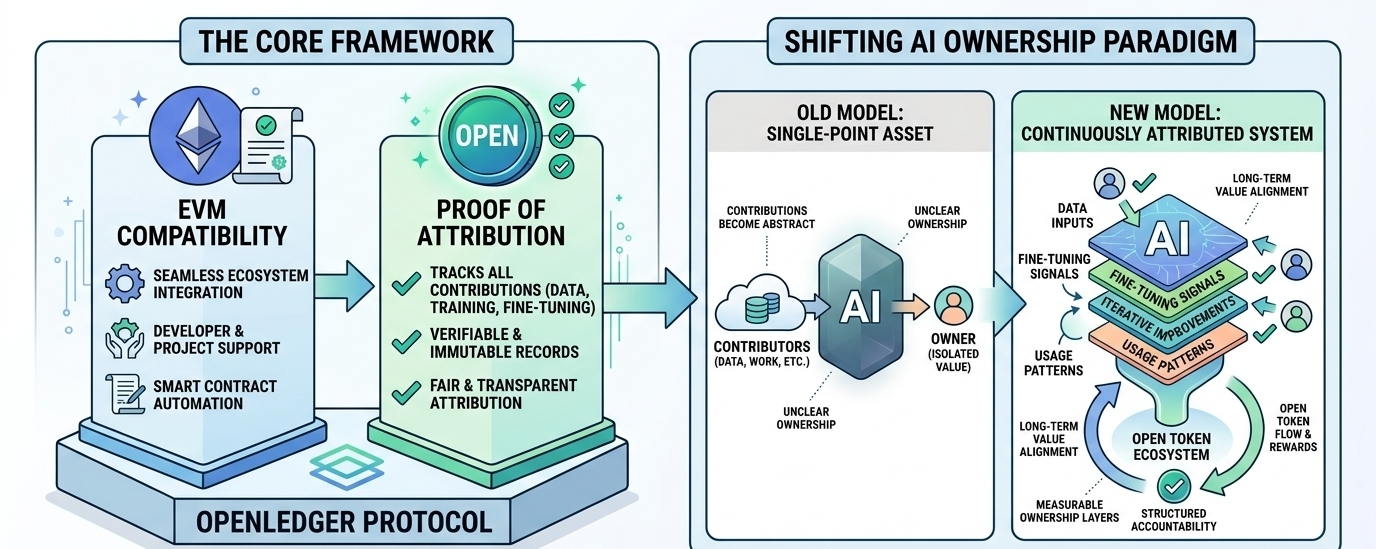
I noticed something interesting while thinking about how AI systems are actually built and used today. Most people interact with models as if they are standalone products, but the value behind them is usually far more distributed data, contributors, fine-tuning signals, and usage patterns all quietly shape the outcome.
The inefficiency is not in the models themselves, but in how little of that contribution is tracked or recognized. In most ecosystems, once an AI model becomes useful, the underlying sources that made it possible slowly disappear into abstraction. Ownership becomes unclear, and attribution becomes almost invisible.
The more I think about it, the more this feels like a missing layer in digital systems not computation, but accountability of contribution.
