I keep watching the wrong conversations win.
"Which model scored higher on the benchmark."
"Which company raised more."
"Which token pumped."
But underneath all that noise, something much darker is happening.
Something most people don't want to see.
The system is learning to forget us.
Not by accident.
By design.
Think about it.
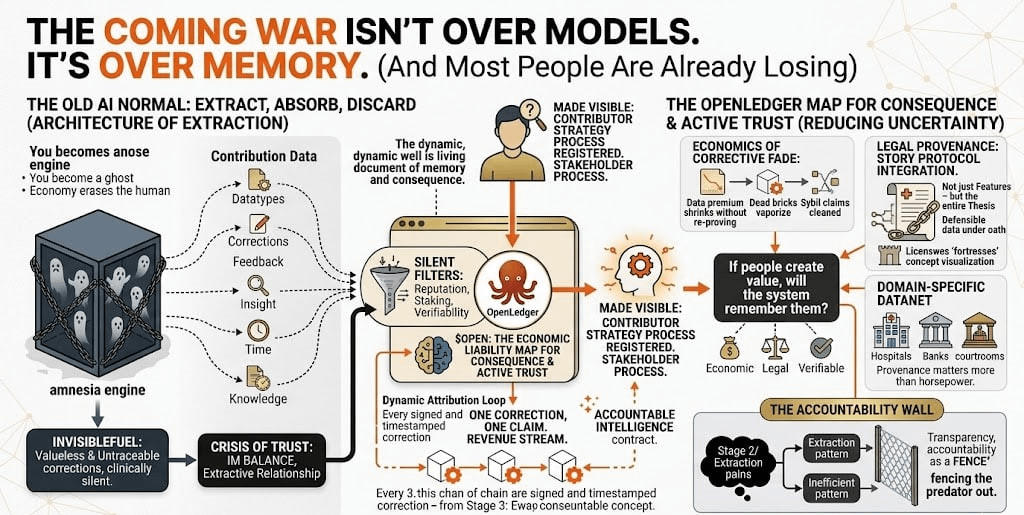
You spend years labeling data. Writing corrections. Sharing domain expertise that no AI could learn alone. You feed the machine your time, your knowledge, your attention.
The model gets smarter. Becomes worth billions.
And you?
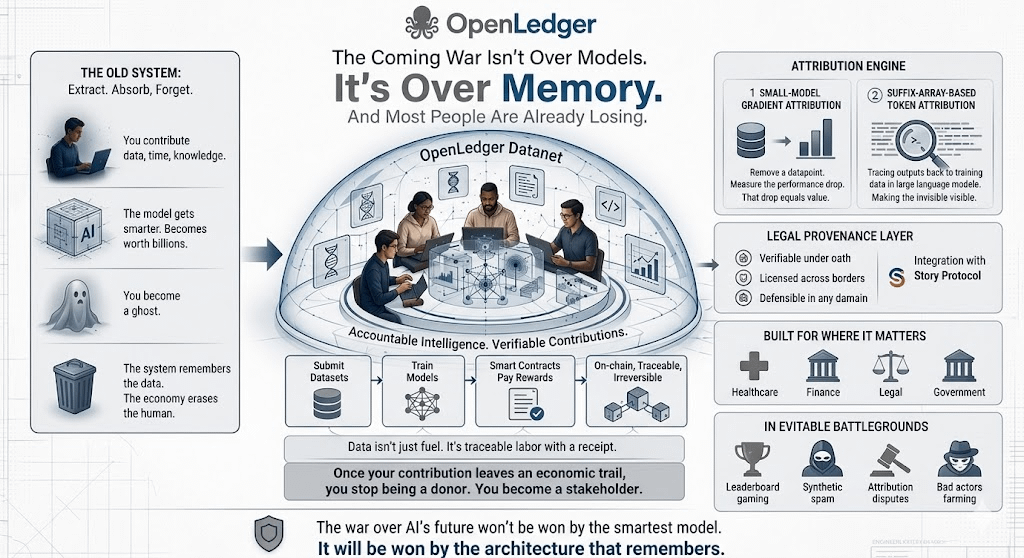
You become a ghost.
The system remembers the data.
The economy erases the human.
That's not a bug. That's the architecture of extraction. And it has held for years because no one built an alternative.
Until someone finally asked the question no one wanted to ask:
What if the machine had to remember who fed it?
That's why @OpenLedger stopped me cold.
Not because of the technology.
Not because of the token.
Because they're trying to build something the industry has avoided since the beginning:
Accountable intelligence.
Most AI projects talk about data ownership like a slogan.
OpenLedger turned it into an economic contract.
When OPEN Mainnet went live, the abstract became real.
Contributors submit datasets.
Developers train models.
Smart contracts pay rewards – on-chain, traceable, irreversible.
Suddenly, data isn't just fuel anymore.
It's traceable labor with a receipt.
