Càng theo dõi thị trường AI và crypto lâu, tôi càng có cảm giác rằng phần lớn các cuộc thảo luận về dữ liệu phi tập trung đang xoay quanh một câu hỏi tương đối dễ nhìn thấy nhưng chưa chắc đã là câu hỏi quan trọng nhất.
Chúng ta thường nghe về số lượng dữ liệu. Dự án nào thu hút được nhiều contributor hơn. Dự án nào xây được marketplace lớn hơn. Dự án nào sở hữu nhiều nguồn dữ liệu hơn. Gần như toàn bộ cuộc cạnh tranh thường được mô tả như một cuộc đua tích lũy tài nguyên.
Nghe hoàn toàn hợp lý. AI cần dữ liệu. Mô hình tốt hơn thường cần nhiều dữ liệu hơn. Vì vậy việc tập trung vào nguồn cung dữ liệu dường như là hướng đi tự nhiên.
Nhưng càng nhìn kỹ, tôi càng thấy dữ liệu chưa bao giờ là thứ thực sự khan hiếm.
Internet đã chứa lượng thông tin khổng lồ. Mỗi ngày hàng tỷ tương tác mới tiếp tục xuất hiện. Vấn đề không phải là thế giới thiếu dữ liệu. Vấn đề là thế giới đang có quá nhiều dữ liệu nhưng lại thiếu những cơ chế hiệu quả để xác định dữ liệu nào thực sự hữu ích, dữ liệu nào tạo ra kết quả tốt hơn và dữ liệu nào tiếp tục giữ được giá trị khi hành vi con người thay đổi theo thời gian.
Đó là lý do tôi thấy khá thú vị khi đặt OpenLedger cạnh nhiều decentralized data projects xuất hiện trong vài năm gần đây.
Phần lớn các dự án dữ liệu phi tập trung được xây dựng dựa trên một giả định quen thuộc. Nếu chúng ta tạo ra đủ động lực để người dùng đóng góp dữ liệu, dữ liệu sẽ được thu thập, thị trường sẽ hình thành và cuối cùng giá trị sẽ xuất hiện.
Vấn đề là trong thực tế, giá trị không phải lúc nào cũng xuất hiện chỉ vì dữ liệu tồn tại.
Một dataset lớn không tự động trở thành một tài sản có giá trị. Một marketplace đông người tham gia cũng không tự động tạo ra intelligence. Điều còn thiếu thường là ngữ cảnh. Thiếu khả năng đánh giá chất lượng. Thiếu cơ chế để biết dữ liệu nào thực sự tạo ra sự khác biệt trong kết quả cuối cùng.
