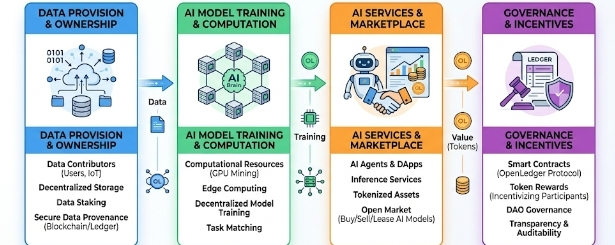
I used to think AI infrastructure discussions were mostly about scaling models, faster GPUs, and whoever trains the largest system. But when I opened the OpenLedger docs, I didn’t expect to stay longer than a few minutes.
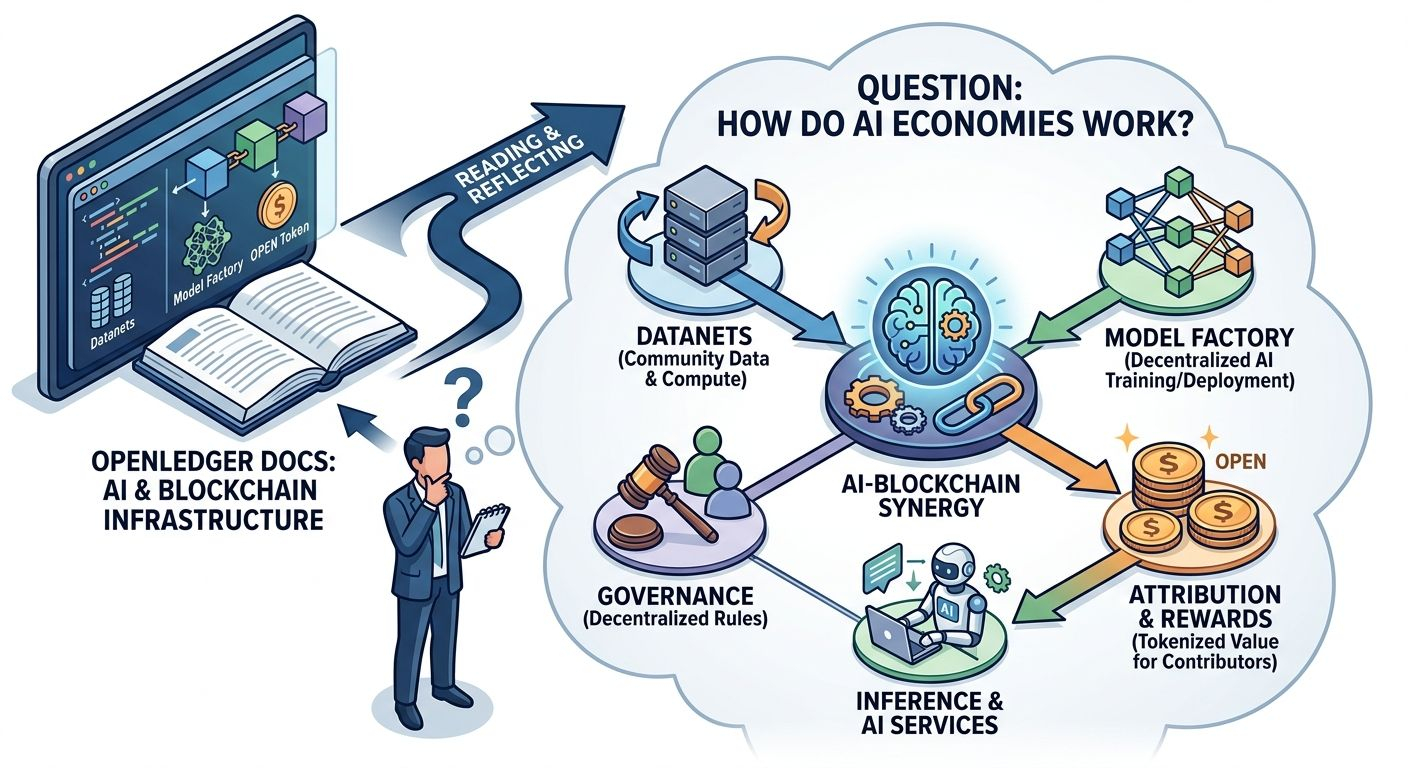
At first, I was just scanning. ModelFactory, OpenLoRA, a few technical explanations. Nothing unusual on the surface. But then a random memory distracted me my phone storage being full, deleting duplicate photos scattered across folders, the same image saved five times without me noticing.
