OpenLedger 并没有傻乎乎地去和 OpenAI、Google 这些巨头正面硬刚算力和通用大模型,而是选择了一条更聪明、更务实、更可持续的差异化路线。
它的每一步设计,背后都有清晰的商业逻辑。
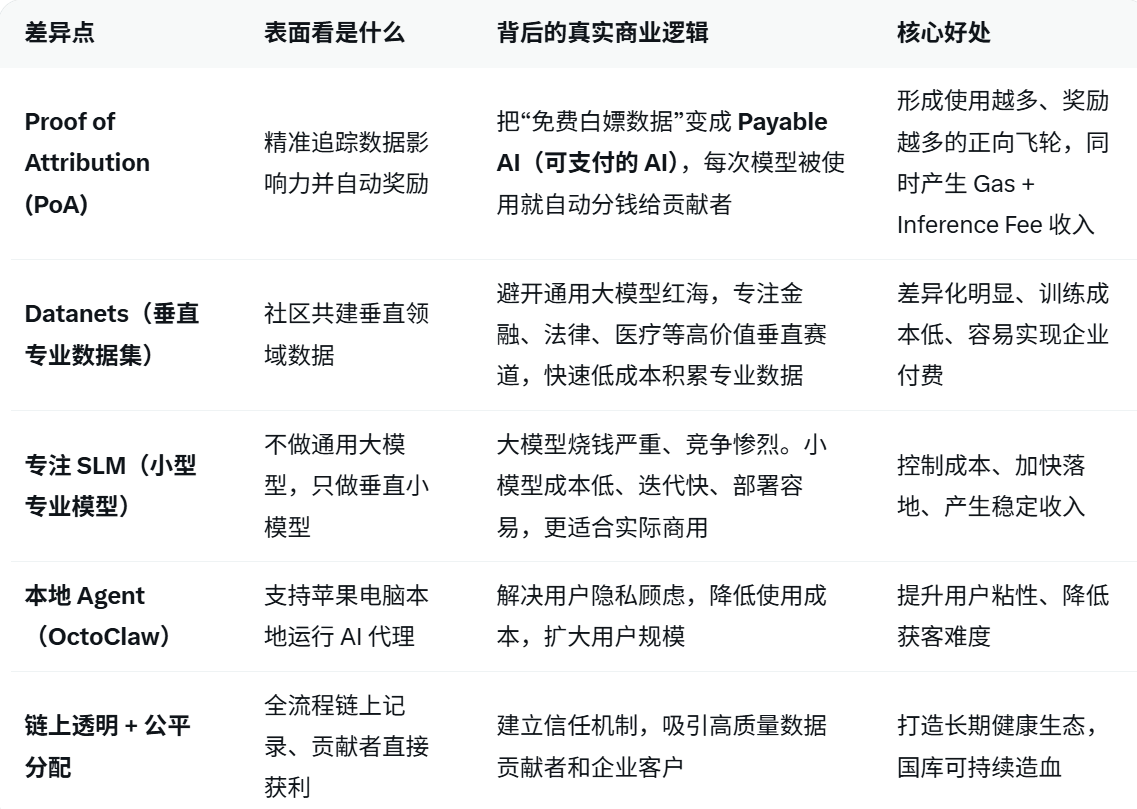
1. Proof of Attribution(PoA)—— 把数据变成“可支付资产”表面上看是“精准追踪数据影响力并自动奖励”,
真正的商业逻辑是:把传统 AI 里的“免费白嫖数据”变成Payable AI(可支付的 AI)。
每当模型被使用一次,贡献数据的人就能按影响力自动分到 $OPEN 。这就创造了一个使用越多、奖励越多的正向飞轮,既能吸引大量高质量数据,又能让项目方通过 Gas Fee 和 Inference Fee(模型调用费)获得真实收入。
2. Datanets(垂直专业数据集)—— 专注社区共建逻辑:通用大模型已经被巨头垄断,竞争太激烈、成本太高。而垂直领域(金融、法律、医疗等)对专业数据需求极大,却很难靠巨头通用模型满足。
OpenLedger 通过激励社区贡献,快速、低成本地积累高质量垂直数据集,从而训练出小而精的专业模型。这条路门槛更低、差异化更明显,也更容易实现企业级商用落地。
3. 专注 SLM(小型专业模型)而非通用大模型不拼参数量、不拼算力,核心逻辑是控制成本、加快迭代、降低使用门槛。
垂直小模型训练和部署成本低,更容易被中小企业接受,也更容易产生稳定的付费使用收入(Inference Fee)。
这比烧巨资去追 GPT-5 现实得多。
4. 本地 Agent(OctoClaw) + 链上透明机制支持苹果电脑本地运行,解决用户最关心的隐私问题;链上全流程透明,则建立信任。
商业意义在于:扩大用户基数、降低获客成本,同时为企业客户提供合规、可解释的 AI 解决方案,打开 B 端收入大门。
一句话总结商业逻辑:
OpenLedger 想做的,是成为 AI 时代的“数据和模型交易平台” —— 像 YouTube 给视频创作者分广告费一样,让数据贡献者和模型开发者持续赚钱。
项目方则通过 Gas、使用费和国库回购实现自身造血。这是一条低成本切入、高社区粘性、可持续变现的路线,在 DeAI 赛道里算得上相当务实。兄弟们,你们觉得这个商业逻辑能跑通吗?欢迎评论区讨论!#OpenLedger