@OpenLedger The way I used to think about attribution systems was pretty clean. You contribute something to an AI data, feedback, whatever the model learns from it, value gets created, and you get paid. Done. That felt mechanically honest. But over time I’ve realized I was missing a whole back end of the story. What actually happens to a contribution after everyone stops talking about it, but it’s still quietly doing work inside the machine?
That gap between social visibility and economic usefulness is bigger than it sounds.
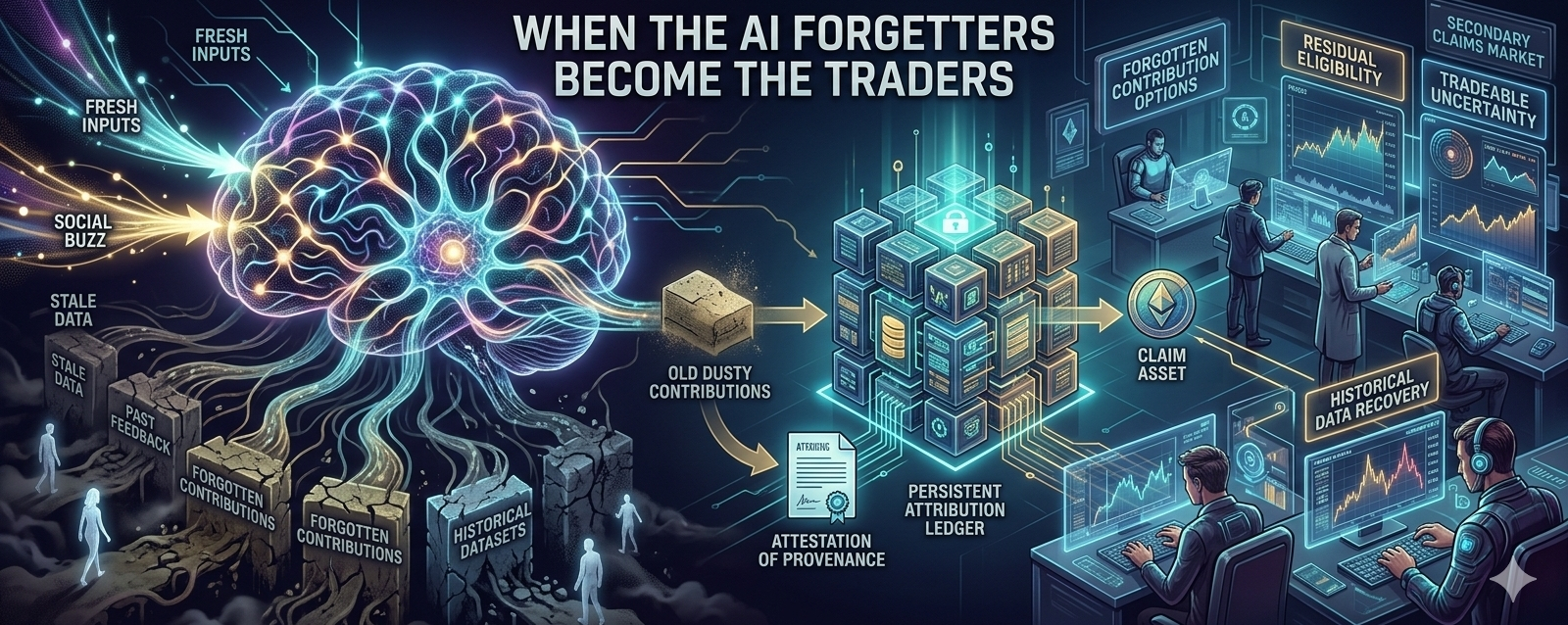
A piece of training data can vanish from conversation within weeks. Nobody mentions it on Twitter, no one cites it in blog posts, it’s not trending anywhere. But inside the model’s weights, fine-tuning layers, or retrieval pathways, that same contribution might still be shaping outputs for months or years. It just becomes invisible to human attention while staying functionally alive. And that’s where OpenLedger starts to get interesting to me not because they’ve solved fairness, but because they’re building the kind of infrastructure that could turn those forgotten contributions into tradeable claims.
Right now most AI data markets are front-door systems. New data in, payment out, attribution attached. Fresh inputs get all the love because recency drives value in ranking algorithms and attention economies. But machine memory doesn’t care about recency. An old, dusty dataset that nobody remembers could still be nudging inference pathways in ways that matter commercially. So what happens to the economic rights attached to that old dataset? The original contributor might have walked away, or gone bankrupt, or just given up on ever seeing a penny from it.
