I feel OpenLedger is ignoring the AI hype to focus on a real problem: proving who actually owns your data.
Every week there's a new project slapping "AI-powered" onto their pitch deck. Decentralized AI. AI agents. AI this, AI that. Most of it is noise — the same blockchain promises recycled with a new buzzword on top.
OpenLedger feels different. And the reason is simple: they're not really pitching AI. They're pitching *ownership*.
The Problem Nobody Wants to Talk About
Think about how AI models actually get built. Billions of data points — articles, images, conversations, code — scraped from the internet, fed into a training pipeline, and turned into a product worth tens of billions of dollars. The people who created that content? They get nothing. No credit, no cut, no say.
Most AI systems still operate in black boxes where data origins, model creators, and contributor rewards remain hidden. That's not a technical oversight. It's a structural one. The incentives were never built to reward the people at the bottom of the stack.
OpenLedger is trying to change the stack itself
What They're Actually Building
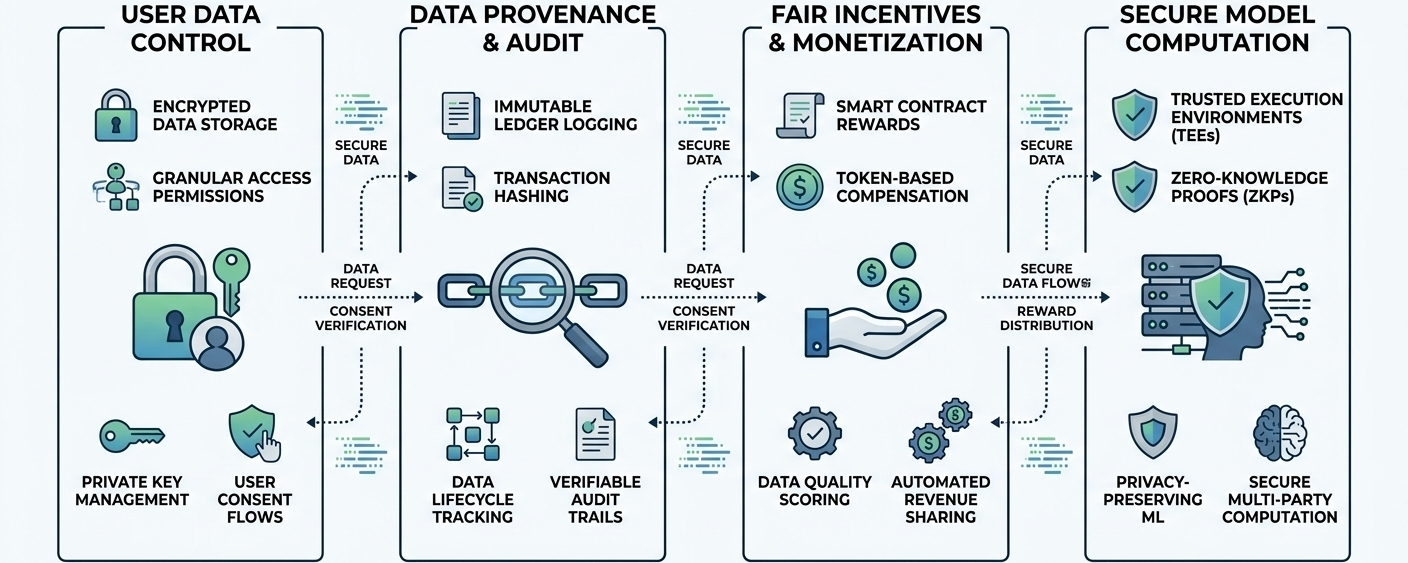
OpenLedger is an AI-native blockchain aimed at making data, models, and autonomous agents verifiable, ownable, and economically accountable. That's their core thesis — and it's a meaningful one.
The way it works is through what they call Proof of Attribution. Every dataset and model update is recorded on-chain, securing originality and protecting ownership rights. Contributors earn economic rewards through this system automatically — ensuring their efforts are acknowledged and compensated rather than overlooked by platforms that profit from their work.
In plain English: if your data trains a model, you get paid. Not as a promise or a goodwill gesture — as an on-chain mechanism that runs whether anyone feels generous that day or not.
The OPEN Mainnet launch in April 2026 was the moment this moved from whitepaper to real infrastructure.
The Bigger and Real Picture
The timing here isn't accidental. Regulators, enterprises, and researchers are intensifying scrutiny of opaque AI systems. Concerns over copyright disputes, AI-driven market manipulation, and the inability to trace how models actually make decisions have reached a fever pitch. Governments are starting to ask hard questions about where AI training data comes from. Creators are suing. Courts are weighing in.
And the industry still doesn't have a clean answer to "who owns this?"
OpenLedger is trying to be that answer before regulators are forced to invent one. Their partnership with Story Protocol builds an IP layer that lets AI models train on copyrighted data and automatically pay the rights holders — a system that simply doesn't exist anywhere else in traditional AI development pipelines.
Why This Matters More Than Most Projects
A lot of crypto-AI projects are solving compute problems — cheaper GPUs, distributed inference, storage. Those are real problems, but they're infrastructure for the *existing* model of AI: big labs, opaque data, closed systems that keep the value at the top.
OpenLedger is betting the next generation of AI won't be built that way. They believe the companies that win won't be the ones hoarding the best data — they'll be the ones building open, collaborative infrastructures where attribution, ownership, and contribution are fully verifiable by anyone.
That's not an AI pitch. That's a property rights pitch. And honestly, it might be the more important one.
The AI hype cycle will fade. The question of who owns the data that powers these models won't. OpenLedger seems to understand that — and they're building like it.
