A few weeks ago, I decided to explore some AI tools after constantly hearing the same narrative across crypto Twitter:
“AI agents are the future.”
I expected the experience to feel simple. Open a platform. Connect a wallet. Click a few buttons. Let the AI handle the rest.
Instead, I ran into a wall of complexity almost immediately.
One platform required coding knowledge. Another started talking about deployment infrastructure like it was everyday language. Then came APIs, GPU compute, model hosting, fine-tuning, vector databases.
At that point, I completely lost interest.
And honestly, that experience revealed something important: AI still feels inaccessible to most normal people.
That’s why OpenLedger started standing out to me. Because while most projects chase the surface layer of AI hype—agent marketplaces, meme-bots, ChatGPT wrappers—OpenLedger appears focused on the infrastructure underneath: the systems required to make AI more usable, transparent, and collaborative long term.
The Architecture Behind the Narrative
The more I looked into it, the more the actual design became interesting.
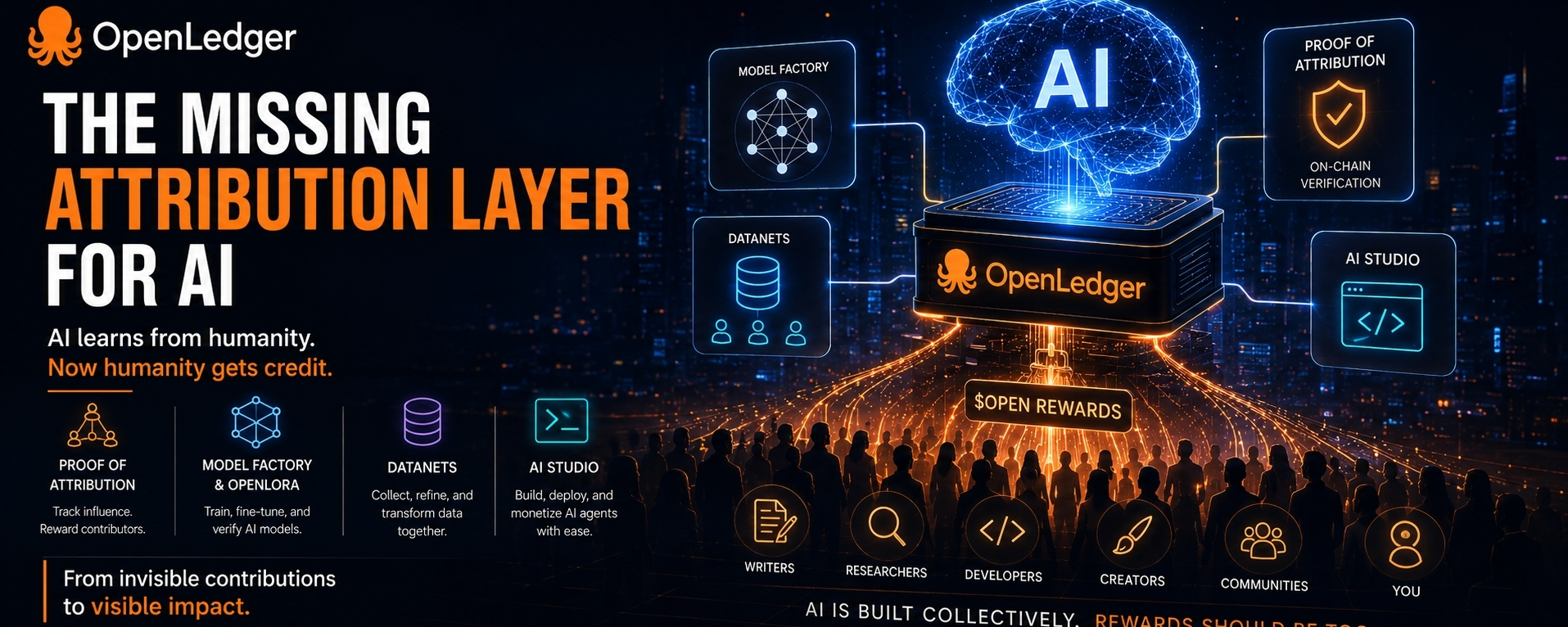
OpenLedger’s Model Factory and OpenLoRA framework provide end-to-end infrastructure for training, fine-tuning, and hosting AI models. But the detail that caught my attention most was on-chain verification of LoRA adapters.
