
混迹Web3快十年,经历了几个牛熊周期,我早就不信那些靠几页精美PPT和宏大叙事支撑的项目了。尤其是现在的加密AI赛道,满大街都是“我有算力,你有故事,大家一起发币”的空气组合。但这几天翻完 @OpenLedger 的技术白皮书,我发现这帮人切入的角度有点不一样,甚至有点不合群。
当大伙都在疯狂卷去中心化算力、卷谁的LLM参数更大的时候,这个项目却盯着一个极度枯燥且容易得罪人的方向:数据溯源和利益分配。
大家心里都清楚,现在大模型最核心的矛盾不是代码,而是干净、高质量的数据。大厂在明目张胆地白嫖全网内容,而创作者一毛钱拿不到。OpenLedger 的核心逻辑是搞了一个叫“归因证明”(Proof of Attribution)的东西,意思就是只要你往它的 DataNets 里面贡献了有效数据,或者参与了模型微调,哪怕以后这个模型只在一次对话里用了你贡献的一小段知识,系统都能通过链上记录追踪到,并且把收益分给你。$OPEN 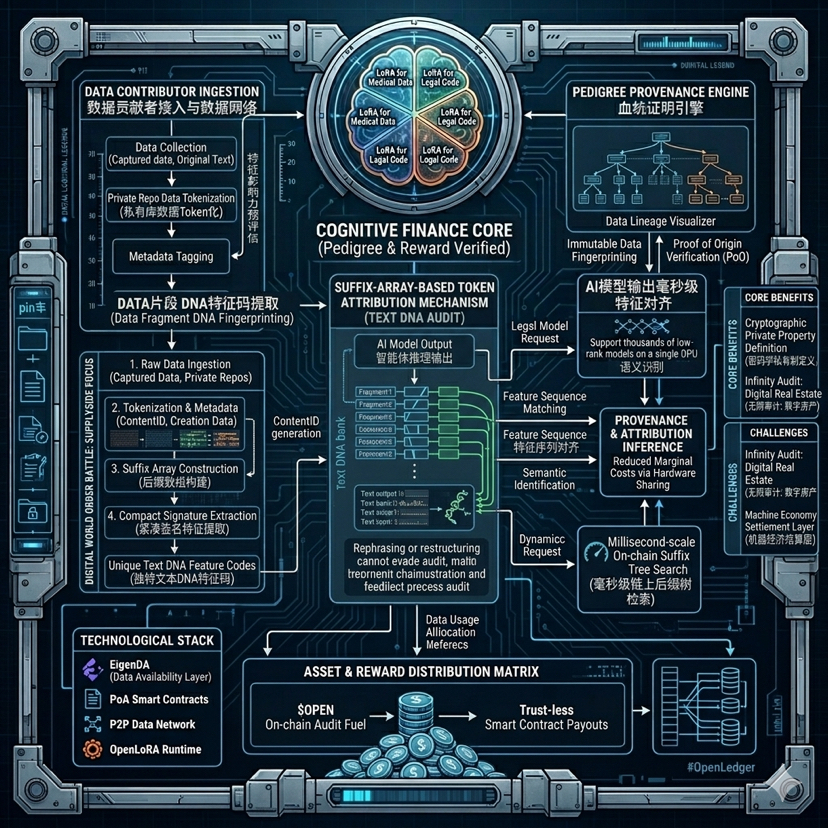
这个想法接地气,听起来像是“内容变现”的区块链升级版。但我更想聊聊白皮书深处藏着的、极少被市场提及的一个深层构架——**后缀数组令牌归因(Suffix-Array-Based Token Attribution)**。
别被这个生硬的学术名词吓跑,用大白话翻译:如果说以前的数据检测像是在一堆乱草里找一根一模一样的针(只要词句稍微改改就抓不到了),那这个后缀数组机制就像是在给每一个数据片段建立一套类似DNA特征码的快速索引。当大模型输出一段话时,这套算法能在毫秒级的时间内,把输出的内容和海量的数据源进行高精度的文本片段对齐。这就意味着,哪怕有人把你的数据洗稿、重组,只要核心语义和特征序列还在,它的底层审计轨就逃不掉。
这才是做“机器经济”结算层该有的硬核态度。你得先有这种近乎偏执的底层文本审计能力,所谓的 $OPEN 代币在生态里的结算、质押和Gas消耗,才不至于变成空中楼阁。要不然,每天几百万次AI智能体的调用和推理,光是链上对齐数据的计算成本,就能把一条链活活卡死。
不过,作为老韭菜,我习惯了看破不说破。愿景再好,骨感的现实依然摆在眼前。OpenLedger 现在的打法是纯粹的供给侧思维,先用代币激励去把高质量的专业数据集(DataNets)和模型工厂圈起来。这种做法在技术上很扎实,但在币圈有个致命的弱点——冷启动太慢。在泡沫漫天的市场里,大家更愿意去追逐那些三秒钟就能让人血脉喷张的土狗币,很少有人愿意坐下来,等一个AI智能体网络真正跑出有机的、可持续的数据调用流。如果后期的开发者生态和AI Agent的实际调用量跟不上,再硬核的归因算法,最后也只是在和空气斗智斗勇。
这才是真正考验团队格局的地方。他们是在认认真真地给未来的硅基生命时代修一套物权法和结算铁路,还是在讲一个更高级的学术故事?目前看,他们把注意力放在数据所有权和开发者工具上,至少比那些单纯炒作算力概念的土狗要务实得多。
往深了说,这其实是一场关于数字世界底层秩序的博弈。人类几百年来的经济学,全部是建立在“碳基生命”对实体资产的所有权之上的。而当AI开始满互联网跑、自己生产内容、自己消费算力、自己完成交易的时候,我们现有的法律和经济学全都是失效的。
#OpenLedger 做的事情,本质上是在尝试用密码学的确定性,去定义硅基时代的第一缕“私有制”。数据不再是阅后即焚的流量,而是可以被无限次审计、可以沉淀资产价值的数字房产。这个方向注定极其艰难,甚至可能因为走得太早而成为先烈。但在这个充满了投机、高通胀和伪创新的行业里,我宁可看到有人去碰这种真正硬核的硬骨头,也不想再看到第一百个毫无意义的Layer 2或者纯MEME的狂欢。这或许才是加密技术在这个混乱时代,唯一能留下的、具有神性微光的坐标。