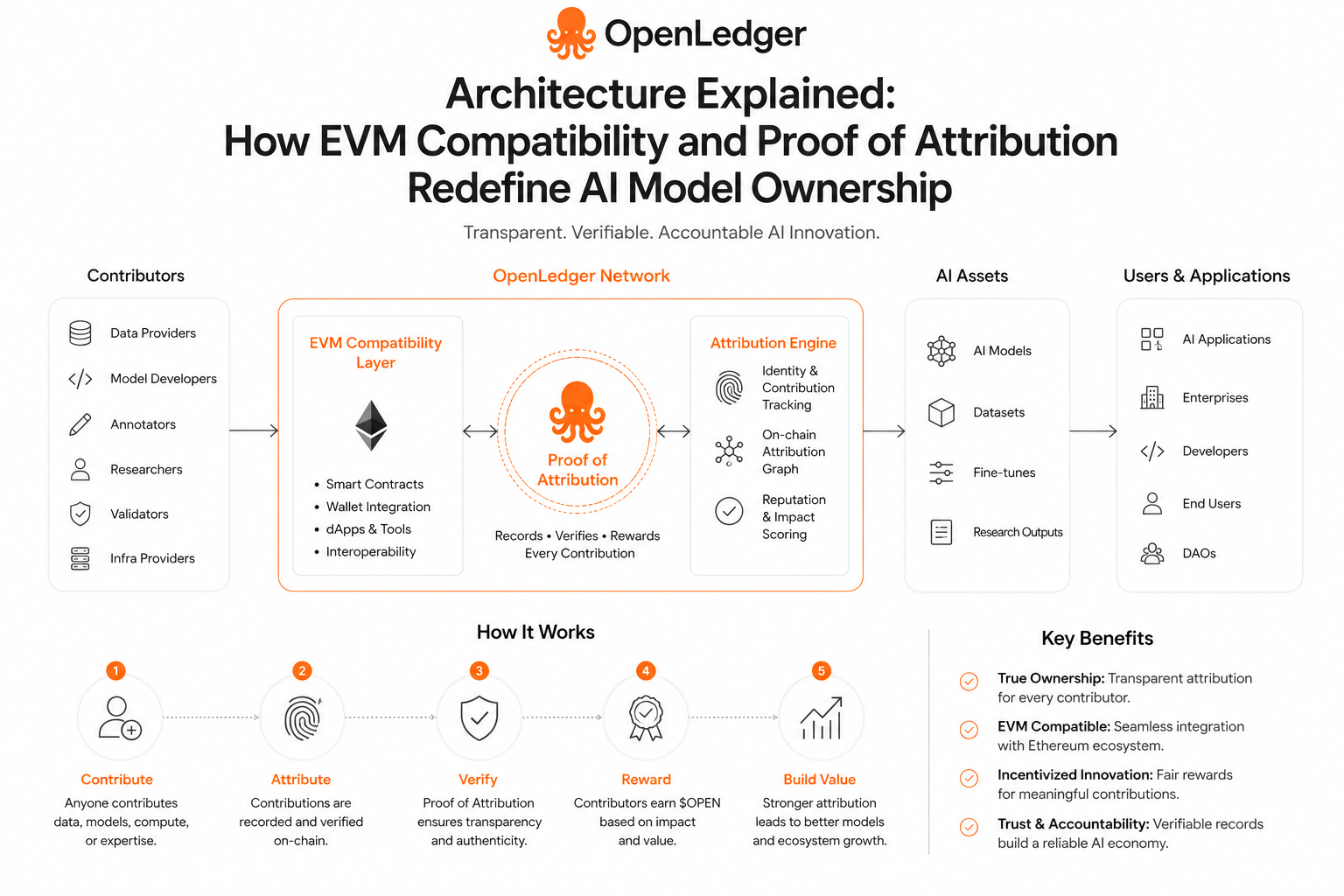
That’s where @OpenLedger becomes interesting in a structural sense. By combining EVM compatibility with Proof of Attribution, $OPEN introduces a framework where contributions to AI models are not just assumed, but recorded in a verifiable way. It changes the way we usually think about AI ownership, shifting it from a single-point asset to a continuously attributed system.
What’s interesting here is how this affects participation itself. When attribution is traceable, behavior naturally starts aligning with long-term value creation instead of short-term output. Time, training input, and iterative improvements begin to function almost like measurable layers of ownership.
