I think the market is still looking at AI infrastructure through the wrong lens.
Most people frame the AI stack around compute, inference demand, model capability, or data ownership.
Faster GPUs. Better models. Lower inference costs. Bigger context windows.
That logic works if AI behaves like traditional software where each new version cleanly replaces the old one.
But real commercial systems rarely evolve that way.
Legacy systems do not vanish just because something technically superior appears. They leave behind obligations, dependencies, and unresolved liabilities.
That is where OpenLedger started becoming interesting to me.
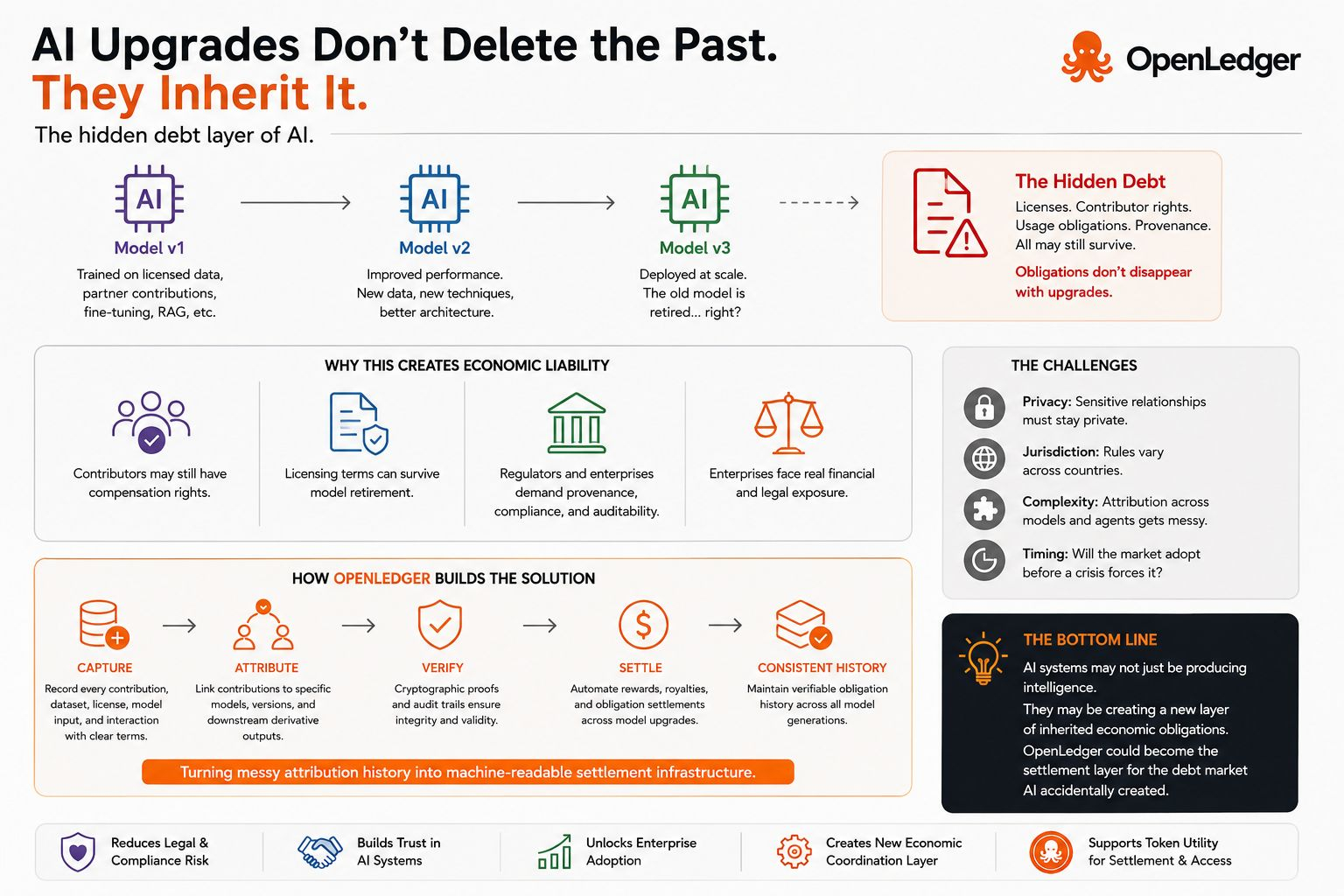
The deeper issue in AI may not ultimately be compute cost.
It may be inherited economic liability.
Imagine an enterprise AI model trained using licensed datasets, proprietary partner intelligence, external fine-tuning pipelines, retrieval systems, and specialized checkpoints. A stronger version gets deployed six months later because performance improves.
The obvious assumption is that the previous system is now obsolete.
Economically, that may not be true at all.
