I was watching a cluster of automated execution agents slow themselves down during what should’ve been a completely normal liquidity cycle. No major volatility. No oracle failure. No giant liquidation event smashing through the system. Everything on the surface looked stable.
But the agents started acting weird anyway.
Execution routes changed. Confidence thresholds tightened. Some inference paths got deprioritized almost instantly. And honestly, that’s what pulled me deeper into OpenLedger in the first place because the trigger wasn’t market movement.
It was internal state changes.
That’s the part people don’t talk about enough.
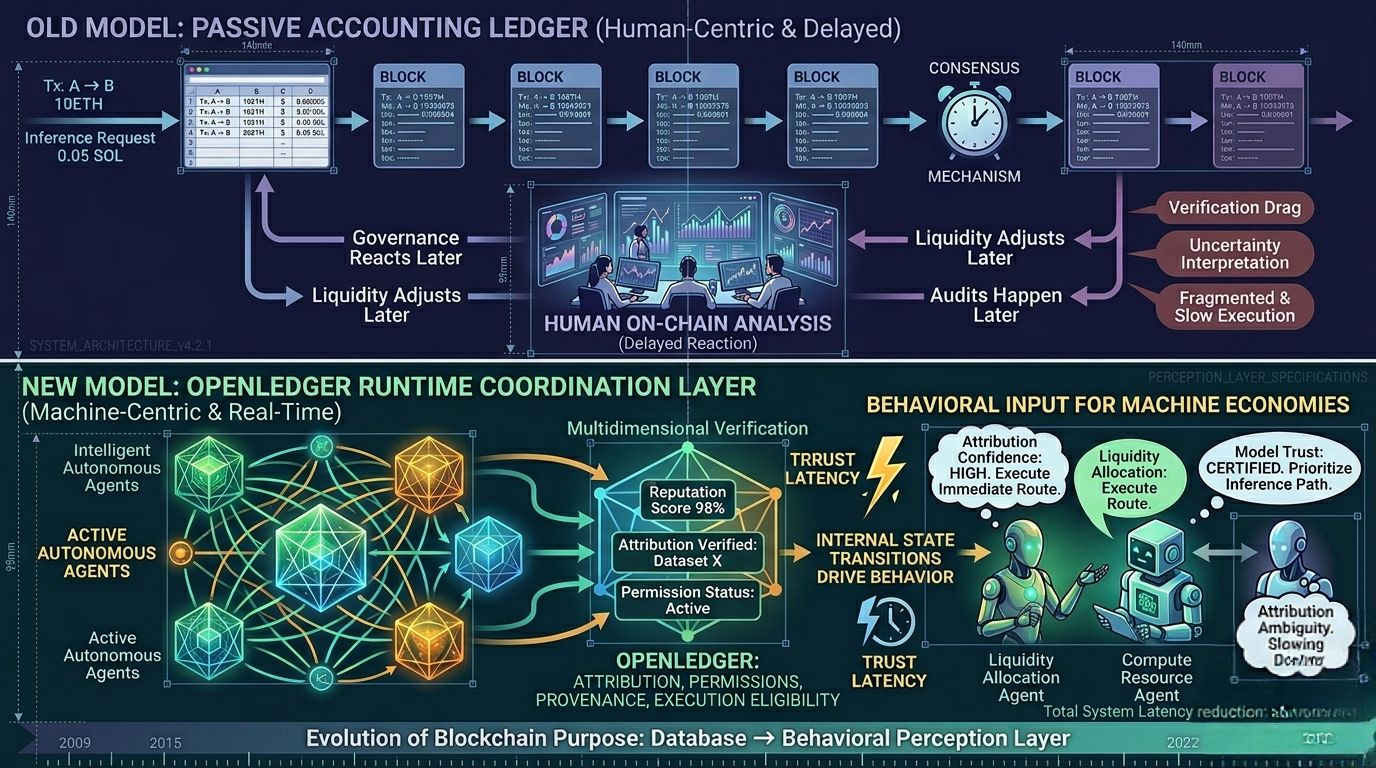
Most crypto people still treat blockchains like giant accounting spreadsheets with consensus attached to them. Data goes in. Transactions finalize. Humans look at dashboards later and pretend they’re doing “on-chain analysis.” Same cycle every day.
Even a lot of AI-chain projects still think this way. Faster inference. Better GPU coordination. More decentralized compute. Cool. Fine. But here’s the thing nobody really wants to admit:
AI systems don’t care about narratives.