That may sound technical, but the implication is simple. In a future flooded with AI-generated outputs, transparency becomes extremely valuable. If you can’t tell which model produced what output and on whose data it was fine-tuned, trust erodes.
Right now, most AI systems operate like black boxes. People contribute data, conversations, creativity, and knowledge every day. Yet once models become commercially valuable, those contributors effectively disappear. The system remembers the information. Not the people behind it.
Proof of Attribution: The Missing Economic Layer
That’s where Proof of Attribution becomes genuinely interesting.
Instead of treating human contribution as invisible fuel for AI systems, OpenLedger attempts to track how data influences model outputs and reward contributors through $OPEN. This is one of the few attempts I’ve seen to solve a real, looming problem: if AI is ultimately trained on collective human intelligence, shouldn’t value also flow back collectively?
The deeper you go, the more important data itself becomes. People obsess over models, but high-quality datasets are still the foundation behind every intelligent system. OpenLedger’s Datanets framework allows communities to collaboratively collect, refine, and transform raw information into LLM-ready datasets—with attribution baked in from the start.
That infrastructure could matter far more in the future than most people currently realize.
The Adoption Bottleneck
Then there’s AI Studio, which might actually be the most important piece for adoption. Not because it sounds flashy, but because accessibility matters.
Giving people an environment where they can build, deploy, and monetize AI agents without mastering complicated infrastructure first is a much bigger deal than many realize. Mass adoption rarely comes from power alone. It comes when complexity finally disappears enough for ordinary people to participate confidently.
A Necessary Dose of Skepticism
That said, no project is without open questions, and any honest take should acknowledge them.
First, attribution is hard to prove cryptographically. If someone tweaks a dataset slightly, does the original contributor still get credit? How does Proof of Attribution handle transformative use versus direct copying? OpenLedger will need sophisticated similarity and influence-tracing mechanisms—not just simple on-chain hashes.
Second, incentives can be gamed. Without careful design, $OPEN rewards could attract sybil attackers or low-quality data farming instead of genuine human intelligence. The difference between meaningful contribution and automated grinding is notoriously difficult to enforce.
Third, adoption velocity remains an open challenge. Building infrastructure is one thing. Getting developers, data curators, and end-users to actually use it over centralized giants like OpenAI, Google, and Anthropic is another entirely. Network effects in AI are brutally strong, and switching costs are high.
If OpenLedger solves even two of these three challenges, it becomes genuinely important. If it solves none, it risks becoming another ambitious but underused protocol.
What It Would Mean If This Works
Despite those open questions, OpenLedger no longer feels like just another “AI + crypto” narrative to me. It feels like infrastructure being built ahead of where the market’s attention currently is.
Consider what successful attribution would unlock. A researcher whose niche dataset improves a model’s reasoning on rare diseases gets paid automatically every time that capability is used. A writer whose style is absorbed into a fine-tuned LLM sees ongoing royalties instead of zero credit. A community that curates the world’s best dataset on endangered languages receives collective rewards rather than watching a corporation commercialize their work for free.
That is fundamentally different from how AI works today. Today, value flows almost entirely to model owners and compute providers. Data contributors—the actual source of intelligence—get nothing.
The Uncomfortable Question No One Is Asking Loudly Enough
Here’s what keeps me thinking about OpenLedger long after closing the tab.
We are currently training the most powerful intelligence systems in human history on the sum total of our shared knowledge, conversations, art, science, and labor. Every Stack Overflow answer. Every Wikipedia edit. Every Reddit thread. Every open-source repository. Every email, blog post, and comment section ever scraped.
All of it is being absorbed.
And almost none of the people who created that value are being compensated. Not a single cent. Not even a thank you.
That arrangement might be efficient. It might be legal under current fair use arguments. But is it right?
OpenLedger is not guaranteed to succeed. The technical challenges are real. The competition is ferocious. The economic mechanisms might break under pressure. But at minimum, the project is asking the right question:
If humanity collectively trains AI, shouldn’t humanity eventually share in the value it creates?
That question isn’t hype. It’s unavoidable. And OpenLedger is one of the few projects I’ve seen attempting to build a real answer—not just a press release.