That shifts the psychological floor. Because once your contribution leaves an economic trail, you stop being a donor. You become a stakeholder.
And stakeholders ask harder questions.
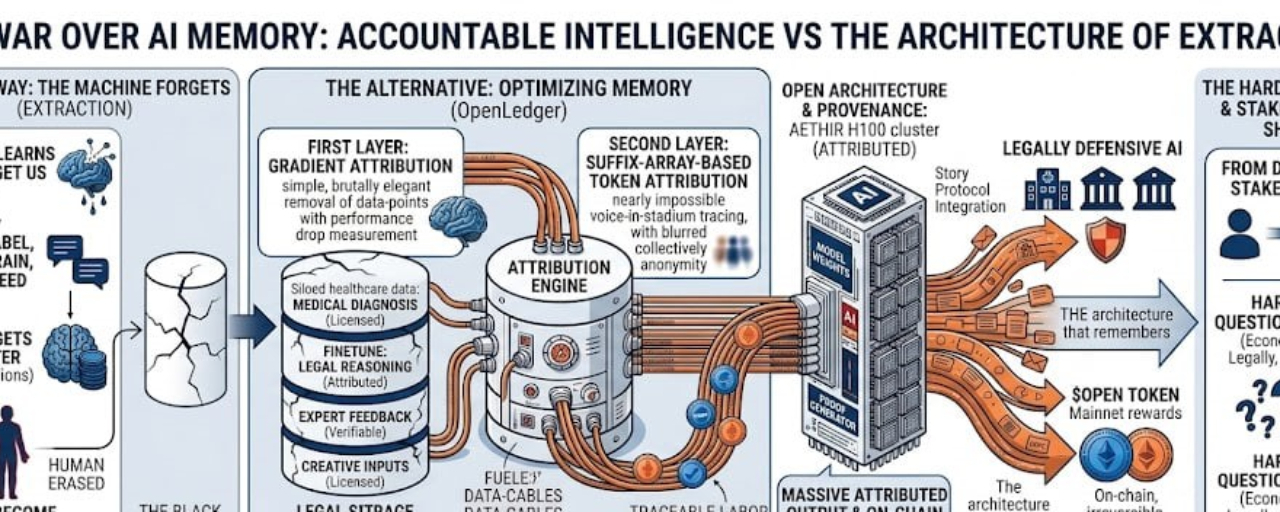
The attribution engine is where things get uncomfortable.
Two layers. One simple. One nearly impossible.
The first – small-model gradient attribution – is brutally elegant. Remove a datapoint. Measure the performance drop. That drop equals value.
Clean. Verifiable. Hard to game.
But the second layer?
Suffix-Array-Based Token Attribution for LLMs.
That's where most projects would walk away. Because tracing outputs back to training data in large language models is like finding one voice in a stadium of billions.
Outputs are collective.
Blurred.
Almost anonymous.
OpenLedger is attempting the near-impossible: making the invisible visible.
Will it ever be perfect? No.
I don't believe pure attribution exists.
But the attempt itself is a declaration.
Most platforms optimized extraction.
OpenLedger is optimizing memory.
That's not a technical difference.
That's a moral one.
Here's the layer almost everyone misses.
Legal provenance.
Integrations like Story Protocol aren't features.
They might be the entire thesis.
Because as AI moves into hospitals, banks, courtrooms, the question will shift.
Not "Is this model smart?"
But "Is this data defensible?"
Can it be verified under oath?
Licensed across borders?
Attributed when challenged?
Raw datasets are cheap.
Legally clean datasets are fortresses.
OpenLedger's domain-specific Datanet approach suggests they understand this. They're not building for everyone. They're building for where provenance matters more than horsepower.
In a market drowning in "AI for everything" narratives, that focus is rare.
And rare is valuable.
But I would be lying if I said the path was clean.
Where money flows, poison follows.
Leaderboard gaming.
Synthetic spam.
Attribution disputes.
Bad actors farming rewards with garbage data.
These pressures aren't hypothetical. They're inevitable.
The real test begins now.
Will validation survive scale?
Will attribution hold under attack?
Will incentives stay aligned when the easy money dries up?
I don't know.
But maybe that uncertainty is exactly why this moment matters.
Because for the first time, a project isn't asking the easy question.
The easy question is: "Can we build a faster model?"
The hard question is: "If people create value, will the system remember them?"
Not as a footnote.
Not as a forgotten contributor in a white paper.
But economically. Legally. Verifiably.
The industry will have to face this.
The current model – extract, absorb, discard – isn't just unfair. It's unsustainable. Contributors will eventually walk away from systems that erase them.
OpenLedger may not have all the answers.
But they're one of the only projects building infrastructure around the problem instead of pretending the problem doesn't exist.
The war over AI's future won't be won by the smartest model.
It will be won by the architecture that remembers.
And most people are already losing because they're not even paying attention.