When people talk about AI, the conversation usually starts with what it can do. They talk about faster workflows, cheaper operations, smarter tools, better outputs, and the number of tasks that can now be handled by machines. That part is easy to notice because it sits on the surface. But there is another question underneath all of this that feels much more important with time: what is this AI actually built on, and can we trust it? Every AI system carries a history inside it, even when that history is not visible. There is data behind it, models behind the data, agents following instructions, tools connected to other tools, and decisions shaped by layers most users never get to inspect. The final answer may look clean, but the path behind it can be unclear. And when AI starts moving from casual use into serious work, that unclear path becomes a real problem.
This is why OpenLedger feels interesting in a different way. It is not only about making AI sound more powerful or adding another big claim to the space. Its value becomes clearer when you look at the trust problem sitting behind AI. As more companies, developers, and users start relying on AI systems, they will care more about where the pieces come from. A company will not always want to use a dataset if it does not know how that data was collected. A developer may not want to connect a model if there is no reliable record of how it behaves. A user may not feel comfortable with an agent taking action if no one can explain what tools it used, what instructions guided it, or what happened before the final result appeared. At first, these sound like technical concerns, but they are really questions of confidence.
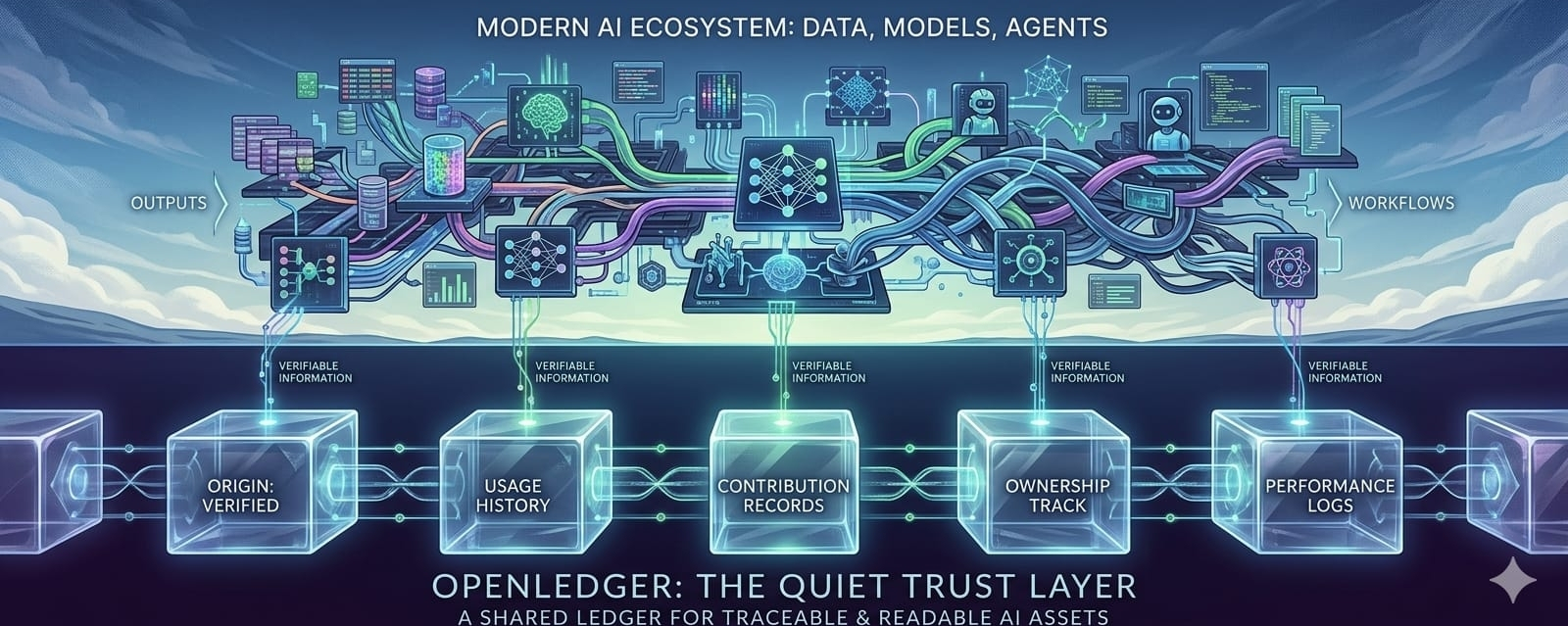
OpenLedger is built around data, models, and agents, and these pieces are slowly becoming more than just software components. They are becoming assets with economic value. A useful dataset can improve a system. A strong model can save time. A focused agent can complete work that others can build on. But for that value to move safely, people need more than access. They need context. They need to understand the origin, history, usage, and reliability of what they are using. This is where blockchain starts to make sense in a quieter and more practical way. Not as a magical solution, and not as the loudest part of the story, but as a shared record that different people can refer to. It can act like a common notebook where ownership, usage, contribution, and history are recorded without forcing everyone to depend on one private database.