That small moment started connecting strangely with what I was reading. It felt like some systems, not just personal storage, keep repeating effort without realizing it. Rebuilding similar components, re-running similar compute, isolated from each other.
What stood out to me in ModelFactory wasn’t just “no-code customization,” but the idea of lowering friction so models aren’t rebuilt from scratch every time. And OpenLoRA’s shared serving approach felt like the same direction shared infrastructure instead of fragmented deployments.
The more I read, the more it felt like the system is trying to reduce invisible repetition. Not just efficiency in speed, but efficiency in existence itself less duplicated compute sitting in separate silos.
But I could also see a tension. Shared infrastructure always introduces dependency. If everything is connected, failure domains expand. And incentives don’t always align builders might optimize locally even when global efficiency suggests otherwise.
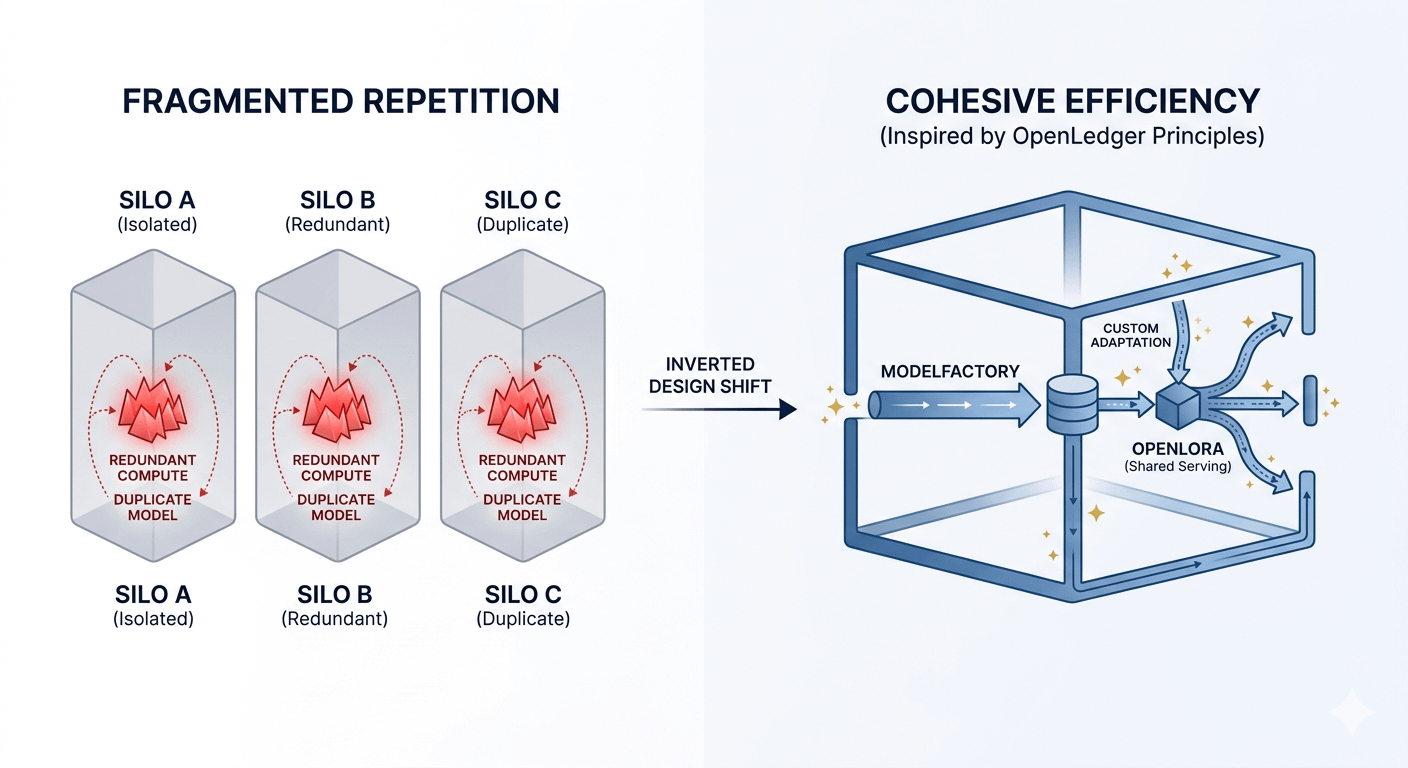
It made me think beyond AI. Most digital systems evolve by adding more layers, more tools, more duplication disguised as progress. But here, the focus feels inverted reduce repetition instead of increasing production.
Maybe it’s more about removing repetition than building more systems… or maybe not.