
The Evolution of AI Labor: Moving from "One-Time Workers" to a Royalty Economy
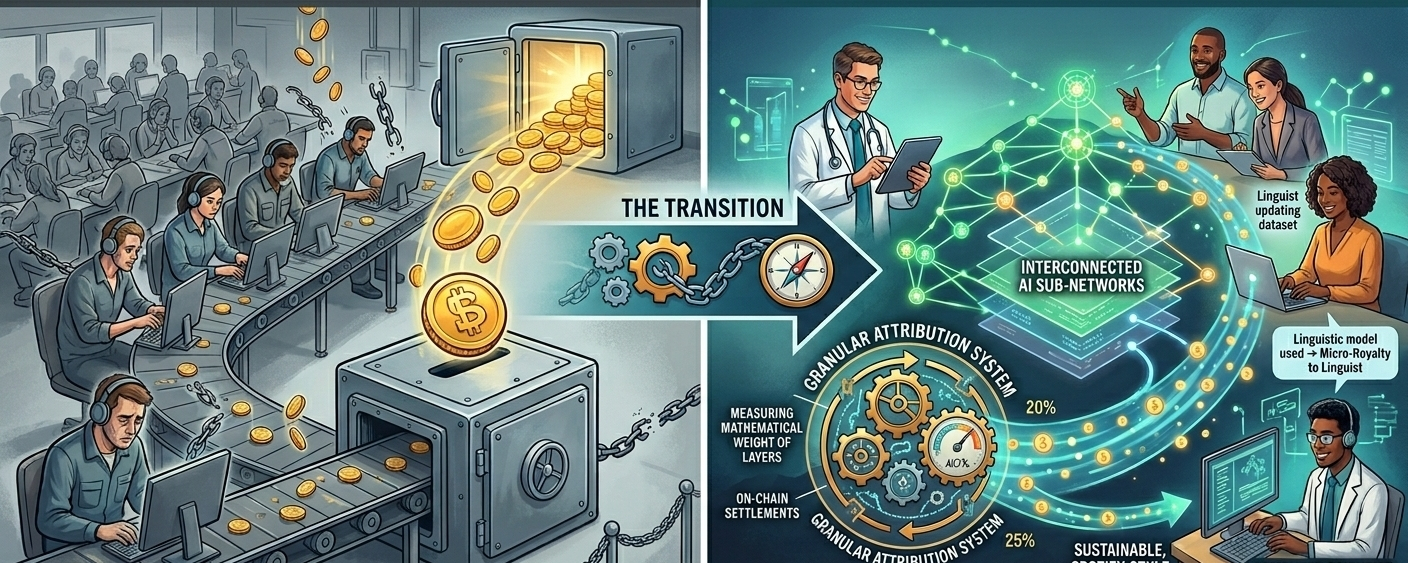
The current AI data landscape is built on a fundamental structural flaw. The extraction paradox, data contributors, annotators and fine tuners are treated as disposable gig workers. They receive a one-time upfront payment to train or fine-tune a model, while the model operators capture the long-term, compounding value as the AI scales. Once your specialized dataset or fine-tuning layer is absorbed into the weights, your financial connection to that model is severed forever. OpenLedger is attempting to completely upend this paradigm. By merging the principles of the creator economy with decentralized AI infrastructure, they are moving the industry away from data piecework and toward a sustainable, Spotify style royalty economy.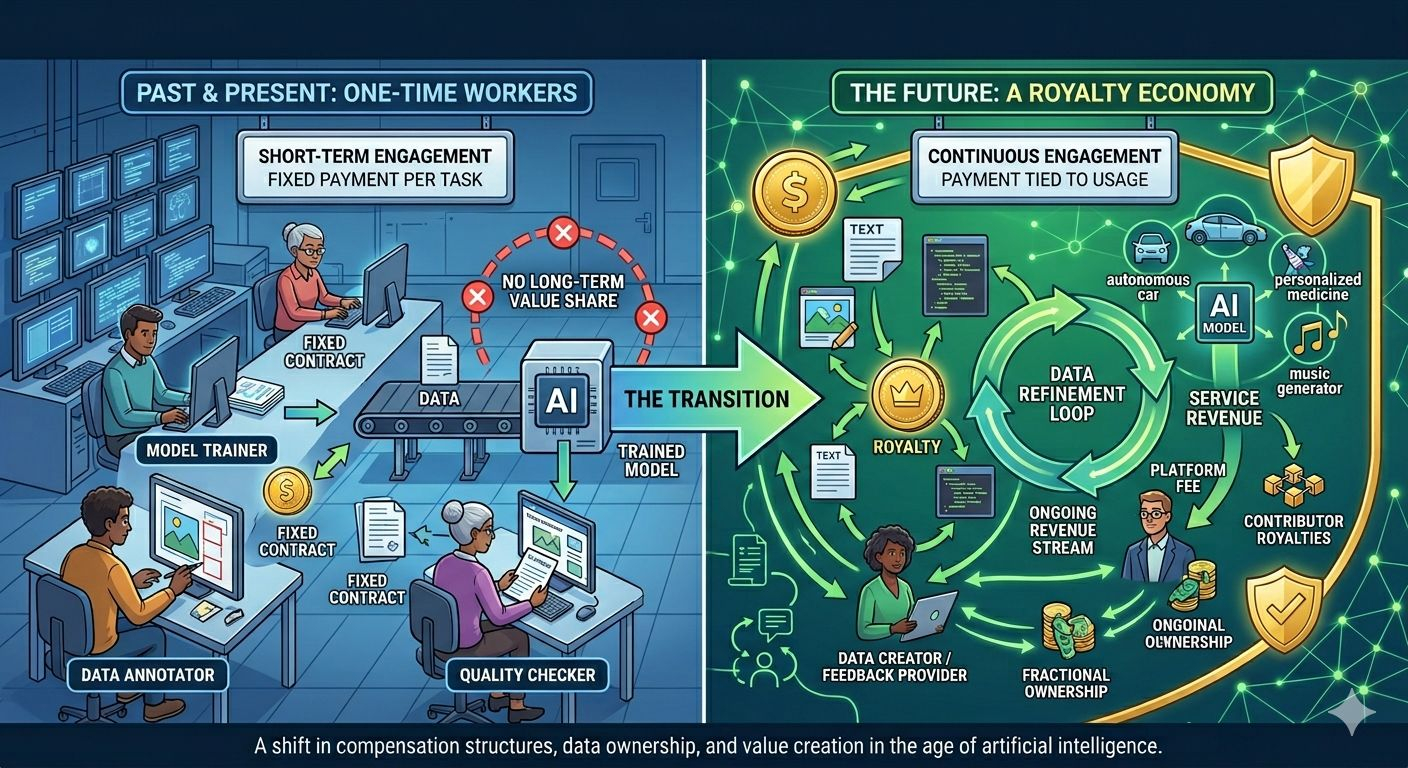
If AI development shifts toward a royalty driven model, the psychology of data contribution changes entirely. It transforms from a short-term transactional task into long-term asset management. Imagine a niche medical professional who spends hours fine-tuning a specialized healthcare AI to improve diagnostic accuracy. In the traditional model, they get paid a flat fee and that is it. The model goes on to process millions of commercial queries, saving hospitals thousands of dollars but the doctor sees none of it. Under the OpenLedger model, that same data or fine tuning layer is cryptographically tracked. Every time that specific sub network is activated to solve a complex medical query, a micro royalty is programmatically routed back to the creator.
