

Artificial intelligence is experiencing an unprecedented explosion. Every week brings new models, new capabilities, and new applications. But behind this exciting growth lies a dirty secret that the AI industry rarely talks about:
Running multiple AI models is extraordinarily expensive and inefficient.
Most AI infrastructure today is wasteful. Companies deploy massive models on dedicated hardware, consuming enormous amounts of energy and compute for tasks that could be handled by smaller, more efficient systems. The result is an AI industry that is simultaneously revolutionary and deeply unsustainable.
OpenLedger recognized this problem early. Their answer is OpenLoRA — one of the most technically innovative solutions in the entire AI blockchain space.
What Is OpenLoRA?
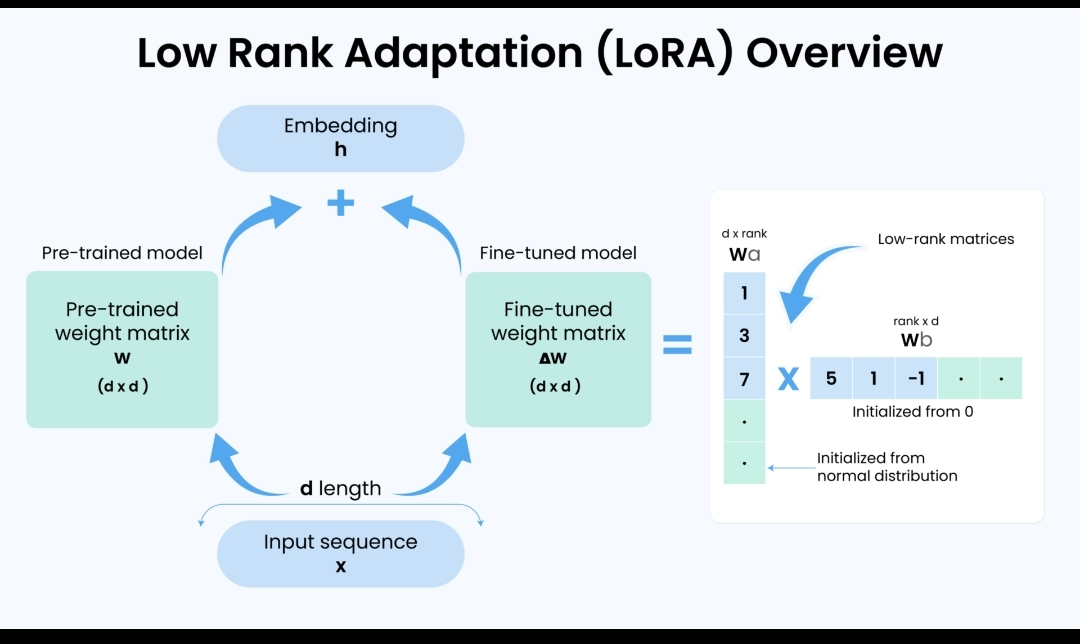
OpenLoRA is OpenLedger's proprietary model deployment and optimization framework. The name comes from LoRA — Low-Rank Adaptation — a cutting-edge technique in machine learning that allows large AI models to be fine-tuned and specialized for specific tasks without retraining the entire model from scratch.
In simple terms, OpenLoRA allows multiple specialized AI models to run efficiently on the same hardware infrastructure — dramatically reducing costs, energy consumption, and deployment complexity.
Think of it like this: instead of buying a separate car for every trip you take, OpenLoRA gives you one vehicle that can instantly transform into whatever you need — a sports car, a truck, a bus — depending on the task at hand.
The Problem OpenLoRA Solves
To appreciate OpenLoRA's significance, you need to understand the current state of AI deployment infrastructure.
The Traditional Approach — One Model, One Server
Today most AI deployments work like this: a company trains a large model, deploys it on dedicated servers, and runs it continuously whether it is being used or not. If they need a different model for a different task, they deploy another server. And another. And another.
This approach has three massive problems:
Problem 1 — Cost
Running large AI models on dedicated hardware costs thousands of dollars per month per model. For companies deploying dozens of specialized models, infrastructure costs can reach millions annually. This creates an enormous barrier that keeps advanced AI accessible only to well-funded corporations.
Problem 2 — Energy Waste
Dedicated servers running at partial capacity 24/7 consume enormous amounts of electricity. The environmental cost of this inefficiency is staggering — and growing exponentially as AI adoption accelerates.
Problem 3 — Inflexibility
When demand shifts — when one model suddenly needs more capacity while another sits idle — traditional infrastructure cannot adapt quickly. You are stuck paying for resources you are not using while struggling to scale the ones you need.
