I used to think the most important question in AI + Web3 was who owns the data.
After reading OpenLedger more closely, I started to think that was the wrong question.
The real issue is not just ownership. It is measurement.
Because the moment a project tries to turn human contribution into something tradable, rewardable, and on-chain, it is no longer simply building infrastructure. It is building a system that decides what your work is worth. And once that happens, the design stops being abstract. It becomes political, economic, and strangely personal.
That is what makes OpenLedger interesting to me.
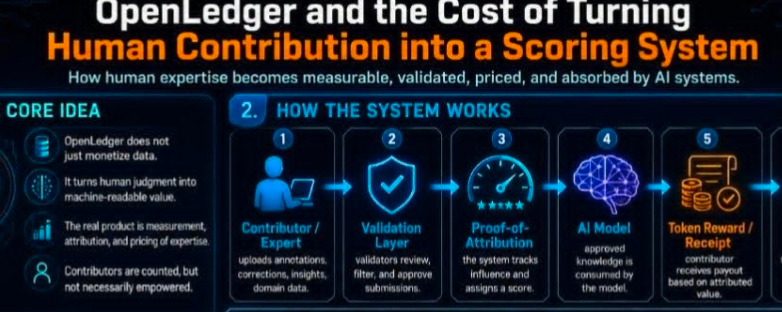
Most projects in this space talk about decentralization in a very loose way. They say users should control their data, contributors should get rewarded, and value should flow back to the community. All of that sounds good. But OpenLedger is trying to do something more ambitious and more difficult: it wants to assign economic meaning to the act of contributing itself.
That sounds fair until you think about how hard it actually is.
A dataset is not just a dataset. A model update is not just a model update. A correction, an annotation, a training signal, a review, a piece of domain knowledge — all of these carry value, but not in a simple or stable way. Their usefulness changes depending on context, timing, and how the model later uses them. So when a system says it can “recognize” contribution, what it is really saying is that it can compress messy human labor into a pricing framework.
That is a big claim.
And honestly, that is where the whole thing starts to feel less like a tech product and more like an operating model for human labor in the AI era.
OpenLedger’s appeal is that it tries to reverse a very old pattern. For years, the internet economy has worked like this: people create things, platforms absorb the value, and the original creator gets a tiny slice of recognition if they are lucky. The work gets reused, the system gets richer, and the person who actually made the thing often disappears behind the interface.
OpenLedger is trying to interrupt that flow.
Instead of letting value get swallowed by the platform layer, it wants to keep the link between contribution and reward alive from the beginning. On paper, that feels more honest than the usual AI stack, where users feed the machine and never see what comes back. But the more I looked at the actual structure, the more I realized the project is not just trying to distribute value more fairly. It is trying to build a framework that can price value with enough precision to make ownership operational.
That is the tricky part.
Because pricing human contribution is not the same thing as appreciating it.
A system can be very accurate and still feel cold. It can record everything and still miss the human meaning of the work. That tension sits right at the center of OpenLedger. The project wants to create a transparent path from contribution to reward, but transparency alone does not solve the problem of value. You still have to decide what counts, how much it counts for, and who gets to verify that decision.
Once you introduce that layer, the system becomes much more than a ledger. It becomes a gatekeeper.
And gatekeeping always changes the feel of a network.
The validator layer is a good example of this. In theory, validators protect quality. They make sure the network is not flooded with garbage. They help maintain trust. That sounds sensible. But they also sit between contributors and the economic outcome of their work. That means the person who creates value is not the only one shaping the value path. There is another group — the validators — that can slow things down, filter things out, and influence what makes it through.
That may be necessary. It may even be unavoidable. But it also means the network is not simply rewarding participation. It is ranking participation through a system of filters.
That is a much more rigid design than people may realize.
And it creates a second problem: scale.
The more exact the system becomes, the harder it is to keep it lightweight. If every contribution has to be scored, traced, validated, and settled across a distributed network, then the overhead starts to grow. That is fine when a project is small or the workflows are narrow. But if the goal is to support real, large-scale AI labor, then the system has to survive a lot of messy input, imperfect behavior, and conflicting incentives.
That is where many elegant designs begin to strain.
The technical challenge is not just to record contribution. It is to do it without making the network so slow and expensive that the economics collapse under their own weight.
There is also a behavioral problem that sits underneath everything else.
The second people know that a system rewards contribution, they start optimizing for the reward. That is not a moral failure; it is just how incentives work. But once that happens, the network becomes vulnerable to people producing work that looks valuable but is really designed to game the scoring logic. In other words, the system has to defend not only against low-quality data, but against strategically disguised low-quality data.
That is a brutal task.
If the network spends too much effort filtering bad contribution, then the cost of defense rises. And if defense gets too expensive, the system begins spending more to protect value than it earns from creating it. That is when a contribution economy starts to lose its balance.
So the promise of fair reward is only half the story.
The other half is whether the network can tell the difference between real value and performance.
That is a very hard problem, because AI systems already blur that line. People know how to sound useful. They know how to package information. They know how to make inputs look professional. A system like OpenLedger has to decide whether it is rewarding actual usefulness or just rewarding the ability to look useful inside a formal structure.
That is not a small detail. It goes right to the heart of whether the model is fair or just structured.
And then there is the question of participation.
A lot of projects say they are open to everyone, but that openness usually narrows once the technical layer gets serious. The tools are harder to use. The rules are harder to understand. The value flows toward people who already know how to operate in the system. So even if the project is decentralizing ownership in theory, the practical benefits may still concentrate among a smaller group of contributors with more expertise, more time, and better access.
That is where the “for the people” promise starts to weaken.
It is not that the system fails completely. It is that the people who benefit most are often not the broad public but the group that can best navigate the structure.
That does not make OpenLedger meaningless. It just makes it more complicated.
Because on one hand, it is clearly trying to build something better than the old AI economy. It wants contributors recognized. It wants value traced. It wants the internet’s invisible labor to become visible enough to matter. That is a real improvement over the usual black-box model where platforms take most of the upside and users get almost nothing back.
But on the other hand, once value becomes measurable, it also becomes controllable.
And that is the deeper tension I keep coming back to.
Maybe the real innovation here is not decentralization itself. Maybe it is the attempt to create a system where human work cannot be absorbed without leaving a trace. That is a powerful idea. It could even be the beginning of a more honest AI economy.
Still, the project has to prove something important before that idea becomes real: it has to show that measuring contribution does not end up turning the network into a machine that prices people too tightly and excludes them too quietly.
That is the line OpenLedger is walking.
And in my view, that is what makes it worth watching. Not because it has solved the problem, but because it has finally exposed the problem in a form that is hard to ignore.