I did not understand @OpenLedger properly when i first looked at the token page.
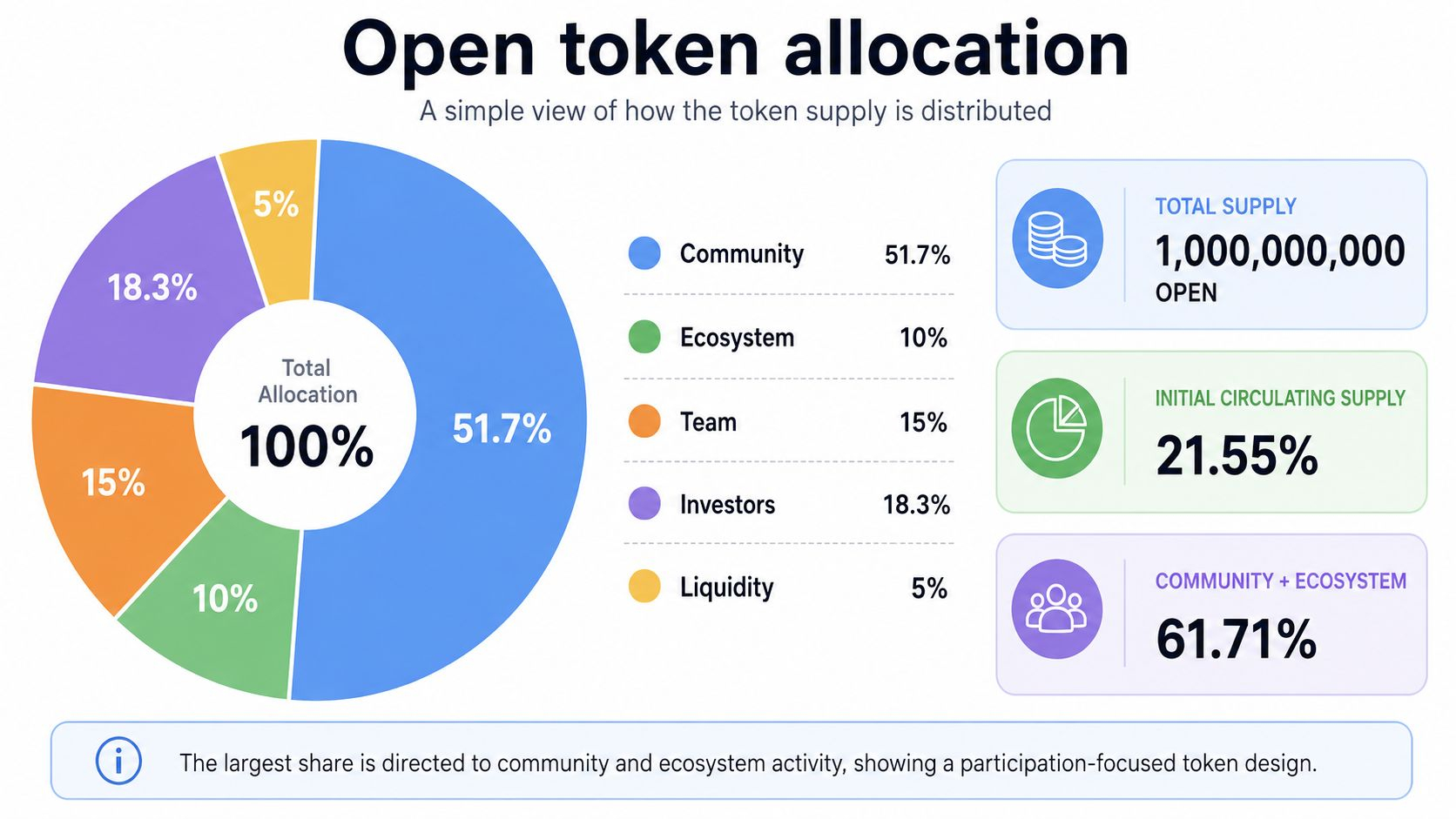
It looked simple at first. Open has a supply. It has an allocation chart. It has some use cases. It follows the erc20 standard. The total supply is 1,000,000,000 open. The initial circulating supply is 21.55%. These are useful facts, but they did not tell me the full story by themselves.
So i looked at it in another way.
I asked myself what open is actually trying to do inside the openledger network.
That question made the topic more interesting to me. Because openledger is not only building around crypto. It is also building around ai, data, models, and attribution. So the tokenomics should not be read like a normal token chart only. It should be read like a small map of how value may move inside the network.
That is the point i want to focus on.
