I’ll be real with you, the more I look at OpenLedger, the less I see it as a simple “data ownership” project.
That phrase has already been used too many times in Web3. Everyone says users should own their data. Everyone says contributors should be rewarded. Everyone says AI should not be controlled only by big platforms.
But saying that is easy.
The hard part is building a system where data can actually be trusted, priced, used, and paid for without turning the whole thing into another farming game.
That is why OpenLedger caught my attention.
At first, I thought it was just another AI + blockchain narrative. Nice wording, polished roadmap, familiar promises. But after reading deeper, I started to feel that the project is not only asking, “Who owns the data?” It is asking something more difficult:
How do you prove that data has value without exposing it, abusing it, or letting low-quality contributors destroy the network?
That question is much more serious.
My own experience made this topic feel less theoretical. After my self-trained AI model got flooded with fake calls, I realized how fragile small AI builders really are. Big companies can absorb cloud costs, buy datasets, pay for infrastructure, and survive abuse. Smaller builders cannot. One bad attack, one bad bill, one bad data pipeline, and the whole experiment becomes expensive.
So when OpenLedger talks about giving contributors a way to prove and monetize data, I don’t see it as just another slogan. I see it as a response to a real imbalance in the AI economy.
Right now, data is everywhere, but pricing power is not.
Users generate data. Developers generate data. Communities generate data. Small teams generate niche datasets. But the people who benefit most are usually the platforms with enough money, compute, and distribution to package that data into models.
OpenLedger is trying to insert a missing layer between raw contribution and AI value extraction.
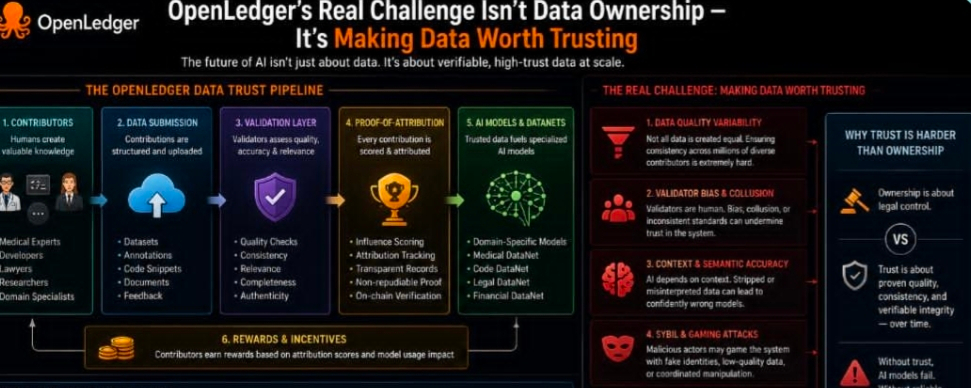
Its architecture makes more sense when viewed from that angle.
The first layer is not really about storing data on-chain. That would be a terrible idea. Instead, it focuses on provenance. In simple words, it tries to prove where data came from and who contributed it without showing the actual content.
That matters because data is not like a meme coin transaction. You cannot just expose everything publicly and call it transparency. Real data may include private, sensitive, or commercially valuable information. If a system cannot protect that, serious users will never join.
This is why zero-knowledge proofs and hash anchoring are important here. They allow the network to say, “This data contribution exists, and this person can prove it,” without forcing the original data into the open.
That is a practical design choice.
The second layer is where OpenLedger avoids one of the biggest traps in crypto infrastructure: pretending everything should happen on-chain.
AI training is heavy. It is messy. It requires constant computation, coordination, updates, and optimization. Moving the entire process onto a blockchain would be slow, expensive, and unrealistic.
OpenLedger seems to understand that.
Instead of turning the chain into a giant AI training machine, it uses the chain more like an accountability layer. The actual computation can happen off-chain, while the contribution records, usage logic, and reward distribution remain verifiable.
That is the right kind of restraint.
