But one of the biggest bottlenecks in AI right now isn’t intelligence.
It’s deployment cost.
That’s where OpenLoRA becomes interesting.
The current LoRA ecosystem is massively inefficient.
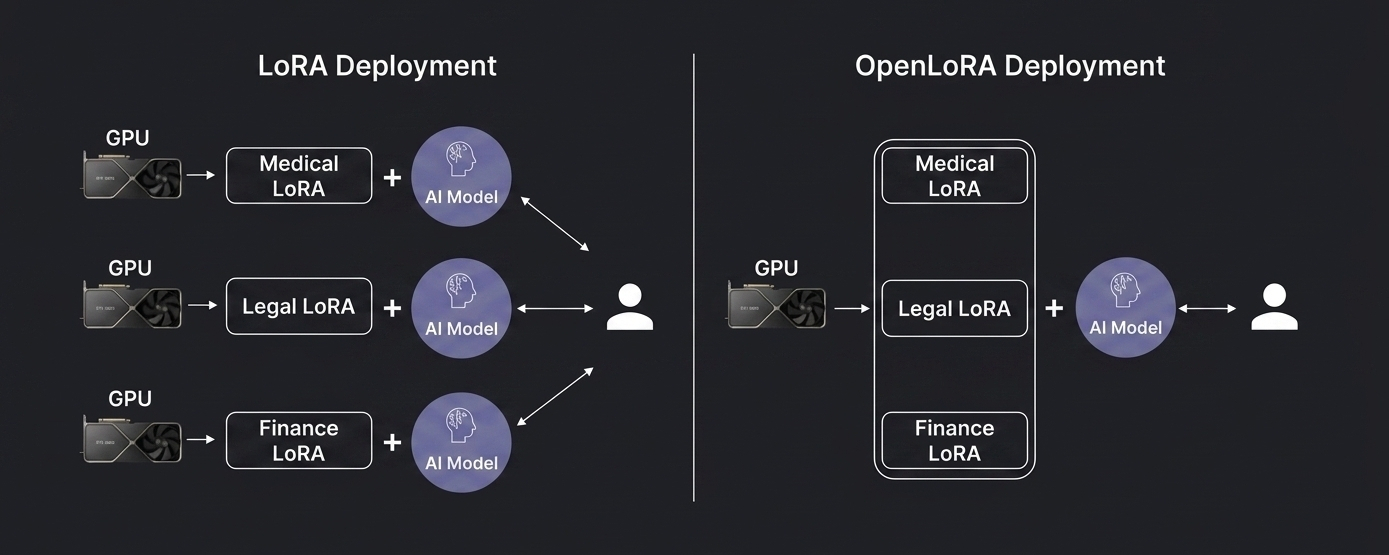
In a normal setup, every fine-tuned AI model often needs its own dedicated GPU environment:
• Medical LoRA → separate deployment
• Legal LoRA → separate deployment
• Finance LoRA → separate deployment
The problem is simple:
LoRA adapters are tiny.
Base models are huge.
The adapter might only be 10MB–100MB, while the underlying model can be 10GB–70GB+.
Yet most infrastructure stacks repeatedly duplicate the full base model across deployments.
That means:
higher VRAM usage, higher inference cost, more GPUs, and worse scaling economics.
OpenLoRA changes the architecture completely.
Instead of loading multiple full AI stacks, OpenLoRA keeps a single base model resident in VRAM and dynamically swaps lightweight LoRA adapters depending on the task.
Medical query?
Load medical adapter.
Legal query?
Swap legal adapter.
Finance query?
Inject finance adapter.
Same base model.
Same GPU.
Different specialization layers.
That sounds small, but economically it changes everything.
Suddenly:
one GPU can serve multiple domains
infrastructure becomes dramatically cheaperAI apps scale without multiplying hardware costsspecialized AI becomes viable for smaller teams
This is the hidden layer most people are missing in decentralized AI discussions.
Everyone talks about model creation.
Very few are talking about model serving efficiency.
But in the long run, deployment economics may matter just as much as model quality.
Because the companies and networks that reduce inference costs at scale will have a massive advantage once AI demand explodes globally.
OpenLoRA feels important for that reason.
Not because it creates another chatbot…
but because it makes multi-domain AI infrastructure far more capital efficient.
And if decentralized AI actually scales, infrastructure layers like this may become more valuable than people expect.