
The more I look at AI infrastructure lately, the more it feels like the market is slowly moving away from the old idea that bigger models automatically win.
A year ago, most conversations were dominated by scale. More parameters, larger context windows, larger GPU clusters. That race is still happening, but underneath it another pattern is starting to emerge. People are realizing that intelligence without attribution creates a strange kind of economic dead end.

When I first started exploring @OpenLedger , what stood out was that they were not positioning themselves purely as another AI chain or another model marketplace. The foundation seems much more focused on what happens underneath the model layer itself. Who contributed the data. Which datasets actually improved outputs. How specialized models are trained. How inference activity gets connected back to contributors. Those questions sound technical at first, but they are quietly becoming financial questions too.
That matters because the AI economy right now is still incredibly opaque. Most people interact with AI through interfaces that reveal almost nothing about where the outputs originated from. A model generates an answer, an image, a recommendation, or a trade signal, but the economic flow behind that process remains hidden. The datasets are hidden. The contributors are invisible. Even the fine tuning layers are usually treated as black boxes.
Understanding that helps explain why OpenLedger keeps emphasizing attribution infrastructure and Datanets instead of chasing generic AI narratives. The market is flooded with broad AI products already. What remains scarce is specialized intelligence with traceable origins.
That difference is important.
A healthcare model trained on verified medical datasets behaves differently from a general chatbot scraping fragmented internet data. A trading agent optimized using niche financial datasets behaves differently from a generic assistant trying to answer everything at once. Early signs suggest the next stage of AI may depend less on universal models and more on smaller systems trained with highly refined data environments.
That creates another effect underneath the surface. Specialized AI changes the economics of data itself.
For years, data has mostly been treated as raw fuel. Companies collect it, models consume it, and contributors disappear from the equation once the training process finishes. OpenLedger appears to be exploring a different structure where datasets become persistent economic assets connected to attribution and ongoing usage.
If that model holds, then inference stops being just computation. It becomes settlement.
That idea sounds abstract until you think about what happens when AI agents start operating autonomously across financial systems, marketplaces, research environments, and consumer applications. Every output suddenly carries economic weight. Every model interaction generates value somewhere. Once that starts happening at scale, the lack of attribution becomes difficult to ignore.
Meanwhile, the broader AI market is already moving toward modularity. Fine tuning layers, LoRA systems, retrieval pipelines, agent frameworks, and domain specific adapters are becoming standard architecture. Even large AI companies are increasingly relying on specialized layers sitting on top of foundation models rather than rebuilding entire systems from scratch each time.
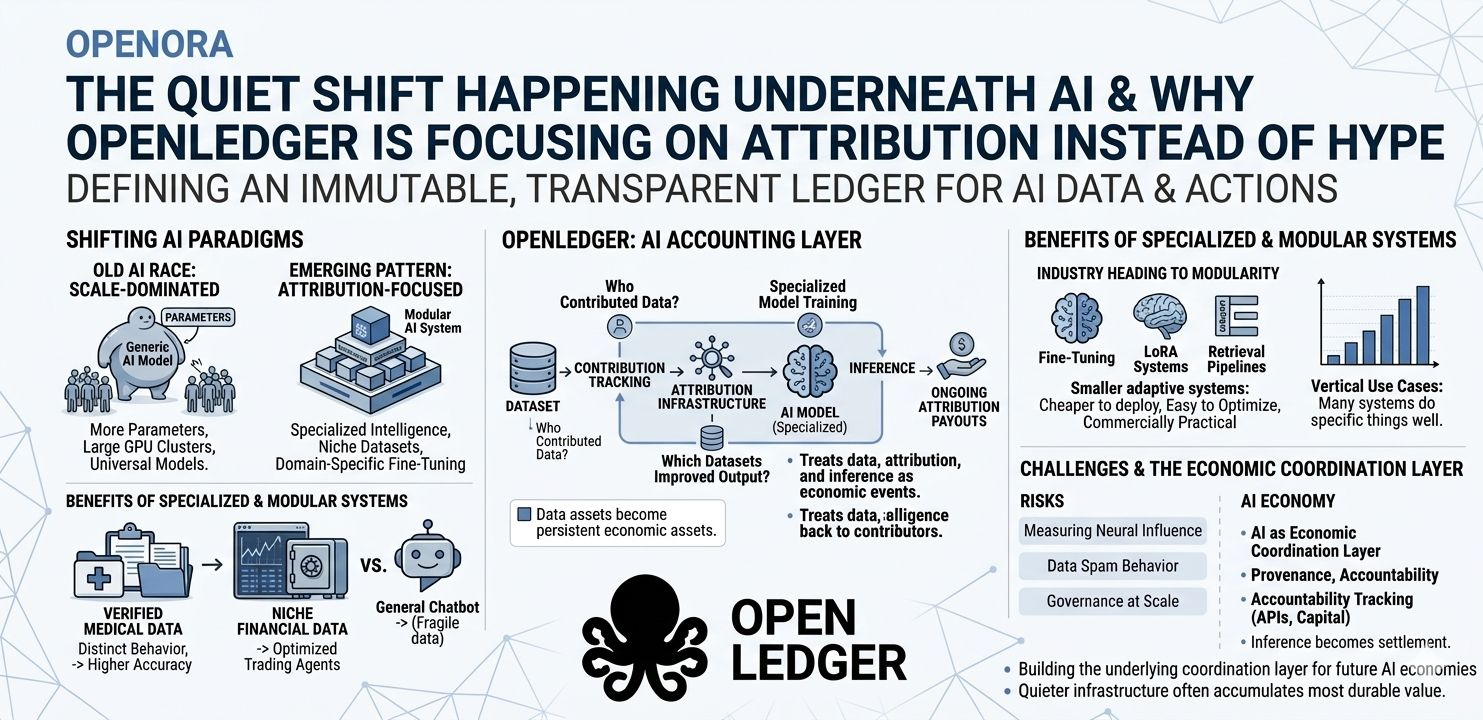
That is probably why OpenLedger’s direction around OpenLoRA and specialized model infrastructure feels more aligned with where the industry is actually heading. Smaller adaptive systems are cheaper to deploy, easier to optimize, and more commercially practical for vertical use cases. The texture of the market is changing from “one model does everything” toward “many systems do specific things well.”
There are risks to this approach of course.
Attribution itself is difficult. Measuring influence inside neural systems is not perfectly solved. Data quality can be manipulated. Economic incentives can create spam behavior if reward structures are weak. Governance systems around attribution also remain largely untested at scale. Even if the infrastructure works technically, adoption still depends on developers deciding transparency is worth the added complexity.
That remains to be seen.
Still, the direction itself feels increasingly relevant because AI is no longer just a research industry. It is steadily becoming an economic coordination layer. Agents are beginning to interact with capital, APIs, trading systems, marketplaces and real users in real time. Once AI starts participating directly inside economic systems, questions about provenance, accountability, and contribution tracking become harder to avoid.
What struck me is that OpenLedger seems less focused on competing with existing AI giants directly and more focused on building the infrastructure that sits underneath future AI economies. That is a quieter position, but sometimes quieter infrastructure becomes the layer everything else eventually depends on.
Crypto markets tend to chase visible applications first. The accounting systems underneath usually arrive later. But historically, those underlying coordination layers are often where the most durable value accumulates.
The interesting part is that OpenLedger is trying to build that accounting layer before the broader market fully realizes it needs one.