That question gets uncomfortable fast.
Once attribution becomes persistent infrastructure rather than a one-time payout, a contribution stops looking like labor and starts looking more like an asset with deferred extraction rights. Not ownership in the legal sense—something messier. Residual eligibility. You might have stopped getting recognized, but your data might still be eligible for future payment if certain conditions trigger. Maybe only when revenue crosses a threshold, or when someone audits the model and finds your fingerprints inside it. That means economic consequence arrives late. Sometimes very late. And late settlement changes how people behave.
Imagine you’re a contributor who has a small piece of an old training set that’s still floating around inside a popular model. You have no idea if it will ever generate money, and you need cash now. Instead of waiting for a maybe-settlement, you could sell that future claim to someone else at a discount. A fund, a validator, a speculator—someone who thinks they can price the uncertainty better than you can. They buy your rights, you get liquidity, they take the enforcement risk. That starts looking a lot like a secondary market. Not for the data itself, but for the recovery of forgotten contribution value.
We’ve seen this pattern everywhere. Royalties. Litigation finance. Music catalogs. Patent claims. Distressed debt. Whenever future cash flow becomes legible enough, someone tries to price it. So why would persistent AI attribution be different? Especially if OpenLedger makes attribution machine-readable enough that downstream systems actually trust the evidence. That word “trust” is doing heavy lifting. A claim only becomes market-usable if enough people believe enforcement has real gravity behind it. Not perfect justice. Just enough gravity to make settlement cheaper than dispute.
And here’s the part that keeps circling back in my head: OpenLedger doesn’t necessarily need to make attribution morally correct. It may only need to make contribution claims sufficiently legible for economic actors to underwrite them. That’s a lower bar. But it’s also a weird one, because now the system is no longer about remembering contributions out of fairness. It’s about making old uncertainty tradeable.
Most contributions do not survive socially. They get buried under newer inputs, trend shifts, synthetic duplication, content decay. Real-time feeds compress visibility into whatever is current. Older work becomes structurally invisible unless someone deliberately revives it. But invisible is not the same as economically dead. That distinction is everything. If OpenLedger creates persistent attestation around provenance, then forgotten inputs can remain machine-legible long after human attention moves on. A claim can be stale socially while still being queryable structurally. That makes recovery possible. And once recovery is possible, pricing follows.
But then what exactly is being priced? Truth? Or just sufficiently legible attribution evidence? Not the same thing. A contribution can be schema-compatible without being economically decisive. An attestation can show presence without proving causal value. A dataset can appear in lineage records without meaningfully shaping outcomes. That ambiguity doesn’t kill the market—secondary markets actually like ambiguity. If outcomes were perfectly certain, pricing would collapse into simple math. Uncertainty creates spread, and spread creates room for buyers and sellers.
That’s where it gets messy. Because now forgotten AI contribution markets stop looking like fairness infrastructure and start looking like claims arbitration environments. Who decides whether old contribution residue mattered enough to deserve settlement? What version of causality becomes visible enough to count? Did the input shape output directly, indirectly, probabilistically, structurally? Or is that just narrative pressure attached to an attested state object? I don’t know. Maybe the protocol doesn’t need certainty either. Maybe it only needs enough evidentiary structure that downstream participants prefer settlement over dispute.
That’s a very different economic object. Not attribution as truth. Attribution as negotiable pressure.
Sounds abstract until you think about scaled AI deployment. Models absorb years of layered inputs. Contributors disappear. Teams pivot. APIs get wrapped. Agents call other agents. Downstream usage keeps moving while upstream contribution memory fragments. Before consequence arrives, most context is already gone. That’s the real problem. Attribution systems that preserve enough residue to reconstruct partial claims might end up monetizing historical uncertainty more than they reward original creators.
And OpenLedger’s $OPEN token, tied to validation, staking, and dispute coordination, could capture some of that economic motion. But only if the market treats the protocol’s evidence as consequential. If teams settle elsewhere, if attribution becomes symbolic, if off-platform legal coordination proves cheaper, then the whole structure weakens fast.
I started this thinking attribution infrastructure was about remembering forgotten work. Now I think the stranger possibility is that remembering may be less important than making old uncertainty tradeable. And I honestly can’t decide whether that makes the system more useful—or just more extractive in a clever disguise.