
Most AI infrastructure projects talk about decentralization like it’s the entire story. Then you look closer and realize developers still have to learn a completely different stack, rewrite familiar tooling, and gamble months of work on ecosystems that may not survive long enough to matter. That’s partly why OpenLedger’s EVM-compatible layer stands out. Not because compatibility itself is exciting — honestly, it’s one of the least glamorous technical choices a project can make — but because it quietly admits something many AI-blockchain projects avoid saying directly: people build faster when they don’t have to start over.
That tension sits underneath almost every conversation around AI infrastructure right now. Everyone wants new systems for data ownership, model attribution, and agent economies. But developers also want stability. Familiarity. Existing tools. The industry keeps pushing toward radical redesigns while actual builders keep drifting back toward whatever already works.
OpenLedger seems to understand that conflict better than most.
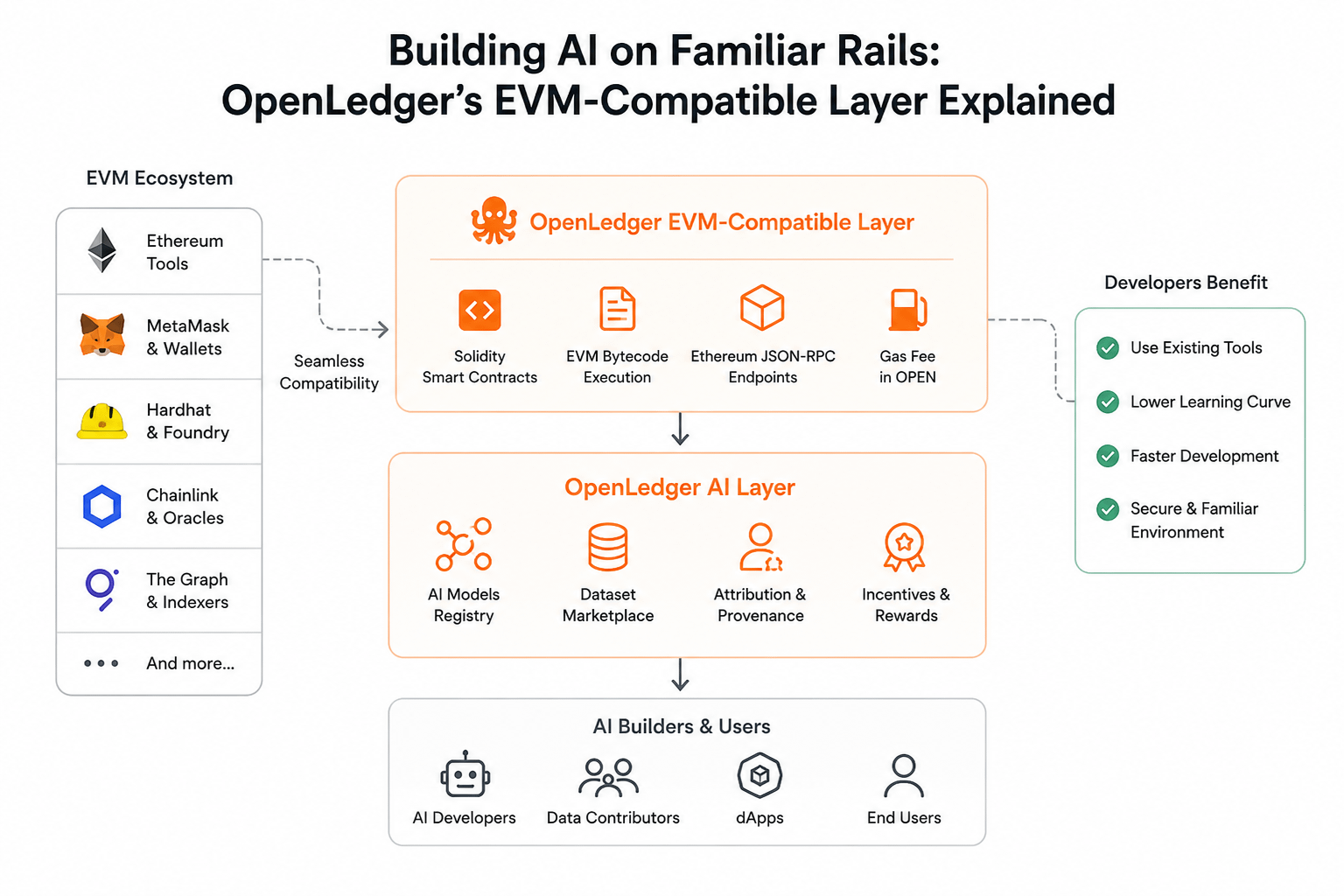
Its EVM-compatible layer basically means developers can build using Ethereum-style tooling and smart contracts without learning an entirely new programming environment. In practice, that matters more than whitepapers usually admit. Solidity developers already know how to deploy contracts, interact with wallets, audit permissions, and plug into existing infrastructure. Removing that friction changes adoption behavior immediately.