The core thesis makes sense on paper but the execution relies entirely on solving a massive technical hurdle: granular attribution. If multiple contributors are fine tuning the same model or optimizing the same output layer, determining who deserves what percentage of the reward is incredibly complex. If the attribution system fails or lacks transparency, it introduces immediate friction, governance conflicts and sybil vulnerabilities. This is exactly why OpenLedger is positioning itself as a data provenance and coordination layer. To make a royalty economy work, the infrastructure must seamlessly track data provenance to prove exactly who provided what data, measure the actual mathematical weight a specific layer provides to the overall accuracy and execute on-chain settlements frictionlessly without letting fees eat into the contributor's margins.
While the upside is massive, a sustainable royalty model faces severe headwinds. Quantifying the exact impact of a single dataset inside a massive neural network is notoriously difficult. If thousands of users contribute high-quality data to a single LLM, calculating a fair, conflict free royalty distribution requires incredibly precise, transparent algorithmic auditing. Furthermore, if foundational models and fine-tuning pipelines become highly commoditized and race to zero cost, the margin available to fund a continuous royalty layer shrinks. OpenLedger will need to prove that models built on high-incentive, recurring-contribution loops are fundamentally superior to cheap, static open-source alternatives.
The AI economy cannot remain sustainable if the people behind the data are treated as one time factory workers. To scale specialized, hyper accurate AI, we need elite contributors who are incentivized to continuously maintain, update and optimize their datasets. If OpenLedger can successfully build the attribution infrastructure required to handle this complexity, they will establish the framework for a new asset class where data creators retain equity in the intelligence they help create.