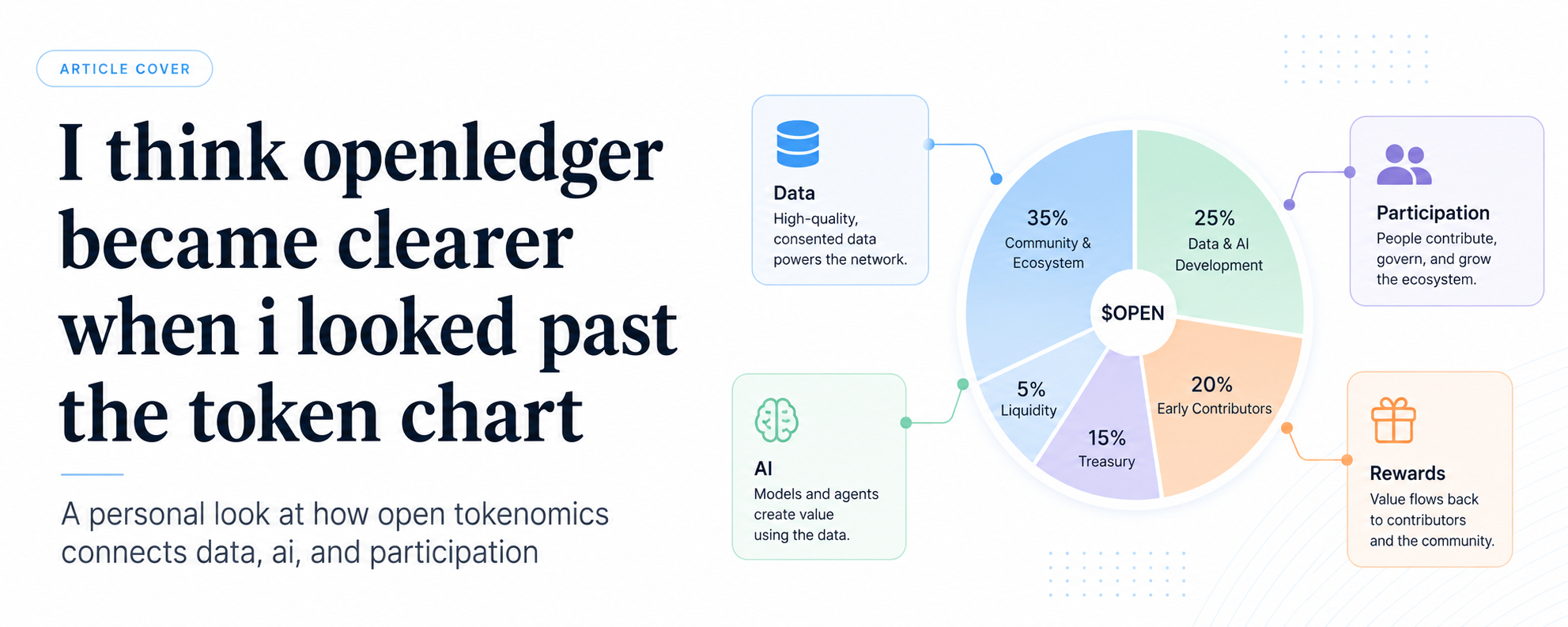
$OPEN is the native token of the openledger ai blockchain. It is used as gas for activity on the chain. It is also used for ai actions like inference, model training, model deployment, and model access. Open is also connected to rewards for data contributors through proof of attribution.
For me, this is where the token starts to feel more serious.
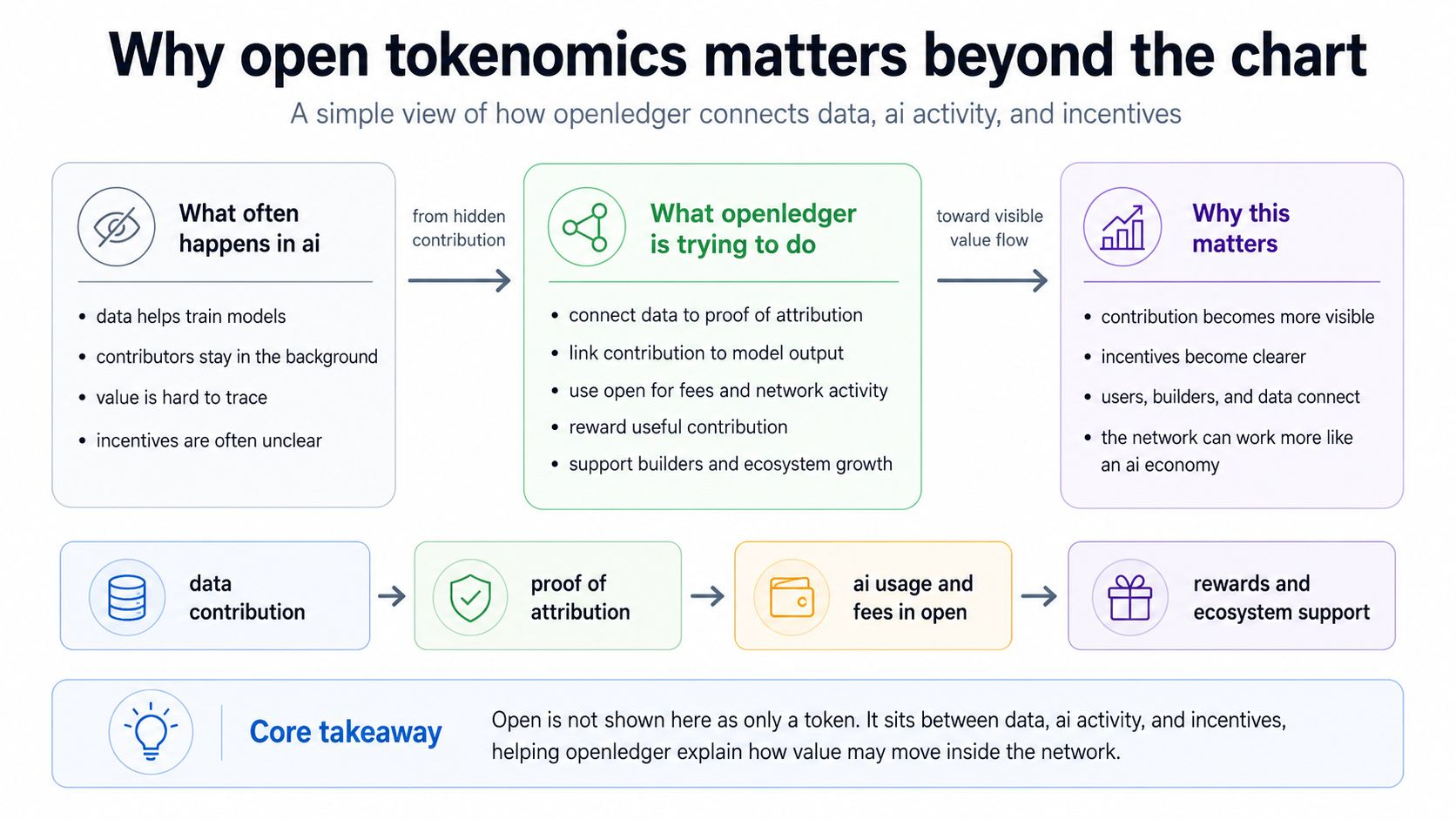
Most people talk about ai from the front side. They talk about the model. They talk about the output. They talk about how fast or useful the answer is. But the model is not the full story. Behind every useful ai system, there is data. There are examples, records, human knowledge, clean information, and small contributions that most people never see.
That hidden part matters.
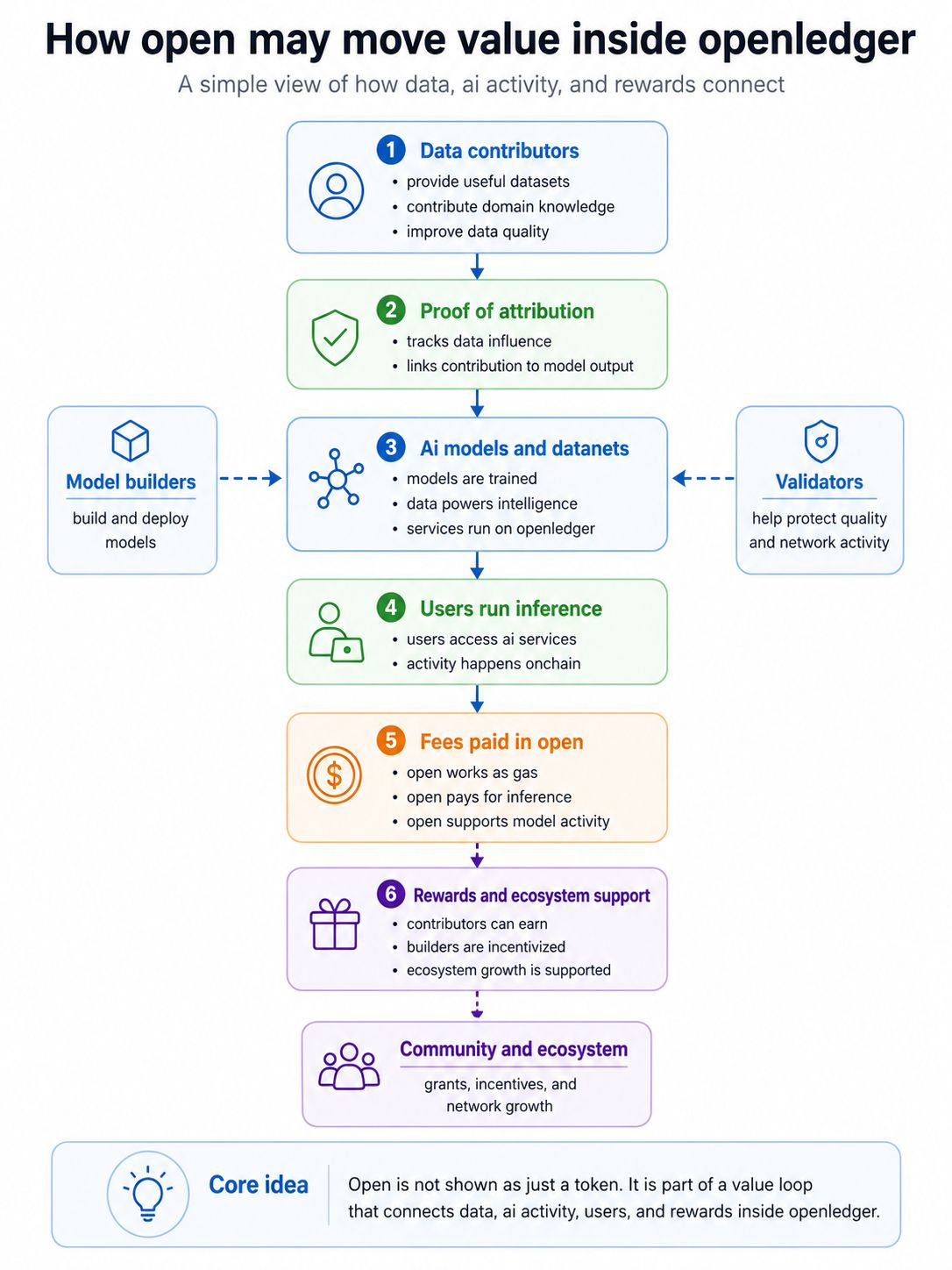
Openledger is trying to bring that hidden part closer to the reward system. Its proof of attribution idea is about tracking which data helps influence model output. In simple words, if some data helps a model become useful, the contributor should not be completely invisible.
I like this idea because it feels practical.
It is not only saying that ai should be open. It is asking who should get value when ai creates value. That is a much better question than only asking how big the token supply is.
The allocation also gives a clue about the project’s direction. Openledger lists 61.71% for community and ecosystem allocation. That part is meant to support things like contributor rewards, model incentives, developer grants, datanet development, opencircle support, airdrops, hackathons, bounties, and public goods funding.