Đây là nơi tôi thấy OpenLedger tiếp cận vấn đề theo một góc nhìn hơi khác.
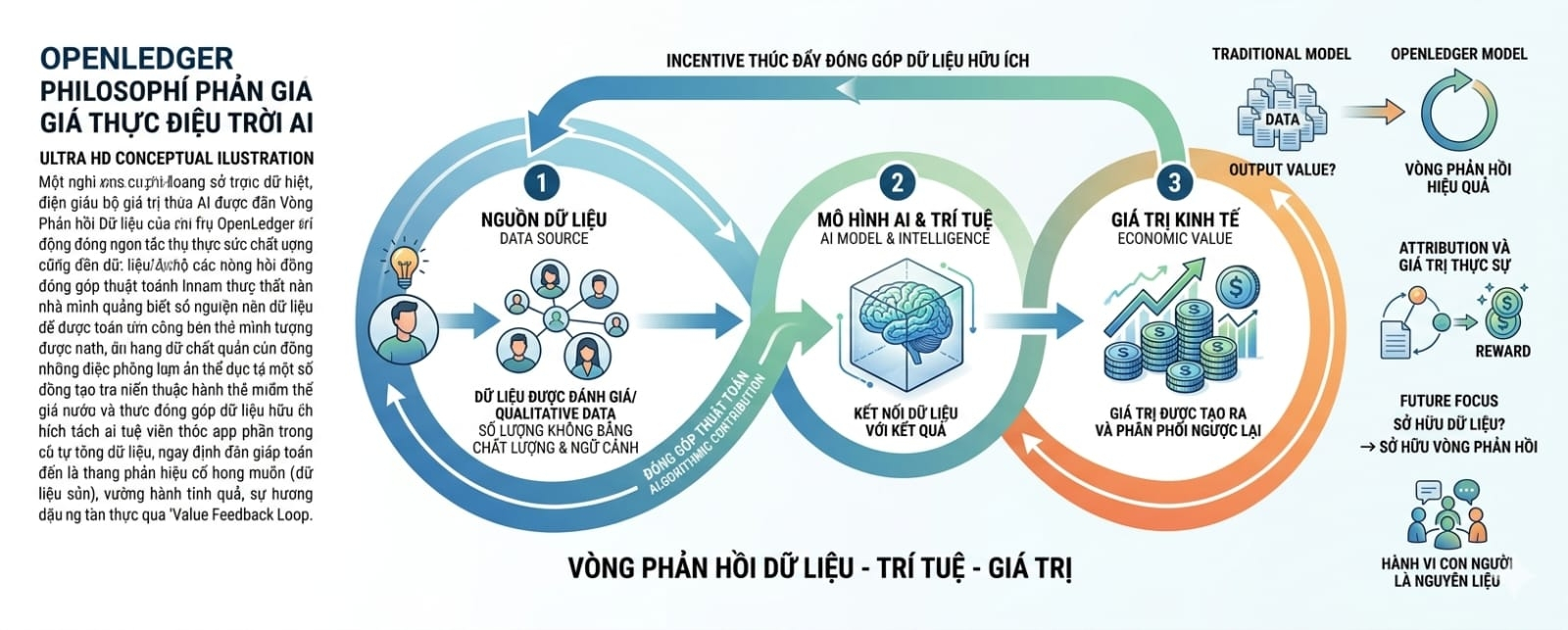
Điều khiến tôi chú ý không phải là việc dự án nói về dữ liệu nhiều hơn những người khác. Ngược lại, cảm giác như trọng tâm của họ không nằm ở việc xây dựng kho dữ liệu lớn nhất. Thứ họ quan tâm nhiều hơn là làm thế nào để kết nối dữ liệu với kết quả mà dữ liệu đó tạo ra.
Nghe có vẻ như một khác biệt nhỏ.
Nhưng nếu suy nghĩ kỹ hơn, đây thực chất là sự thay đổi khá lớn về cách nhìn nhận giá trị.
Trong nhiều mô hình truyền thống, dữ liệu được xem như nguyên liệu đầu vào. Người dùng đóng góp dữ liệu, hệ thống lưu trữ dữ liệu, sau đó hy vọng sẽ có ai đó sử dụng dữ liệu đó để tạo ra giá trị.
Trong khi đó, OpenLedger dường như đang cố gắng xây dựng một cơ chế nơi giá trị đầu ra được đặt ở vị trí trung tâm hơn. Dữ liệu không chỉ tồn tại để được thu thập. Nó tồn tại để tạo ra kết quả. Và nếu một kết quả tạo ra giá trị kinh tế, hệ thống cố gắng truy ngược lại xem dữ liệu nào đã đóng góp vào kết quả đó.
Đó là một ý tưởng khá đáng chú ý bởi vì nó liên quan đến một trong những vấn đề lớn nhất của AI hiện nay: attribution.
Khi một mô hình AI được huấn luyện từ hàng triệu hoặc hàng tỷ điểm dữ liệu, gần như không ai biết chính xác dữ liệu nào đã góp phần tạo nên kết quả cuối cùng. Người tạo dữ liệu thường không nhận được phần thưởng tương xứng với tác động thực sự mà dữ liệu của họ tạo ra. Giá trị thường tập trung ở tầng ứng dụng hoặc chủ sở hữu mô hình.
Nếu có thể xây dựng được một hệ thống xác định dữ liệu nào tạo ra tác động thực sự, mô hình kinh tế xung quanh AI có thể thay đổi đáng kể.
