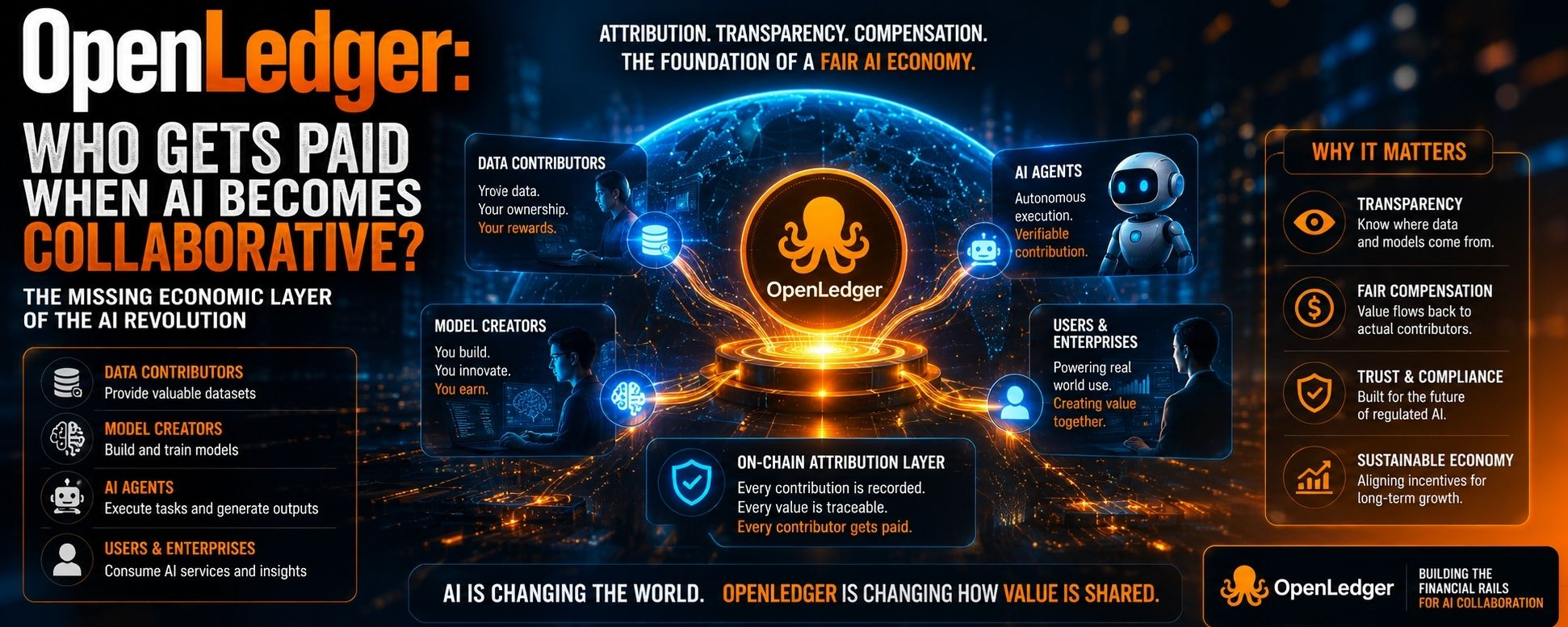
I keep thinking about how strange the AI economy has become.
Everyone talks about models. Bigger models. Faster models. Smarter agents. But almost nobody talks about the invisible people and datasets underneath them. It reminds me of modern food supply chains where consumers see the restaurant brand, not the farmers, transport systems, or storage networks keeping everything alive behind the scenes.
That’s why OpenLedger caught my attention differently from most AI tokens.
Not because it claims to be “AI on blockchain.” Honestly, that phrase has already lost meaning from overuse. What interested me was the deeper idea hiding underneath the branding: OpenLedger is trying to make contribution traceable inside AI systems. In other words, it wants data, models, and agents to behave less like black boxes and more like financial participants.
That changes the conversation completely.
The current AI industry operates like a giant blender. Data goes in, outputs come out, and nobody really knows who deserves economic credit afterward. A researcher contributes niche medical data, another team fine-tunes a model, an agent executes tasks using both layers, and suddenly value appears at the top while the lower layers become invisible.
OpenLedger is trying to solve that invisibility problem.