Not philosophically. Practically.
A lot of blockchain-AI projects accidentally create “innovation tax.” They introduce ambitious infrastructure but demand that builders abandon established workflows at the same time. That combination usually slows ecosystems down. Developers don’t just evaluate ideas anymore. They evaluate migration pain.
And migration pain is real.
Even experienced teams hesitate when they hear phrases like “custom virtual machine” or “new execution environment.” Because those phrases often translate into months of retraining, missing tooling, weaker documentation, and fewer security guarantees. None of that sounds exciting during conferences, but it shapes whether ecosystems grow or stall.
OpenLedger choosing EVM compatibility feels less like a technical flex and more like an admission that infrastructure succeeds when people barely notice it.
That sounds almost disappointing, honestly. We tend to associate innovation with visible novelty. But mature infrastructure usually becomes invisible. Nobody celebrates electricity because it works consistently. The same thing happens with developer environments. Familiar systems reduce cognitive overhead, and cognitive overhead quietly kills experimentation.
Especially in AI.
AI systems already introduce uncertainty everywhere else. Models behave unpredictably. Data quality fluctuates. Inference costs change weekly. Regulation remains unstable. Builders working in that environment often want at least one stable layer underneath everything. EVM compatibility provides that anchor.
Of course, compatibility also creates constraints. That part gets ignored sometimes.
Ethereum-style environments were not originally designed for AI-heavy coordination. They were designed around deterministic execution, token logic, and decentralized finance. AI workflows can become messy very quickly. They involve off-chain computation, massive datasets, asynchronous interactions, and probabilistic outputs. Trying to force all of that directly onto blockchain rails would become painfully inefficient.
So OpenLedger’s approach only really works if the chain acts more like coordination infrastructure than raw compute infrastructure.
That distinction matters.
There’s a growing tendency in AI crypto circles to imply blockchains should somehow “run AI.” Most of the time, they shouldn’t. At least not directly. Blockchain systems are generally terrible at high-volume computation compared to traditional infrastructure. What they can do well is attribution, permissions, ownership tracking, and economic coordination between participants.
That’s a narrower role than some people want. But probably a more realistic one.
The interesting thing about EVM compatibility in this context is how it lowers the barrier for experimentation around those coordination layers. Developers can focus on building incentive systems, agent interactions, or data contribution mechanics without reinventing the execution environment itself.
And that changes the type of builder who enters the ecosystem.
You stop attracting only deeply crypto-native teams willing to tolerate unstable tooling. You start attracting more pragmatic developers. The kind who care less about ideological purity and more about whether deployment works on Friday afternoon without breaking three dependencies.
That group is larger than people think.
There’s also a financial angle hiding underneath this compatibility choice. EVM ecosystems already contain liquidity, users, wallets, security frameworks, and integration layers. OpenLedger tapping into those rails potentially reduces isolation risk. New chains often struggle because they launch technically functional systems into economic emptiness. Builders arrive and discover there are no users. Users arrive and discover there are no applications. Then both sides quietly leave.
Compatibility doesn’t automatically solve that, but it reduces the distance between ecosystems.
Still, I’m not entirely convinced compatibility alone creates durability. Crypto has a habit of mistaking accessibility for inevitability. Easier onboarding helps, but ecosystems survive because people continue finding reasons to stay after onboarding ends.
That’s the harder problem.
OpenLedger’s AI-focused coordination model will eventually need to prove that its infrastructure produces meaningful outcomes beyond technical convenience. Can attribution systems remain trustworthy under scale? Can contributor incentives avoid collapsing into spam economies? Can developers actually build sustainable AI applications instead of speculative token loops pretending to be AI infrastructure?
Those questions matter more than whether deployment feels familiar.
But the familiarity still matters more than many people admit.
There’s a reason successful technologies often evolve incrementally instead of replacing everything overnight. Human systems resist abrupt transitions. Developers especially resist them. Every additional layer of unfamiliarity creates hidden costs: debugging time, security uncertainty, integration failures, documentation gaps, hiring difficulties.
People underestimate how emotionally exhausting unstable infrastructure becomes after a while.
You can almost feel the industry reaching a kind of fatigue point now. For years, crypto infrastructure projects competed by introducing increasingly exotic architectures. Meanwhile, many developers quietly kept building on older systems because predictability mattered more than novelty.
OpenLedger’s EVM-compatible layer feels connected to that broader shift. Less obsession with radical reinvention. More focus on reducing friction around useful coordination mechanisms.
Maybe that sounds less ambitious. Maybe it is.
But there’s something oddly practical about admitting that developers already have enough uncertainty to manage. AI itself is chaotic enough. Giving builders familiar rails underneath that chaos may end up being more valuable than introducing another entirely new environment claiming to replace everything before it has even stabilized itself.
And honestly, after watching so many ecosystems spend years rebuilding tools people already had elsewhere, the restraint feels refreshing.