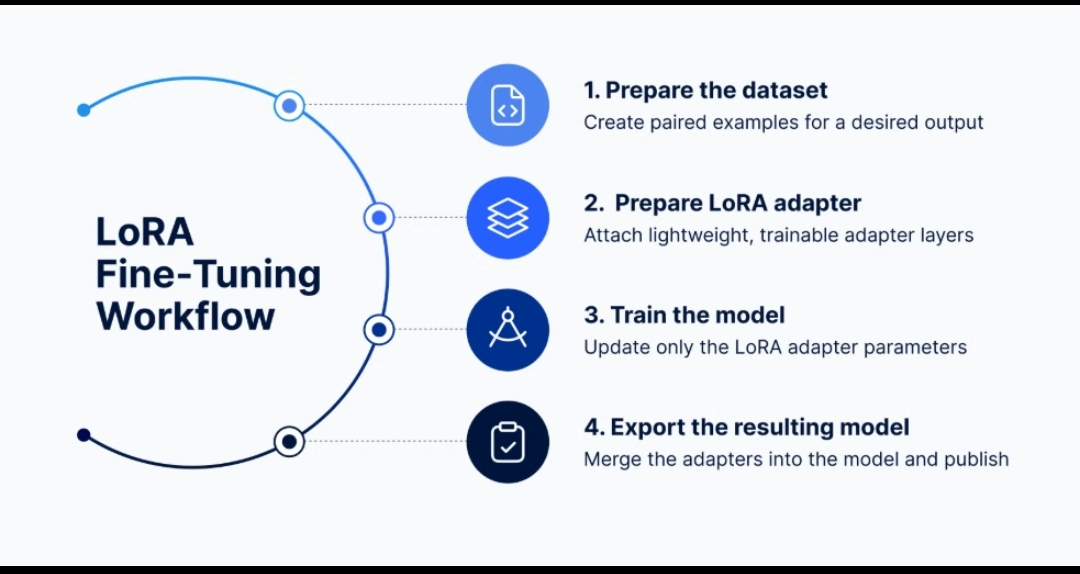
How OpenLoRA Works
OpenLoRA solves all three problems simultaneously through a revolutionary approach to model deployment.
Base Model + Adapters Architecture
Instead of deploying complete separate models for every task, OpenLoRA uses a shared base model with lightweight specialized adapters — the LoRA layers — that can be swapped in and out instantly.
Here is the technical breakdown:
Step 1 — Shared Foundation
A powerful base model is deployed once on the OpenLedger infrastructure. This base model contains the core intelligence — language understanding, reasoning capability, general knowledge.
Step 2 — Specialized Adapters
For each specific use case — medical diagnosis, legal analysis, financial forecasting, creative writing — a small lightweight adapter is trained using data from the relevant Datanet. These adapters are tiny compared to full models — sometimes just 1% of the original model size.
Step 3 — Dynamic Switching
When a request comes in, OpenLoRA instantly loads the appropriate adapter on top of the base model. The result is a fully specialized model for that specific task — at a fraction of the computational cost of running a dedicated model.
Step 4 — On-Chain Coordination
All of this switching, loading, and resource allocation is coordinated on-chain through $OPEN token transactions. Every inference request, every adapter deployment, every resource allocation creates on-chain economic activity that rewards the ecosystem.
Real World Applications of OpenLoRA
The practical implications of OpenLoRA are enormous across every industry:
Healthcare
A hospital network deploys OpenLoRA with adapters for radiology analysis, drug interaction checking, patient outcome prediction, and clinical documentation. All four specialized models run on shared infrastructure at a fraction of the traditional cost. Doctors get AI assistance across every workflow without million-dollar infrastructure budgets.
Legal Services
A law firm deploys adapters for contract analysis, case law research, regulatory compliance, and document drafting. Each adapter is trained on specialized legal Datanets from OpenLedger. Junior associates get AI assistance that would previously have required separate enterprise tools for each function.
Financial Services
A trading firm runs adapters for sentiment analysis, technical pattern recognition, risk assessment, and portfolio optimization — all on shared infrastructure, all coordinated through $OPEN, all contributing to the data economy through Proof of Attribution.
Education
A learning platform deploys adapters for different subjects, different learning styles, and different age groups. One infrastructure investment powers personalized AI tutoring across an entire curriculum.
OpenLoRA's Impact on $open Token Value
OpenLoRA is not just a technical innovation — it is a powerful driver of $open token demand.
Every adapter deployment requires $OPEN. Every inference request processed through OpenLoRA generates $open transaction fees. Every new use case added to the ecosystem creates new demand for the token.
As OpenLoRA adoption grows — and the efficiency advantages over traditional deployment become undeniable — the volume of $open transactions will increase dramatically. Combined with the burn mechanism built into every transaction, this creates powerful upward pressure on $OPEN value.
More adapters = More inferences = More $open burned = Scarcer supply = Higher value per token.
The math is straightforward. The opportunity is enormous.