What makes this interesting is that they are not approaching AI from the usual “compute marketplace” angle. Most crypto-AI projects are obsessed with GPUs because compute is easy to market. OpenLedger seems more focused on attribution and payment routing. That sounds boring at first, but infrastructure that controls attribution can become more valuable than infrastructure that simply processes computation.
Spotify is actually the analogy I keep returning to.
Before streaming, music ownership was static. After streaming, every play became measurable economic flow. OpenLedger feels like an attempt to bring that kind of accounting system into AI. Every dataset contribution, inference request, or model interaction potentially becomes something measurable and compensable.
That’s a much bigger shift than people realize.
The recent developments around the project made this idea feel more concrete rather than theoretical. Their mainnet launch changed the tone of the conversation because it moved the project from “concept” into operational infrastructure. Most AI tokens are still trading almost entirely on imagination. OpenLedger now has to prove actual economic coordination works in practice.
And the Story Protocol collaboration was more important than most traders noticed.
A lot of people saw another partnership headline and moved on. But I think that partnership quietly revealed where OpenLedger may eventually fit inside the AI industry. Not as a chatbot layer. Not as another speculative agent ecosystem. More like an accounting framework for AI licensing and provenance.
That matters because regulation is slowly pushing AI toward traceability whether the industry likes it or not.
Companies increasingly need answers to uncomfortable questions. Where did training data come from? Was it licensed? Who deserves compensation? Which outputs relied on which sources? Most AI systems today are terrible at answering those questions clearly.
OpenLedger seems to believe attribution itself can become infrastructure.
And honestly, that’s a contrarian bet because most users do not care about attribution today. People care about convenience. They care about speed. Nobody asks ChatGPT where every sentence originated from before using it.
That’s why I think many people misunderstand the real potential customer for networks like OpenLedger.
It may not be retail users at all.
It could be enterprises, media companies, publishers, healthcare systems, or regulated industries that eventually require transparent contribution tracking. If that happens, attribution stops being a philosophical discussion and starts becoming operational necessity.
The network metrics are also more interesting when viewed through that lens. OpenLedger reported millions of registered nodes, tens of millions of processed transactions, and thousands of AI models built during testnet phases. Crypto metrics always deserve skepticism, but even adjusted numbers suggest meaningful participation behavior.
The important part is not raw scale.
It’s behavioral conditioning.
The project spent months teaching users to think of AI contribution as something economically rewarded rather than passively extracted. That psychological shift matters more than most people think. Successful crypto ecosystems usually reshape user expectations before they reshape industries.
The token itself also feels misunderstood.
Most people still evaluate OPEN like a standard utility asset, but its deeper role is coordination. It connects validators, model creators, data contributors, and inference consumers into one incentive layer. That is structurally different from tokens whose only purpose is speculation or governance theater.
The airport analogy makes sense here.
Passengers only notice airplanes, but airports function because thousands of invisible systems coordinate timing, routing, fuel, security, luggage, and maintenance simultaneously. OpenLedger is attempting to build that hidden coordination layer for AI ecosystems.
The challenge, though, is whether attribution actually creates enough economic gravity on its own.
That’s the uncomfortable question most supporters avoid.
Because attribution sounds morally valuable, but markets do not reward morality automatically. They reward necessity. If attribution increases friction without delivering measurable business value, adoption becomes difficult no matter how elegant the architecture looks.
This is where the next phase becomes critical.
The network needs recurring inference demand, enterprise integrations, and genuine economic usage rather than incentive-driven participation loops. Otherwise it risks becoming another technically impressive protocol searching for sustainable demand after speculation fades.
I also think people underestimate the risk of unlock pressure here. The circulating supply remains relatively low compared to the total supply structure, and infrastructure projects usually mature slower than market expectations. If ecosystem activity grows slower than token emissions, that imbalance eventually shows up in price behavior regardless of narrative quality.
Still, there’s something intellectually different about OpenLedger compared to the average AI token cycle.
Most projects are trying to own intelligence.
OpenLedger appears to be trying to own attribution.
And those are not the same business.
One is competing in a crowded race toward better outputs. The other is trying to build financial rails underneath the entire supply chain. If AI eventually becomes regulated, licensed, and attribution-sensitive at scale, that second layer may quietly become far more important than people currently expect.
That’s why I think OpenLedger is worth watching even beyond market cycles.
Not because it promises artificial intelligence.
But because it is asking a deeper question most of the industry still avoids:
Who gets paid when intelligence becomes collaborative?
