在Web3和AI的叙事里摸爬滚打这么多年,我这张老脸早就被各种小作文、精美PPT和闭眼就要颠覆OpenAI的宏大愿景弄麻木了。满大街都是去中心化算力,动不动就用代币买几张显卡拼个小作坊,就宣称自己是AI新纪元。说实话,这种空气概念除了给团队提供拉盘口号,对实际的生产力没有半点改变。
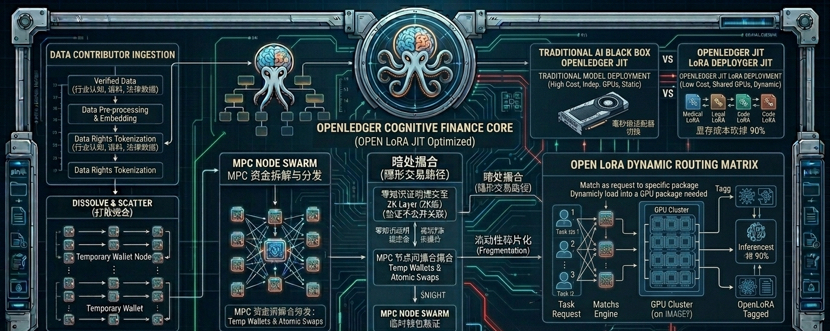
最近盯着 @OpenLedger 的技术白皮书死磕了几天。大家都在聊它的DataNets或者贡献度证明,这套话术圈内人一听就懂,无非是想解决数据所有权。但我今天不想复述这些陈词滥调。作为老编码,我更关注技术文档深处藏着的那个为了解决计算成本而设计的硬核机制——Open LoRA与即时适配器切换(Just-in-Time Adapter Switching)。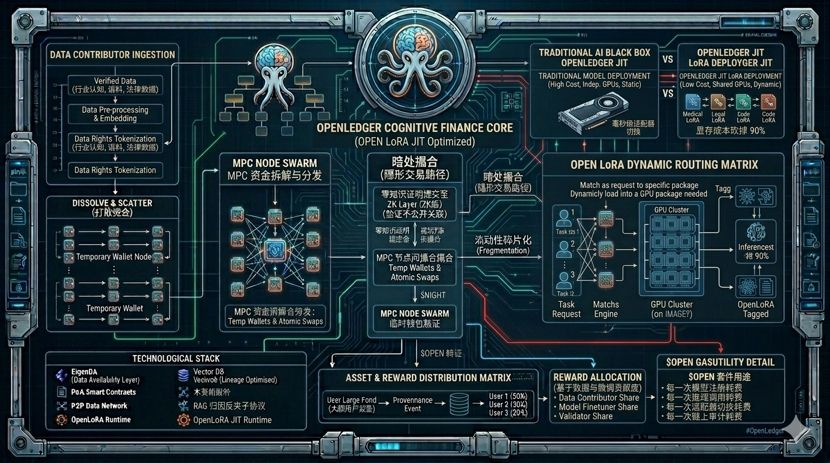
这就是我想聊的干货。懂AI的人都知道,现在大模型微调成本高得吓人,传统的做法是给每个特定任务都跑一个独立的高昂模型,或者把所有大显存全堆在服务器里动都不敢动。OpenLedger这个JIT切换机制,通俗点说,就像是一个极速的“换壳游戏”。底座大模型是不动的,但当不同的推理请求进来时,系统能在单张GPU上,以毫秒级的速度动态加载和卸载不同的LoRA轻量化微调包。
这就把原本沉重的、需要几张显卡独立伺候的专有模型,变成了可以共享底座、随用随插的轻量化组件。官方数据显示这能把部署成本砍掉90%以上。这才是一个务实的Web3项目该干的事:用区块链做账本,把真正的底层工程优化做到极致,而不是整天高喊口号去和传统算力巨头硬碰硬。
在它的底层, $OPEN 作为原生Gas,不是用来炒作的积分,而是每一次模型注册、每一次推理调用、每一次验证者过账都必须消耗的硬套件。如果这种即时切换的调度没有区块链做链上的确定性审计,那AI黑盒永远都是黑盒。数据提供者拿着自己的垂直数据去喂模型,通过这个机制,每一次毫秒级的适配器调用,都能对应到链上的贡献记录,这才是真正能跑通的Cognitive Finance(认知金融)。
吐槽归吐槽,这个赛道依然难走。概念很硬核,工程落地难度也极大。现在整个生态还在极早期,数据吞吐量和调用频次还没到真正检验性能的生死关头。在币安上看到它的动静,我觉得至少在方向上,它没有去卷那些虚无缥缈的算力幻觉,而是把锄头挥向了整个AI行业最脏、最不透明的角落——数据归属与动态调度的透明化。
往深了说,这其实是一场关于“硅基文明记账权”的争夺。人类过去几千年都在为碳基生物的劳动和资产记账,而当AI开始自我演进、自我微调时,谁来为算法的每一次呼吸和进化留下不可篡改的痕迹?我们需要的不是另一个模仿硅谷的中心化垄断者,而是一个能让每一个代码片段、每一滴数据都有名有姓的数字旷野。从这个角度看, #OpenLedger 走出的这一步,或许才是把技术交还给协作集体该有的姿态。