They care about certainty.
An autonomous agent can’t stop every few seconds and ask, “Hey, does this attribution layer look trustworthy to humans?” Machines don’t work like that. They need deterministic state confidence before they execute anything meaningful.
And once you start thinking from that angle, OpenLedger stops looking like another AI-token story and starts looking more like coordination infrastructure for machine behavior itself.
Big difference.
I’ll be honest, I think people massively underestimate verification drag. Everybody obsesses over transaction throughput and compute scaling while ignoring the ugly part underneath the system — proving whether something inside the environment is actually trustworthy enough for autonomous execution.
That’s the real bottleneck.
Not compute.
Not storage.
Not TPS.
Trust latency.
Yeah. That’s the problem.
Because an agent allocating liquidity, routing inference, accessing a model, or purchasing data doesn’t just care whether the chain finalized a transaction. It cares whether the state behind that transaction actually carries enough confidence to justify action.
That changes the entire architecture conversation.
And that’s where OpenLedger gets interesting.
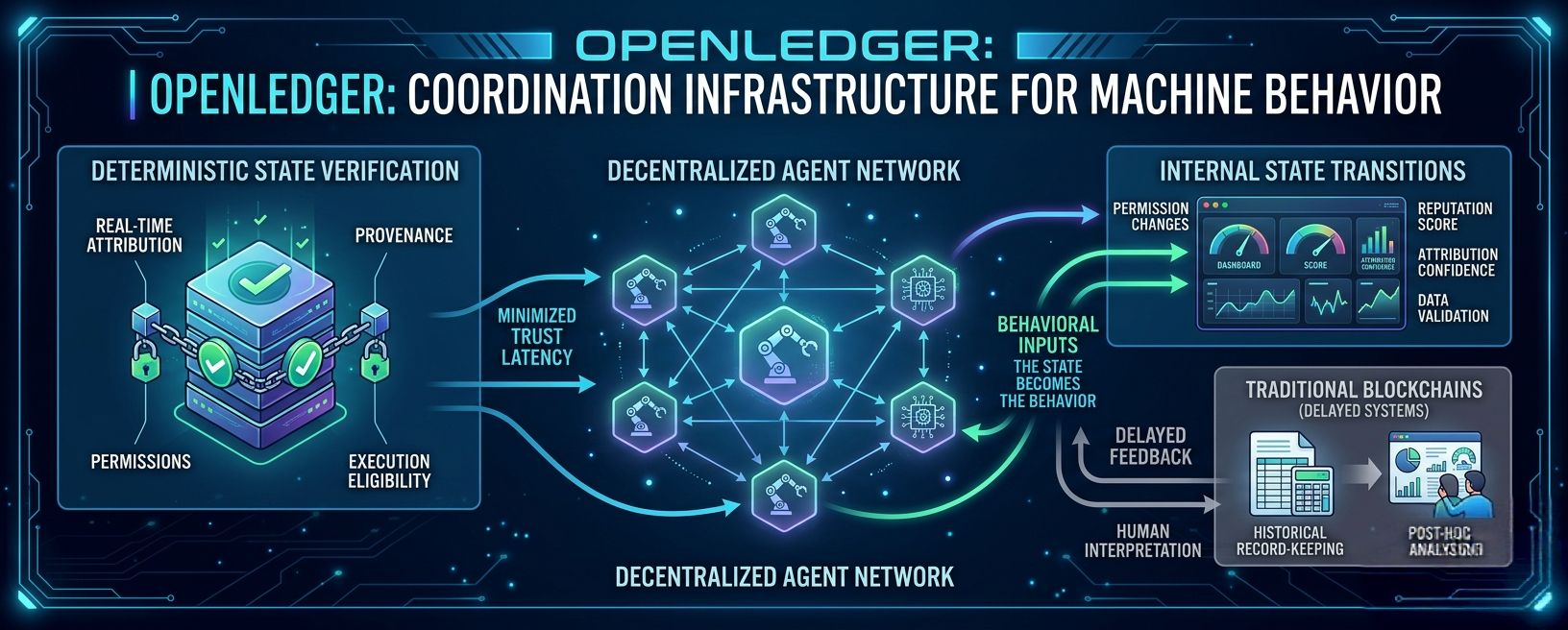
