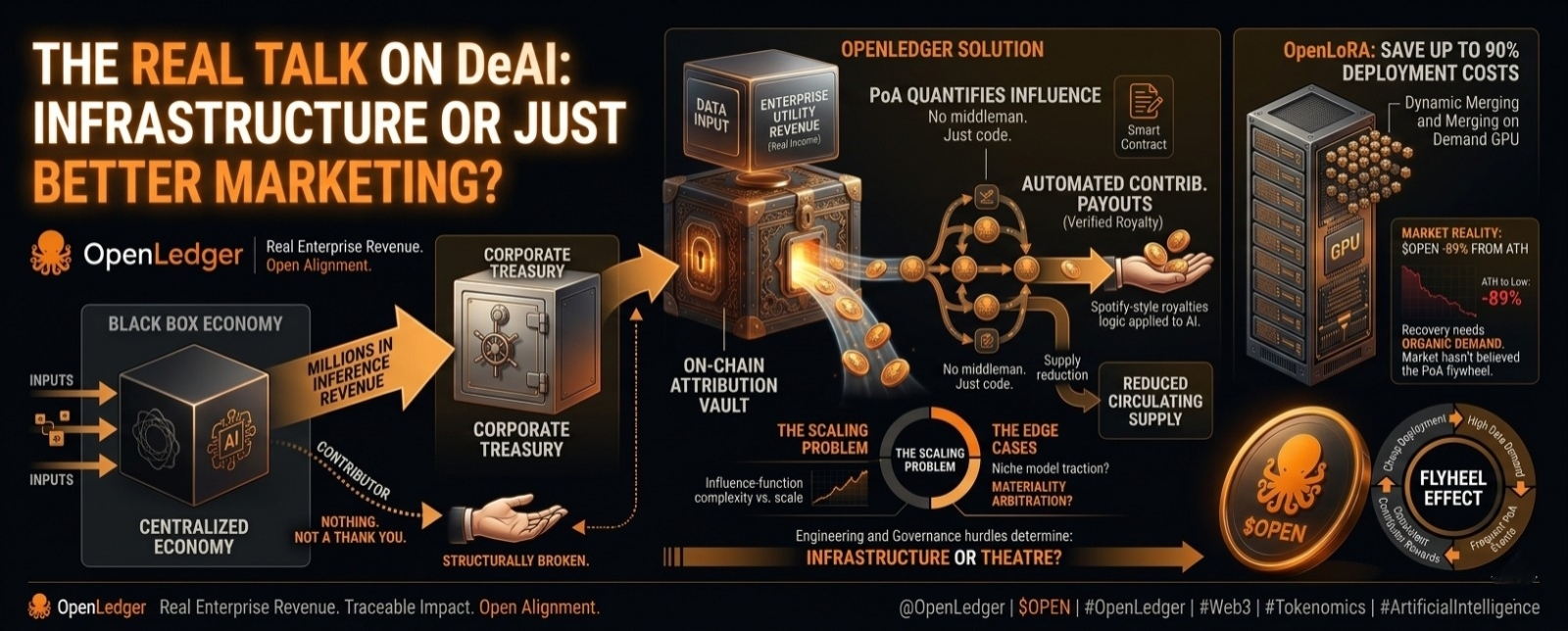
Let’s be honest. When you first read about Proof of Attribution (PoA), it’s easy to dismiss it as another crypto buzzword wrapped in AI branding. Grand mechanism name, vague whitepaper promises, token launch, done. We’ve all seen that playbook.
But if you sit with the core question underneath, it doesn't leave you alone: Who really owns the value an AI model creates?

Right now, AI operates in a black box. You upload data, a centralized company trains a model, it generates millions in inference revenue, and you get nothing. Not even a receipt. This is the default state of the AI economy, and almost nobody talks about how structurally broken that is.
Inside the Mechanics of PoA
@OpenLedger is attempting to rewrite this structure at the protocol level. At the heart of the OPEN Main net is their Proof of Attribution system—a blockchain-based mechanism designed to log the entire lineage of AI assets, datasets, and models on-chain.
[Data Input] ➔ [PoA Quantifies Influence] ➔ [Smart Contract] ➔ [Automated Payout]
When a model generates an output, PoA mathematically quantifies how much a specific dataset influenced that result, triggering automated payouts via smart contracts. No middlemen. Just code.
It sounds incredibly clean, but as analysts, we have to look at the operational friction:
• The Scaling Problem: Their whitepaper leverages influence-function methods. In machine learning research, these are notoriously expensive computationally. They look flawless in theory but get messy at scale.
• The Edge Cases: If your data improves a model, you earn. If it's bad, you're penalized. But what happens if you submit pristine data for a niche model that never gets traction? Who arbitrates data materiality when two identical datasets are uploaded?
These aren't rhetorical questions; they are the exact engineering hurdles that will determine whether PoA becomes foundational infrastructure or just expensive theatre.
The Economic Catalyst: OpenLoRA
Attribution without deployment is just bookkeeping. This is why their launch of OpenLoRA caught my attention. By allowing developers to run thousands of fine-tuned LoRA models on a single GPU using quantization and tensor parallelism, they claim a 90% reduction in deployment costs.
The Flywheel Effect: If specialized model deployment becomes cheap, the data training those models becomes highly sought after. More demand triggers more PoA events, leading to consistent passive rewards for data contributors—essentially a Spotify royalty model for AI data.

The Market Reality Check
Despite the tech stack, there's a heavy elephant in the room: $OPEN is down roughly 89% from its listing high. That brutal number tells us that the market hasn't figured out how to price data attribution yet, or it's sceptical that this flywheel will spin. While their enterprise revenue-funded buyback program (over 3.3% of supply accumulated on-chain) proves real economic activity is happening, a buyback alone doesn't build a sustainable data economy.
The system lives or dies on trust. If OpenLedger can cryptographically solve the black-box audit problem for AI agents, the market is drastically mispricing what they are building. If it stalls under scaling bottlenecks, it remains a brilliant, unfinished experiment.
Watch the developer adoption of OpenLoRA and the actual utility of their Datanets. The real answers will come from behaviour, not whitepapers.
What's your take? Can on-chain attribution scale, or will centralized black boxes keep winning?