Most projects in AI and crypto seem to follow the same script. Bigger models, faster inference, more agents, more automation, more scale. The language changes slightly, but the story usually stays the same. That's probably why OpenLedger caught my attention. Not because it was easier to understand, but because it felt like it was asking a different question altogether.
The more I read, the less it felt like I was looking at another AI project and the more it felt like I was staring at a problem the entire industry has been quietly avoiding.
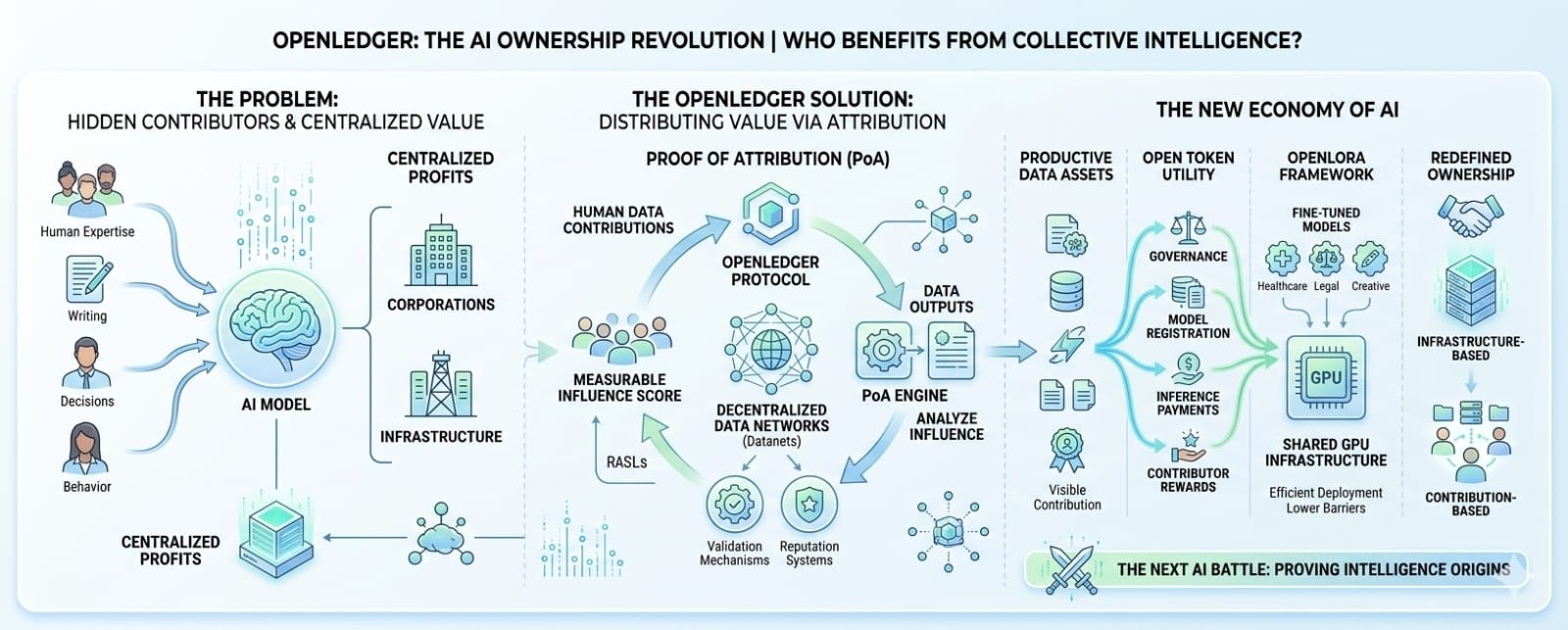
Everyone talks about artificial intelligence. Everyone talks about what AI can do. But very few people stop and ask where its value actually comes from.
A model doesn't become intelligent on its own. It learns from data. Massive amounts of data. Human writing, human decisions, human expertise, human corrections, human behavior. Behind every impressive AI output is a long chain of contributions made by people who will probably never be visible to the end user.
Yet when value is created, when products generate revenue, and when companies become worth billions, the connection between those original contributions and the rewards created from them becomes surprisingly difficult to see.
That was the point where OpenLedger started to feel different to me.
What stood out wasn't the focus on building AI. Plenty of projects are doing that. What stood out was the focus on attribution. At first, I'll admit, attribution sounded like the least exciting thing imaginable. Crypto has conditioned people to pay attention to flashy narratives. Autonomous agents, decentralized intelligence, infinite scalability, digital economies. Those ideas immediately grab attention.
Attribution doesn't.
But the more I thought about it, the more important it started to seem.
Because if nobody can prove which data influenced an AI model, then how do we decide who deserves a share of the value that model creates? If intelligence is built from collective contributions, how do we define ownership? How do we track value from the moment it is created to the moment it is captured?
Those questions kept following me through everything I read about OpenLedger.
The concept they return to repeatedly is something called Proof of Attribution. Initially, I assumed it was another industry buzzword. The space has no shortage of those. But the deeper I went, the more obvious it became that this isn't just a feature sitting on top of the protocol. It's the foundation underneath it.