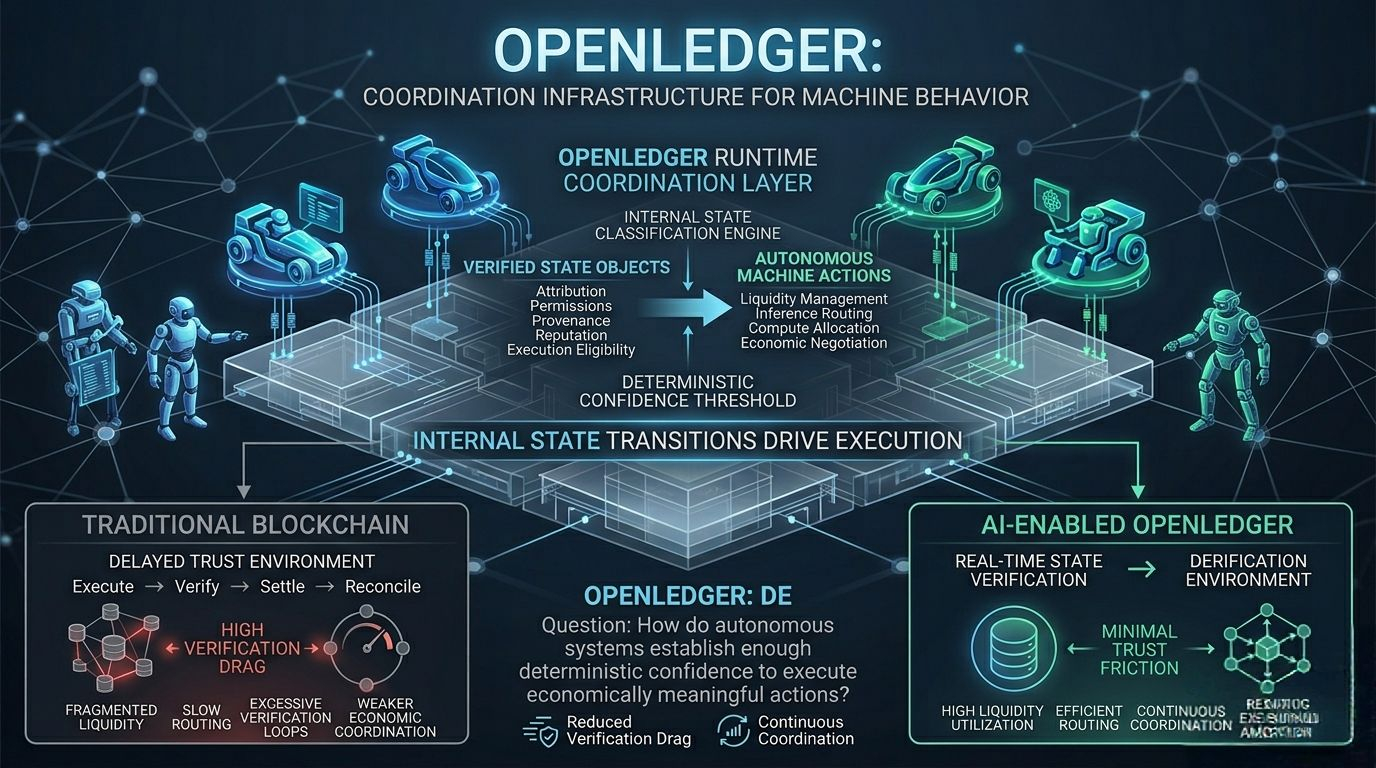
The more I watched the system, the less it looked like a traditional ledger and the more it looked like a runtime coordination layer where attribution, permissions, provenance, and execution eligibility actively shape machine behavior in real time.
Not later.
Right now.
That distinction sounds small until you realize how different the implications are.
Traditional blockchain systems mostly work after the fact. They record what already happened. Humans interpret the data afterward. Governance reacts later. Liquidity adjusts later. Audits happen later.
Everything’s delayed.
Humans can tolerate that because humans improvise around uncertainty all the time. We contextualize things socially. Machines don’t. Autonomous systems need operational clarity immediately or they start behaving defensively.
And defensive systems are slow systems.
I’ve seen this before in trading infrastructure. The moment confidence drops even slightly, systems start widening thresholds everywhere. Routing becomes conservative. Execution fragments. Liquidity utilization gets worse. Suddenly the whole environment feels heavier even though the raw infrastructure technically still works.
That’s exactly why attribution infrastructure matters more than most people realize.