I do not see that as just a big percentage.
I see it as the part of the design that tries to pull more people into the network. A project like openledger cannot grow only from investors or a team. It needs people who build models. It needs people who bring useful data. It needs developers who test ideas. It needs validators who help protect quality. It needs users who actually run ai tasks.
Without that real activity, tokenomics is only a page.
This is why i think the open token story is more about incentives than hype. A user may spend open to use an ai model. A model builder may earn from real usage. A data contributor may receive rewards if their data has value. The network may also support grants and public goods from the community and ecosystem pool.
That creates a loop.
Usage can support builders. Builders can improve models. Better models can attract more users. Better data can improve the whole system. If the loop works, open becomes more than a token name. It becomes the unit that helps connect the different parts of the ai economy.
I am not saying this is already guaranteed.
That would be too easy and not honest. A token design can look good on paper, but the real test is adoption. Openledger still needs strong builders, useful datasets, trusted attribution, active users, and real demand for ai services. If those parts do not grow, the token design alone cannot carry everything.
Still, i think the structure is worth paying attention to.
What i find different here is the link between ai and contribution. In many ai systems, people provide data or knowledge, but they never know where it goes. They do not know if it helps a model. They do not know if it creates value. They also do not have a clear way to earn from that value.
#OpenLedger is trying to create another path.
The idea is that data should not stay silent forever. If data helps the system, that contribution should have a chance to be seen and rewarded. That is why proof of attribution matters in this topic. It gives the open token a role that is not only about fees. It connects the token to fairness, ownership, and participation.
For me, this is the real social impact.
It can give contributors more recognition. It can make ai systems feel less closed. It can encourage people to bring better data because there is a clearer reward path. It can also help builders create models that are connected to real usage instead of only being launched and forgotten.
This is also why open is connected to both crypto and the economy.
It is connected to crypto because it uses blockchain infrastructure and an erc20 token design. It is connected to the economy because it creates a way for people to pay, earn, build, contribute, govern, and support the network through one shared token.
That is why i do not want to describe open only as a supply number.
The supply is important. The allocation is important. The utility is important. But the bigger idea is how these parts work together. Openledger is trying to build a system where data, models, users, and contributors are not separated from the value they help create.
When i look at it this way, open tokenomics becomes easier to understand.
It is not just a chart. It is a value map.
And for me, that is the stronger story behind openledger.