Some contributors may still retain usage-linked compensation rights. Certain licensing agreements may continue surviving even after retirement if newer outputs still depend on inherited training lineage. Regulators increasingly care about provenance — essentially proving where information came from and whether it was legally usable.
Internal compliance teams care even more.
A model upgrade does not automatically erase inherited permission structures.
That starts looking less like software iteration and more like debt.
Not debt in the balance-sheet sense.
More like persistent obligation chains attached to AI memory itself.
The comparison matters because markets price systems differently when liabilities survive utility transitions. Old financial instruments remain economically relevant long after the original transaction disappears.
Enterprises still pay maintenance contracts for outdated systems because operational dependency continues existing underneath the surface.
AI may evolve similarly.
That is why OpenLedger becomes more compelling if it is not simply monetizing AI creation, but organizing AI obligation settlement.
Its public narrative is easy enough to understand: contributor rewards, attribution infrastructure, collaborative AI systems, specialized data networks.
But infrastructure value usually exists one level deeper than the visible narrative.
The harder question is this:
What happens when AI systems inherit economic claims across model generations?
If AI continuously absorbs exteRnal intelligence, licensed data, contributed refinements, synthetic augmentation, and autonomous agent interactions, somebody eventually needs a verifiable system tracking who contributed what, under which terms, and whether those permissions remain enforceable.
Once enterprise distribution, regulation, and real money enter the picture, that stops being optional metadata.
It becomes operational infrastructure.
OpenLedger’s importance may come from turning chaotic attribution history into machine-readable settlement rails.
Meaning contribution records, rights structures, and settlement conditions become organized in formats software can verify automatically instead of humans manually reconciling everything through legal departments and spreadsheets.
Because manual reconciliation does not scale.
Imagine a healthcare AI assistant updated every quarter. The latest version contains architectural improvements, retraining on licensed medical data, synthetic augmentation layers, and external specialist model integrations.
Hospitals deploying that system do not only care about output quality.
Procurement teams may ask whether deployment introduces unresolved licensing exposure. Regulators may demand explainability. Legal teams may question whether historical permissions remain valid after architectural modification.
Now expand that complexity across autonomous agents interacting with other models.
The accounting problem becomes enormous very quickly.
If OpenLedger can standardize attribution infrastructure where contribution history remains verifiable across upgrades, then $OPEN starts looking less like a speculative utility token and more like settlement infrastructure for inherited AI obligations.

That is a much stronger thesis than simple usage demand.
Usage narratives are fragile.
Inference costs decline. Competition compresses margins. Open-source models weaken monetization power. Pure compute narratives often drift toward commoditization over time.
Settlement infrastructure behaves differently.
Financial systems survive because coordination, trust, verification, and settlement remain expensive bottlenecks. AI may eventually develop similar bottlenecks once provenance becomes economically enforceable instead of optional transparency theater.
There is also a realistic enterprise adoption pathway here.
Startups may ignore these issues initially because speed matters more than compliance during early growth stages. Enterprises behave differently. Healthcare operators, insurers, banks, and infrastructure vendors prefer systems with auditable accountability.
Not because they enjoy compliance.
Because uncertainty becomes expensive.
That creates a genuine buyer class.
The token question, however, remains harder.
A strong infrastructure thesis does not automatically create token value.
$OPEN only matters structurally if settlement, verification, staking, or access coordination genuinely require the token layer. If enterprises can replicate attribution records privately off-chain or settle through traditional contractual systems, token capture weakens quickly.
Privacy creates another challenge.
Most enterprises will not want full public disclosure of commercially sensitive training relationships. Privacy-preserving verification becomes essential. Systems may eventually need to prove attribution validity without exposing proprietary underlying data.
Zero-knowledge architectures could help solve that problem, although implementation complexity increases rapidly.
Then there is jurisdictional fragmentation.
AI governance is not globally unified. European compliance expectations differ from US enforcement patterns, which differ again from emerging-market commercial norms. Infrastructure designed around universal attribution assumptions may eventually discover that legal obligations are frustratingly local.
And maybe the largest risk is behavioral.
Markets constantly assume technical possibility automatically becomes economic necessity.
That assumption often fails.
Yes, inherited AI obligation chains are plausible. Yes, attribution infrastructure makes conceptual sense. But will builders actually feel enough pressure to pay for formal settlement rails before a major legal or commercial failure forces adoption?
That timing question matters.
Infrastructure is often early right but commercially early wrong.
Still, I keep returning to the same conclusion.
AI upgrades are usually framed as clean progress stories — stronger models replacing weaker ones in a continuous cycle of improvement.
But complex systems rarely produce clean exits.
Sometimes the thing that survives is not the model itself.
It is the obligation history attached to what the model remembers.
And if that becomes true at scale, OpenLedger may not actually be building AI collaboration infrastructure.
It may be building the debt market AI accidentally created.