People keep framing attribution like it’s just some IP rights discussion or creator economy feature. I don’t think that framing holds anymore. In machine economies, attribution becomes execution logic.
That’s a completely different category.
A verified attribution object isn’t just historical metadata anymore. It directly influences whether agents trust a dataset, whether models get prioritized, whether liquidity routes through certain environments, whether compute resources get allocated efficiently.
The state itself becomes behavioral input.
That’s the shift.
And honestly? I think this is where the entire industry is quietly heading even if most people still frame everything in old financial language.
Because look at what’s happening structurally.
Traditional systems separate execution, verification, settlement, and reconciliation into different phases. First activity happens. Then people verify it. Then systems reconcile balances later. Then risk teams evaluate exposure afterward.
That workflow breaks once autonomous agents start coordinating continuously across distributed systems.
Machines can’t operate efficiently inside delayed trust environments.
So infrastructure starts evolving toward real-time state verification instead.
Not because it sounds futuristic. Because the old model creates too much friction.
That’s what I think OpenLedger is really trying to solve underneath all the AI branding.
Not “how do we store AI assets on-chain?”
That’s surface-level thinking.
The deeper question is:
How do autonomous systems establish enough deterministic confidence to execute economically meaningful actions without constantly slowing themselves down for verification overhead?
That’s the actual problem.
And it gets even more important once you realize the causal structure starts changing too.
Historically, most automated crypto systems reacted mainly to external market inputs. Price changes triggered behavior. Oracle updates triggered behavior. Funding shifts triggered behavior.
Now?
Internal state transitions increasingly drive the system instead.
Permission changes.
Attribution confidence changes.
Reputation score changes.
Execution eligibility changes.
Model trust changes.
The environment begins reacting to itself.
That’s a weird sentence, but it’s true.
And honestly, I don’t think people fully understand how dangerous this becomes when state classification fails.
Because once machines execute directly against verified state objects, a corrupted or inaccurate state doesn’t just create reporting problems.
It changes behavior.
Immediately.
A broken attribution relationship could distort liquidity allocation. A compromised trust layer could reroute inference traffic incorrectly. A synchronization mismatch could fragment agent coordination across multiple execution environments at once.
And since autonomous systems continuously react to each other’s interpreted confidence levels, errors start compounding recursively.
That’s where things get tricky.
This isn’t traditional accounting risk anymore.
It’s behavioral contamination risk.
Huge difference.
In older systems, you could sometimes isolate accounting mistakes for a while before they spread operationally. In autonomous machine economies, bad state propagation moves directly into execution pathways almost instantly.
That’s why deterministic verification suddenly matters so much.
Not for reporting.
For survival.
I think that’s also why a lot of current AI-chain narratives feel shallow to me. Too many projects still optimize around surface metrics like storage efficiency, compute marketplaces, or inference speed while ignoring the coordination layer underneath autonomous behavior itself.
But coordination is the hard part.
Always has been.
The more autonomous systems become, the more important behavioral synchronization becomes. Not just raw computational capability.
That’s why I keep coming back to OpenLedger’s architecture. The system appears designed around reducing ambiguity between verification and execution. That matters more than most people realize because ambiguity creates hesitation, and hesitation destroys machine efficiency fast.
Really fast.
A human can pause and reassess uncertainty manually. Autonomous systems can’t scale that way. They either trust the environment enough to execute efficiently or they compensate by becoming defensive.
And defensive machine systems create fragmented liquidity, slower routing, excessive verification loops, inefficient compute allocation, and weaker economic coordination overall.
People love talking about scaling throughput.
Cool.
But scaling uncertainty just creates bigger inefficiencies faster.
That’s the uncomfortable reality underneath a lot of current infrastructure discussions.
And honestly, I think the next infrastructure race won’t revolve around who stores the most data or processes the most transactions anymore.
That era’s fading.
The next race probably revolves around who translates verified state into reliable machine behavior most efficiently.
Who minimizes trust friction.
Who reduces execution ambiguity.
Who creates the strongest deterministic coordination layer for autonomous systems.
Because once AI agents start handling liquidity management, inference purchasing, compute allocation, data validation, and economic negotiation autonomously at scale, the blockchain stops acting like a historical database sitting quietly in the background.
It becomes part of the machine’s operational perception layer itself.
That’s a much bigger transition than most people realize.
And honestly?
I think we’re still very early in understanding what that actually means.