OpenLoRA vs. Traditional Deployment: By the Numbers
The efficiency gains from OpenLoRA are not marginal — they are transformational:
Infrastructure costs: Up to 70% reduction compared to dedicated model deployment
Energy consumption: Up to 60% reduction through shared compute utilization
Deployment time: From weeks to minutes for new specialized models
Scalability: Unlimited adapters on shared infrastructure vs. dedicated servers per model
These numbers represent the difference between AI being accessible only to billion-dollar corporations and AI being accessible to every business, developer, and individual on the planet.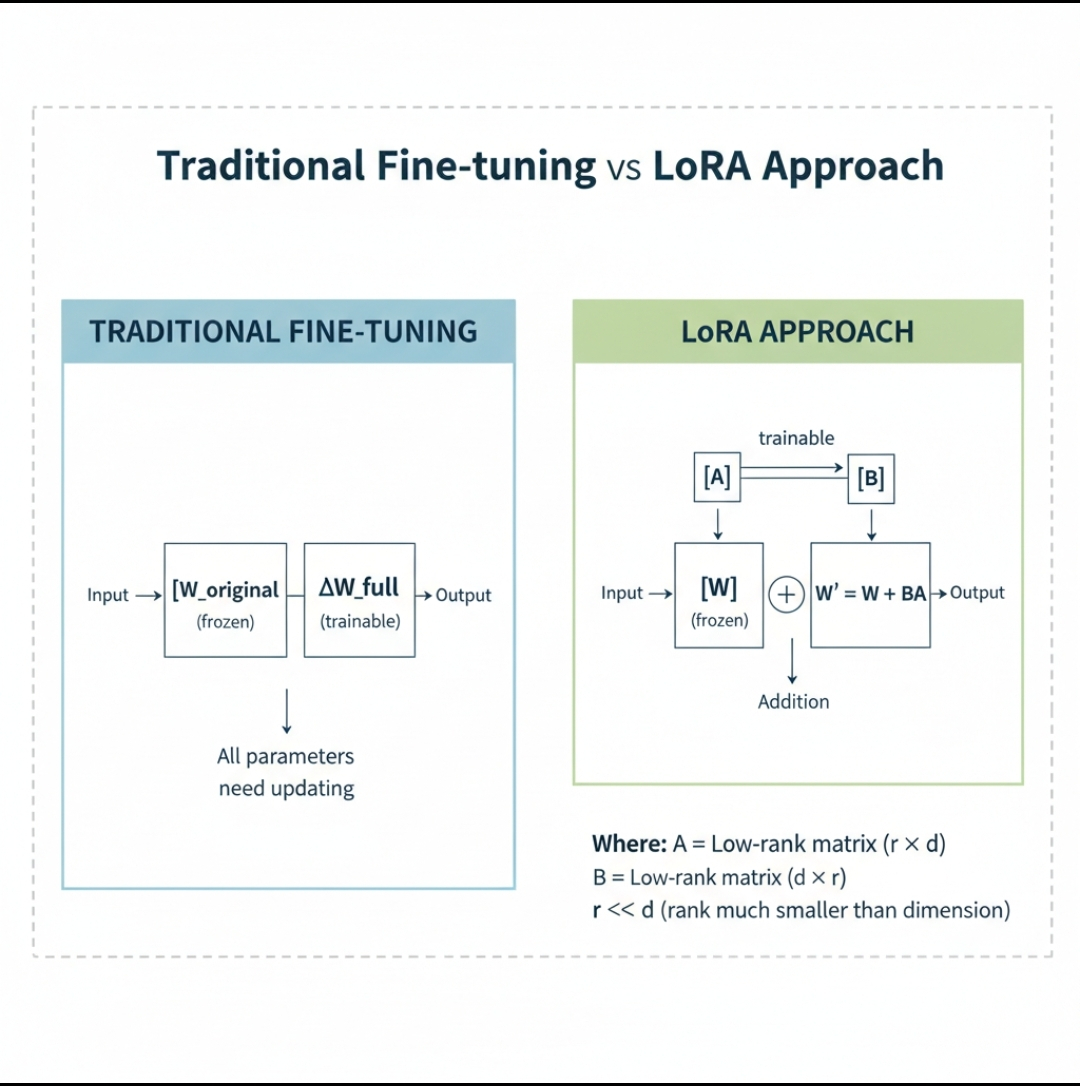
Conclusion
OpenLoRA is OpenLedger's answer to one of the most pressing challenges in modern AI infrastructure — how do you deploy specialized intelligence at scale without breaking the bank or destroying the environment?
The answer is elegant, efficient, and economically powerful. Shared base models. Lightweight specialized adapters. On-chain coordination through $OPEN. Dynamic switching that responds to real-time demand.
This is not just a better way to run AI models. It is the foundation of a sustainable AI economy — one where efficiency is rewarded, specialization is accessible, and every transaction creates value for the entire ecosystem.
OpenLoRA is live. The infrastructure is being built. And $OPEN is the token powering every single inference.
The question is not whether this technology will reshape AI deployment. It already is.
The question is whether you are positioned to benefit from it.