In crypto, restraint is underrated. Too many projects try to sound revolutionary by putting every process on-chain. But real engineering is often about knowing what not to put there.
The third layer is the user-facing part: the place where developers can actually access datasets, models, and related services. This layer is important because infrastructure without users is just theory. If developers cannot easily plug into it, the whole system becomes a beautiful machine nobody touches.
Then comes the bigger idea: Datanets.
This is probably the most interesting and most dangerous part of the roadmap.
The idea is that different industries or use cases can have their own data networks. Medical data, financial data, trading data, gaming behavior, robotics data, language data — each vertical could form its own marketplace where contributors provide data and AI builders pay to use it.
In theory, that is powerful.
It means data does not have to sit uselessly in isolated pockets. It can become an asset layer. A small contributor with valuable niche data could finally have a way to participate in the AI economy instead of being silently absorbed by larger systems.
But this is also where the hard questions begin.
A Datanet is only valuable if both sides show up.
Data providers need a reason to contribute. Model builders need a reason to pay. Evaluators need a reason to judge quality honestly. Node operators need enough activity to stay online. If one side is missing, the network becomes weak.
This is the cold-start problem.
Early incentives can help, but they can also attract the wrong crowd. Crypto history has shown this again and again. When rewards are too attractive, farmers arrive before real users. They do not care about the network. They care about extraction.
That is why OpenLedger’s data-quality mechanism is so important.
A data economy without quality control becomes garbage very quickly. People will upload repeated data, fake data, low-effort data, or manipulated data just to earn rewards. Once that happens, real model builders lose trust, and the whole marketplace starts collapsing from the inside.
OpenLedger’s approach is to make evaluators stake value behind their judgment. If they assess data correctly, they earn. If they judge poorly or dishonestly, they risk losing something.
This is a better approach than simply hoping people behave well.
Because in open networks, morality is not enough. Incentives matter more.
Still, the current unanswered part is collusion.
What happens if evaluators work together? What happens if a group creates fake data, fake evaluations, and fake demand? What happens if the system becomes a closed circle of insiders rewarding each other?
These are not minor edge cases. These are the exact attacks every incentive network eventually faces.
So for me, OpenLedger’s future depends heavily on whether its quality layer becomes strong enough to resist gaming.
Another serious issue is compliance.
People often ignore this because it sounds less exciting than AI models and token incentives. But compliance could become the wall that blocks adoption.
Different countries treat data differently. Some regions care deeply about deletion rights and user consent. Blockchain, meanwhile, is designed around permanence. That creates tension.
If OpenLedger wants to work with serious data providers, it cannot simply say, “Governance will solve it later.” It needs a practical framework for privacy, deletion requests, regional restrictions, and enterprise usage.
The good thing is that the project does not seem completely blind to this. But recognition is not the same as resolution.
That is why my view remains balanced.
I don’t think OpenLedger should be dismissed as just another AI narrative. There is real thinking in the architecture. The separation between proof, compute, and application access is sensible. The Datanets idea has genuine potential. The quality-staking model is pointed in the right direction.
But I also don’t think it deserves blind hype yet.
The gap between a smart whitepaper and a working data economy is massive.
The real test will be whether OpenLedger can create demand beyond token incentives. Can model builders actually find useful data there? Can contributors earn enough to stay? Can the network punish bad data without scaring away honest users? Can Datanets grow naturally after early rewards slow down?
Those are the questions that matter.
For now, I see OpenLedger as an experiment in whether data can become a real on-chain economic primitive.
Not just “your data, your ownership.”
That slogan is too small.
The bigger question is:
Can data become a verifiable, usable, quality-controlled asset that ordinary contributors can actually earn from?
If OpenLedger can prove that, it will not just be another Web3 AI project. It could become part of the missing infrastructure layer between human contribution and machine intelligence.
That is why I’m watching $OPEN.
Not because the narrative is loud.
Because the problem is real.