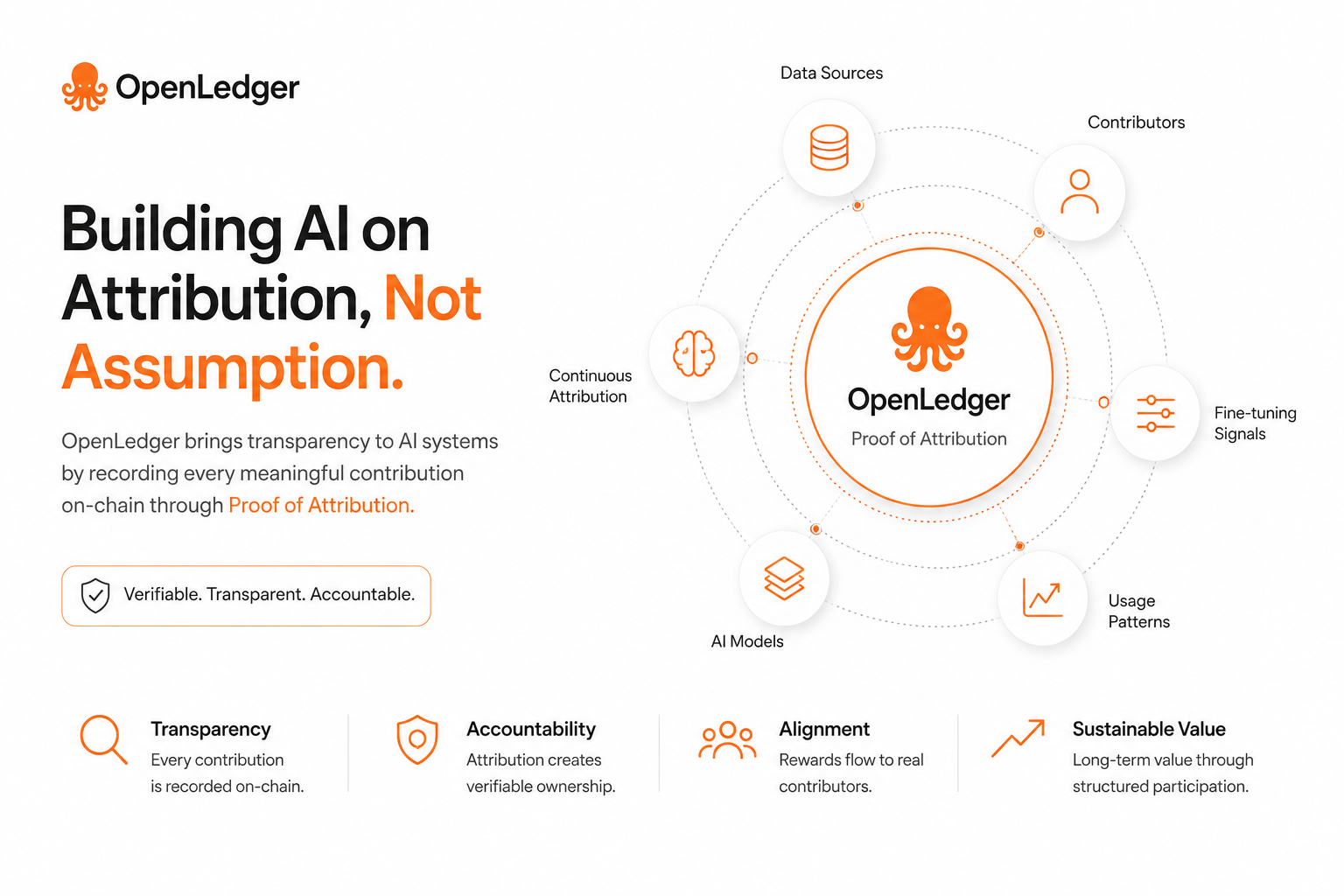
And that small shift in design can have bigger effects than it first appears.
The more I reflect on it, the more it feels like AI ecosystems are moving toward something closer to structured accountability where intelligence is not just used, but also traced back to how it was shaped.
Maybe that’s what systems like #OpenLedger are quietly experimenting with: turning contribution into something that can actually be seen, verified, and remembered.