The basic idea sounds simple. When an AI output is generated, the system attempts to identify which data contributions influenced that result. Rewards can then be distributed according to influence rather than simply participation. On paper, it sounds logical.
In practice, it raises some difficult questions.
Can influence really be measured accurately? Is one contribution more valuable than another? Who decides what influence means? The model? The protocol? Consensus? Human validators?
I don't think there are easy answers.
And honestly, that's what makes the problem interesting.
Technology challenges are difficult, but incentive challenges are usually much harder. History has shown that repeatedly. A protocol can have excellent technology and still fail if the incentives don't work. People optimize for rewards. People search for loopholes. People game systems. Human behavior tends to be far more unpredictable than code.
That's why I found myself thinking less about the technical architecture and more about the economic architecture.
OpenLedger introduces the idea of decentralized data networks, or Datanets, where communities can contribute, validate, and maintain domain-specific datasets that eventually help power AI systems. On the surface, that sounds straightforward. But the implications are larger than they appear.
Today's AI economy is heavily centralized. Data often comes from one group while value flows somewhere else entirely. OpenLedger appears to be trying to reconnect those two sides by creating a structure where contributions remain visible and economically relevant long after they are made.
What makes this idea fascinating is that it treats data as something more than raw material. It treats data as a productive asset.
If that model works, then the relationship between contributors and AI systems changes completely.
Of course, that immediately creates another challenge. Decentralization always sounds great when coordination is easy. The real test begins when coordination becomes difficult. Maintaining quality, preventing spam, discouraging manipulation, resisting Sybil attacks, and creating fair reputation systems are all incredibly difficult problems.
The whitepaper discusses influence scoring, contributor reputation, validation mechanisms, and slashing systems. Those ideas make sense in theory. The question is whether they can survive real-world behavior.
Because reality has a habit of exposing weaknesses that theory never anticipated.
Another part of OpenLedger that kept pulling my attention was its approach to ownership.
Training AI models is becoming increasingly expensive. Infrastructure is expensive. Compute is expensive. Distribution is expensive. As costs rise, power naturally concentrates among a relatively small number of organizations.
OpenLedger seems to be exploring an alternative path where ownership doesn't sit exclusively with the organizations that control the infrastructure. Instead, ownership becomes connected to contribution itself.
That concept feels much larger than tokenomics.
It feels like an attempt to rethink how value is distributed throughout the entire AI economy.
The OPEN token plays a central role in that vision. It connects model registration, governance, inference payments, contributor rewards, and network activity into a single economic layer. We've heard the phrase "utility token" countless times throughout crypto history, but OpenLedger appears to be trying to link utility directly to AI activity rather than simply attaching a token to a product.
If models generate demand, fees are created. If contributors provide valuable data, rewards can be distributed. If the network grows, economic activity potentially grows alongside it.
At least that's the theory.
Whether theory survives reality is always the harder question.
The project also introduces OpenLoRA, a framework designed to make specialized model deployment more efficient by allowing multiple fine-tuned models to operate on shared GPU infrastructure. On the surface, it sounds like a technical optimization. But underneath that optimization is a much larger issue.
Access.
The AI industry is increasingly shaped by compute concentration. A small number of organizations control a significant amount of the infrastructure required to build and deploy advanced systems. Lowering deployment costs won't eliminate that problem overnight, but it could reduce some of the barriers that prevent broader participation.
And participation matters.
Technology alone rarely creates an ecosystem. Ecosystems emerge when enough people believe participation is worthwhile. Belief itself becomes an economic force.
That's one reason I keep coming back to patience when thinking about OpenLedger.
Infrastructure projects tend to move slowly. Contributor networks take time to grow. Trust takes time to build. Network effects take time to emerge. Yet markets usually demand immediate results.
That tension creates risk.
I've seen projects with impressive technology fail because they never received enough time to mature. I've also seen projects with weaker fundamentals survive because they captured attention at exactly the right moment.
Markets can be surprisingly irrational.
That's part of what makes OpenLedger difficult to evaluate.
Its ambitions are large. It isn't simply trying to launch another blockchain or another AI application. It appears to be addressing a structural problem that sits underneath the entire AI industry.
Whether it succeeds remains uncertain.
But the question it is asking feels increasingly important.
If data has value, what role should contributors play in the economic system built on top of it? If AI generates revenue, how should that revenue be distributed? If intelligence emerges from collective human input, should ownership also be collective?
Those questions might seem abstract today, but they may become impossible to ignore as AI continues expanding into every part of the economy.
And that's probably my biggest takeaway after reading OpenLedger.
The thing that stayed with me wasn't the technology. It wasn't the token. It wasn't even the models.
It was the realization that the next major AI battle may not be about building intelligence.
It may be about proving where intelligence came from.
Because once value becomes measurable, ownership becomes measurable.
And once ownership becomes measurable, the entire economic structure around AI starts to change.
If that future arrives, OpenLedger won't simply be another project participating in the conversation.
It will be one of the projects that saw the question coming before most people realized it was there.