A market usually feels early when its trust layer is still weak. People depend on reputation, private agreements, closed platforms, or big brand names to reduce risk. That can work for some time, but it also keeps the market narrow. Small data owners may have valuable datasets, but buyers may hesitate because they cannot verify enough about them. Independent model builders may create useful tools, but they may not have the visibility or reputation to prove their quality. Agent developers may build strong workflows, but those agents need some kind of track record before others feel safe using them. OpenLedger seems to be working on this missing layer by helping AI assets become more traceable, more readable, and easier to evaluate.
That makes the idea bigger than simple monetization. Of course, monetization matters. If someone creates a valuable dataset, model, or agent, they should have a way to earn from it. But earning depends on trust first. Before someone pays for an AI asset, they want to know what it is, where it came from, how it has been used, and whether it actually performs in a meaningful way. This is why liquidity is not only about movement. It is also about confidence. A market becomes more liquid when people can make decisions without being surrounded by too much doubt. They do not need perfect certainty, but they need enough information to act. If OpenLedger can help AI assets carry records of origin, usage, ownership, and performance, then those assets become easier to move because they become easier to trust.
This becomes even more important as AI becomes modular. The future may not be one giant model doing everything by itself. It may look more like a network of different models, datasets, agents, and tools working together. A business might use one model for documents, another for images, a private dataset for internal knowledge, and different agents for different workflows. In that world, every piece has to be trusted on its own. It becomes less like buying one complete machine and more like building a supply chain. And supply chains need records. They need to show what entered the system, who provided it, when it changed, how it was used, and what it affected. AI will need something similar because invisible inputs create invisible risks.
This does not mean the problem is easy. A record can still be weak. Claims can still be exaggerated. Some data may be sensitive and cannot be shown openly. Some performance results may not mean much outside a specific setting. An agent may behave well in one workflow and fail in another. A shared ledger does not remove all of these problems. But it gives people a better place to begin. It makes it possible to ask better questions. It gives assets a history that can be inspected instead of leaving everything hidden behind promises. That alone matters because a lot of AI today still asks people to trust the output without understanding the path behind it.
The more AI grows, the more valuable this kind of record may become. A small dataset with clean origin and clear usage history may become more useful than a massive dataset with unclear sources. A narrow model with reliable performance records may become easier to adopt than a broader model with vague claims. An agent that can show what it did, when it acted, and under what conditions may earn more trust than one that simply promises automation. In that kind of market, value shifts from being loud to being legible. The assets that people can understand, verify, and trace may become the ones they are most willing to use.
AI has already made creation faster and outputs cheaper. But the next challenge is not only creating more. It is knowing what deserves trust. People will need ways to understand which datasets are clean, which models are reliable, which agents are safe, and which assets are worth paying for. OpenLedger feels like an attempt to work on that quieter layer beneath AI. Not the shiny interface, not the final answer on the screen, and not the hype around automation, but the record underneath it all. The part that helps people see what they are actually using. And as AI becomes part of more serious workflows, that hidden record may matter far more than most people expect, not because anyone wants extra complexity, but because everyone will want fewer blind spots.
