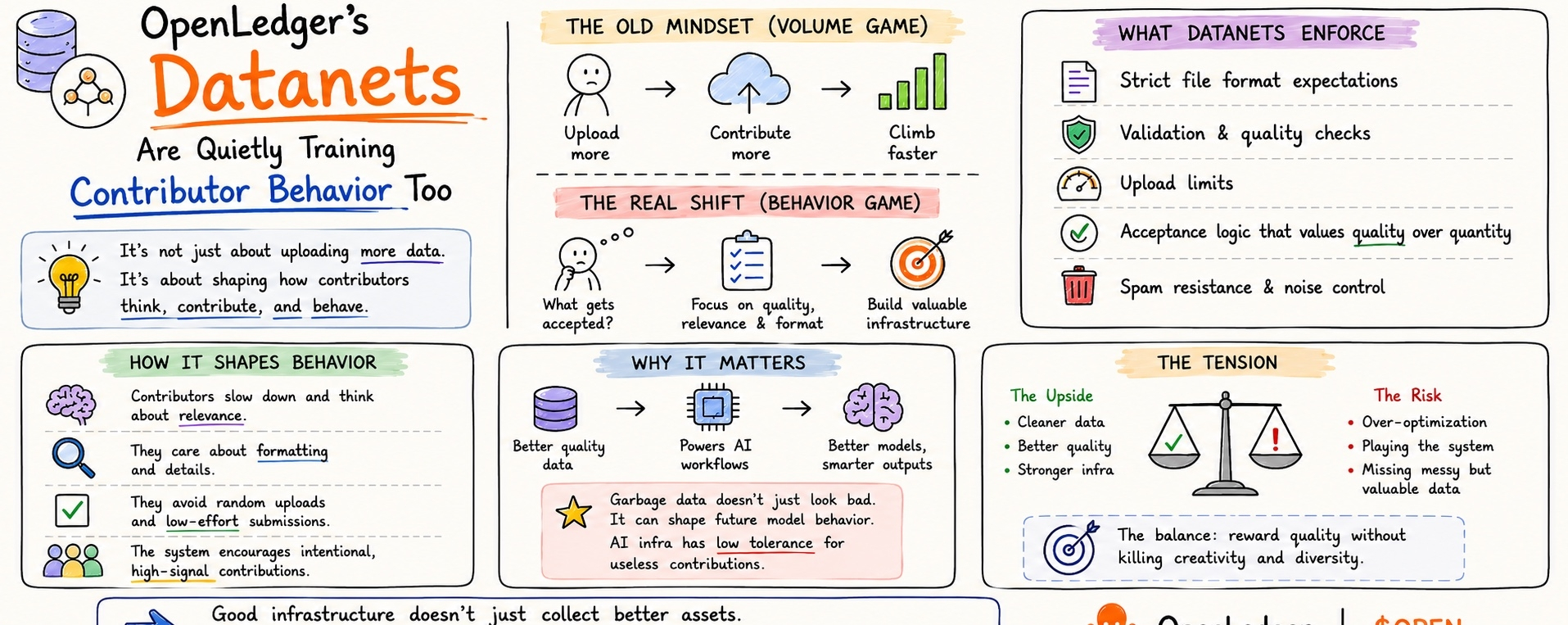
When people hear “data contribution,” the first assumption is usually volume.
Upload more.
Contribute more.
Climb leaderboard faster.
That’s how most systems train people to think.
But the more I looked into OpenLedger’s Datanet contribution mechanics, the less it felt like a volume game and more like a behavior design experiment.
And honestly, that’s more interesting.
Because OpenLedger doesn’t seem to be asking for more data.
It seems to be asking contributors to behave differently around data.
That’s a big distinction.
At first glance, some of the contribution restrictions actually feel weird.
Strict file format expectations.
Validation requirements.
Upload limits.
Acceptance logic that cares more about contribution quality than mindless quantity.
If you come from the usual Web3 mindset, your first reaction is probably:
“wait… shouldn’t this be more open?”
That was mine too.
Because decentralization usually gets marketed with this very romantic energy where everything is permissionless and infinite and everyone contributes whatever they want forever.
Sounds fun.
Also sounds like a spam disaster.
And that’s where OpenLedger’s design starts making more sense.
Because unlimited contribution doesn’t automatically create useful infrastructure.
It often creates noise with better branding.
A Datanet only becomes valuable if the data inside it stays usable.
That changes the psychology completely.
The contributor is no longer thinking:
“how much can I upload?”
They start thinking:
“what actually gets accepted?”
That shift matters.
Because once acceptance becomes part of the loop, behavior changes.
People slow down.
They think about relevance.
They care about formatting.
They think twice before throwing random junk into the pipeline.
And honestly, that’s probably healthy.
Especially if the long-term goal is AI infrastructure that depends on usable signal instead of community enthusiasm alone.
What I find interesting is how subtle that design pressure is.
Nobody has to explicitly say:
“please behave better.”
The system architecture says it for them.
That’s smarter.
Because incentive design usually works better than instructions.
And this becomes even more important when you remember Datanets are not just storage.
That data can eventually feed actual AI workflows.
ModelFactory fine-tuning.
Specialized model behavior.
Agent reasoning.
Downstream outputs.
That makes bad contribution quality much more expensive than a messy dashboard.
Garbage here doesn’t just look ugly.
It can shape future model behavior.
That raises the standard.
And maybe that’s exactly why the Datanet design feels more controlled than people expect.
Not because OpenLedger wants less openness.
Because AI infrastructure has a much lower tolerance for useless contribution than social platforms do.
That said… there’s also an interesting tension here.
Any system that rewards acceptance starts shaping contributor psychology.
People optimize.
That’s just human behavior.
The upside is cleaner submissions.
The risk is over-optimization.
People may start submitting what feels “acceptable” instead of what’s genuinely useful but messy.
That balance is tricky.
Still, I think OpenLedger gets credit for recognizing something a lot of ecosystems ignore:
good infrastructure doesn’t just collect better assets.
It changes contributor behavior before the asset even arrives.
And if Datanets actually become meaningful AI infrastructure, that behavior layer may matter just as much as the data itself.