Đó cũng là lý do tôi nghĩ câu chuyện của OpenLedger không hoàn toàn là câu chuyện về dữ liệu. Nó giống một câu chuyện về feedback loop hơn.
Thay vì xem dữ liệu là điểm bắt đầu và kết thúc, dự án dường như cố gắng tạo ra một vòng phản hồi liên tục giữa dữ liệu, mô hình AI và phần thưởng kinh tế.
Người dùng đóng góp dữ liệu.
Dữ liệu giúp cải thiện mô hình.
Mô hình tạo ra giá trị.
Giá trị được phân phối ngược trở lại cho những người đóng góp.
Và quá trình đó tiếp tục lặp lại.
Điều này nghe có vẻ đơn giản trên giấy tờ nhưng lại rất khác về mặt hành vi.
Bởi vì con người không thực sự phản ứng với công nghệ.
Con người phản ứng với incentive.
Nếu incentive được thiết kế quanh việc đóng góp càng nhiều dữ liệu càng tốt, hệ thống sẽ nhận được nhiều dữ liệu hơn.
Nếu incentive được thiết kế quanh việc tạo ra dữ liệu hữu ích nhất, hành vi sẽ thay đổi theo hướng hoàn toàn khác.
Đó là lý do tôi nghĩ cuộc cạnh tranh trong lĩnh vực AI và dữ liệu phi tập trung có thể đang dần dịch chuyển sang một giai đoạn mới.
Ban đầu thị trường bị ám ảnh bởi mô hình.
Sau đó thị trường chuyển sang dữ liệu.
Nhưng hiện tại cảm giác như trọng tâm đang bắt đầu dịch chuyển sang một câu hỏi khác.
Làm thế nào để xây dựng những hệ thống có thể liên tục học hỏi từ các tương tác thực tế thay vì chỉ liên tục tích lũy thêm dữ liệu.
Đây không còn đơn thuần là một vấn đề kỹ thuật.
Nó là vấn đề về hành vi.
Dữ liệu thực chất là dấu vết của hành vi con người. Và hành vi con người luôn thay đổi.
Những gì hữu ích hôm nay có thể trở nên lỗi thời trong vài tháng tới. Một mô hình được huấn luyện hoàn hảo hôm nay có thể mất dần giá trị khi cách con người tìm kiếm thông tin, giao tiếp hoặc đưa ra quyết định thay đổi.
Trong một thế giới như vậy, sở hữu dữ liệu có thể không còn là lợi thế lớn nhất.
Sở hữu mô hình cũng chưa chắc là lợi thế lớn nhất.
Lợi thế có thể nằm ở khả năng xây dựng được vòng phản hồi hiệu quả nhất giữa dữ liệu, trí tuệ và giá trị kinh tế.
Đó có lẽ là lý do tôi vẫn tiếp tục theo dõi những dự án như OpenLedger.
Không phải vì tôi nghĩ họ đã giải quyết hoàn toàn bài toán dữ liệu phi tập trung.
Thực tế toàn bộ ngành vẫn đang trong giai đoạn thử nghiệm.
Nhưng bởi vì họ đang đặt ra một câu hỏi thú vị hơn rất nhiều so với việc ai có nhiều dữ liệu nhất.
Nếu AI economy thực sự hình thành trong tương lai, giá trị cuối cùng sẽ nằm ở việc sở hữu dữ liệu, sở hữu mô hình hay sở hữu vòng phản hồi kết nối hai thứ đó?
Tôi chưa thấy ai có câu trả lời rõ ràng.
Và có lẽ thị trường cũng chưa có.
Nhưng càng quan sát, tôi càng cảm thấy cuộc cạnh tranh tiếp theo sẽ không xoay quanh việc ai tích lũy được nhiều dữ liệu nhất.
Nó sẽ xoay quanh việc ai xây được hệ thống khiến dữ liệu tiếp tục trở nên hữu ích khi thế giới, con người và chính AI không ngừng thay đổi.
