I used to assume that the biggest weakness in AI platforms was centralization. One company owns the model, another controls the data, users only see the final answer, and contributors disappear somewhere inside the pipeline. That explanation still feels partly true, but it now feels too simple. The deeper problem is not only who owns the AI system. It is whether the system can prove how value was created after the output has already been delivered.
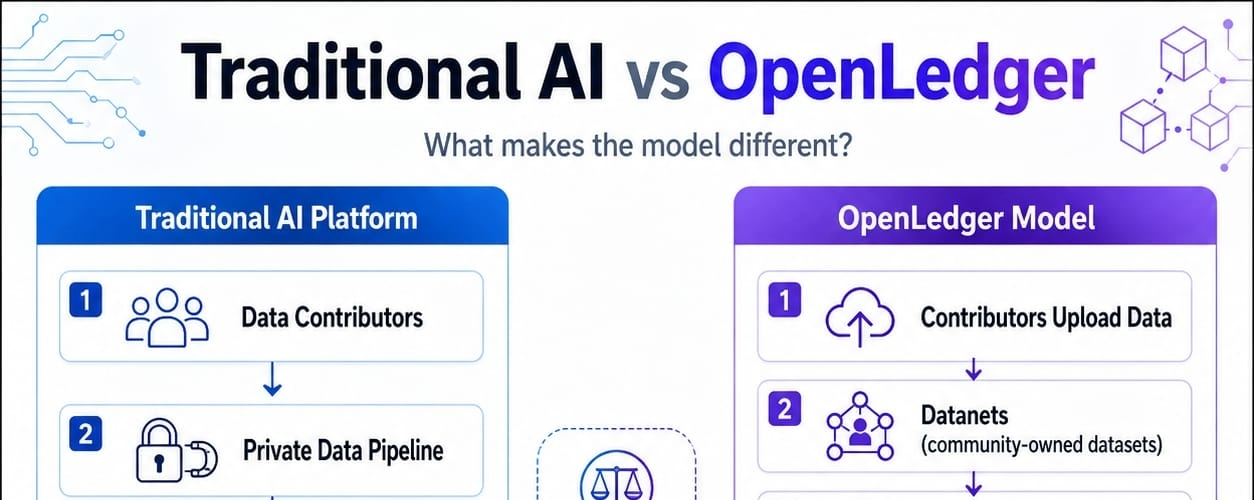
That is where OpenLedger becomes interesting to me. Traditional AI platforms usually treat data as an input that gets absorbed into a private training process. Once the model is trained, the original contribution becomes hard to trace. OpenLedger tries to make the AI lifecycle more accountable by recording dataset uploads, model training, reward credits, and governance participation on-chain. Its docs describe the platform as AI-blockchain infrastructure for training and deploying specialized models through community-owned datasets called Datanets.
The model is different because OpenLedger is not only asking, “Can we build better AI?” It is asking, “Can we make AI outputs economically and cryptographically accountable?” That is a harder question. A normal AI platform can scale by hiding complexity. OpenLedger has to scale while keeping attribution visible. That creates the real tension: throughput wants speed, but cryptographic truth wants proof.
Datanets sit at the center of that tension. They are designed as decentralized data networks that aggregate, validate, and distribute domain-specific datasets for model training, with verifiable attribution attached to contributions. In theory, this changes the role of a data contributor. They are not just donating raw material into a black box. They are participating in a recordable economic layer where their contribution can later be connected to model usage.
Proof of Attribution is the mechanism that tries to make that connection meaningful. OpenLedger describes it as a cryptographic mechanism that links data contributions to AI model outputs, keeps an immutable record, and rewards contributors based on the impact of their data. The attribution pipeline includes contribution, influence measurement, training verification, reward distribution, and penalties for malicious or low-quality data.
This is where the infrastructure question becomes serious. AI systems can generate a huge number of inferences. If every contribution, training event, attribution score, and reward flow creates state, the chain cannot behave like a slow accounting notebook. It needs a scaling model. In rollup-style architecture, execution can be batched off-chain while the system posts compressed state updates and proofs back to a settlement layer. ZK-rollups are commonly described as executing batches off-chain, then submitting validity proofs that show the proposed state transition is correct.
Applied to OpenLedger’s problem, the idea is simple but difficult: rollups handle throughput, while cryptographic state transitions protect the attribution record. The rollup side is about absorbing activity. The cryptographic side is about making sure that the reward logic, contributor influence, and model-data relationships are not quietly rewritten later. If attribution becomes money, then attribution records cannot be soft promises. They have to become protected state.
Zero-knowledge proofs add another layer to this discussion because they allow validity to be proven without revealing all underlying information. That matters in AI because some datasets may be sensitive, proprietary, or permissioned. A system that wants verifiable attribution may still need privacy boundaries. ZK does not magically solve every data problem, but it gives a path toward proving that something happened correctly without exposing everything behind it.
Still, I would not treat this as already solved. The stress test is not whether the architecture sounds elegant on paper. The stress test is heavy usage. What happens when thousands of contributors upload overlapping data? What happens when models draw from many Datanets at once? Can influence scores remain fair when spam, duplicate content, adversarial submissions, and low-quality data enter the system? Can rewards stay meaningful without creating a race to farm attribution?
OpenLedger’s own Proof of Attribution paper acknowledges the scalability problem by using different attribution approaches for different model sizes: influence-function approximations for smaller models and suffix-array-based token attribution for larger models. It also emphasizes training provenance, deterministic attribution, and real-time reward distribution. That tells me the team is at least looking at the hard part, not only the narrative layer.
My balanced view is this: OpenLedger is not automatically better than traditional AI platforms just because it uses blockchain. The real advantage only appears if the system can preserve attribution under load, reward useful data rather than noisy data, and keep cryptographic records cheap enough to matter in daily AI usage. But it is worth watching because it asks the right infrastructure question. In AI, the future may not belong only to the platform with the smartest model. It may also belong to the system that can prove who helped create the intelligence behind the answer.