My first doubt with OpenLedger is the same doubt I have with most AI attribution projects: contribution sounds easy to reward until you actually try to measure it.
AI value is rarely clean. A useful answer may come from many datasets, many training steps, model tuning, filtering, and inference behavior that most users never see. So when a project says it can connect contributors to AI outputs and reward them fairly, I do not start with excitement. I start with a question: can this system prove contribution strongly enough for contributors to become real economic participants?
That is where OpenLedger becomes interesting to me.
OpenLedger describes itself as AI-blockchain infrastructure for training and deploying specialized models using community-owned datasets called Datanets. Its docs say dataset uploads, model training, reward credits, and governance participation are executed on-chain. That matters because OpenLedger is not only trying to build AI tools. It is trying to make contribution part of the economic record behind AI itself.
The deeper idea is Proof of Attribution.
Proof of Attribution is OpenLedger’s mechanism for linking data contributions to AI model outputs. The purpose is to keep an immutable record of contribution, trace data back to contributors, and reward them based on the impact of their data. In plain language, OpenLedger is trying to answer a question traditional AI usually avoids: who helped create the value behind this output?
But this is also where the architecture gets tested.
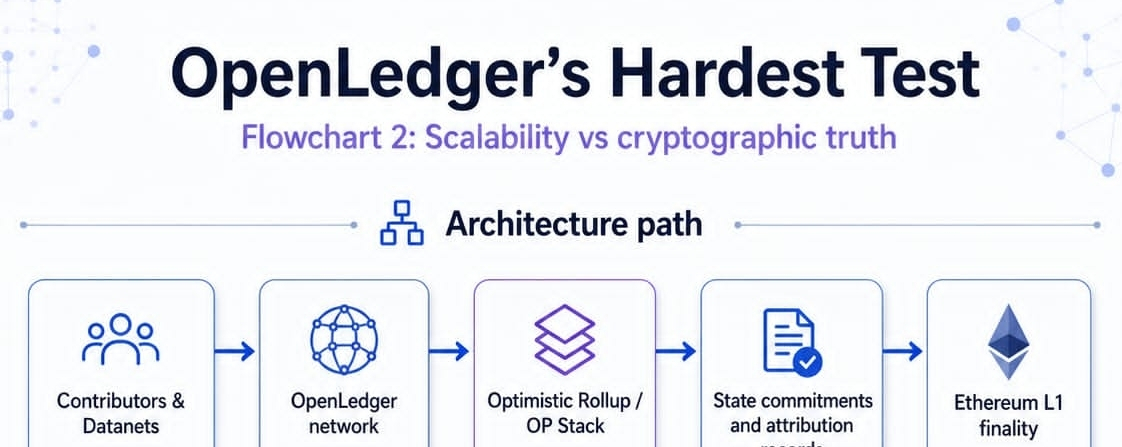
Attribution needs truth, but AI needs scale. If every dataset upload, training log, inference trace, attribution calculation, and reward update becomes too heavy, the system slows down. If too much happens off-chain without enough verification, the system becomes faster but weaker. This is the tension I think matters most: scalability versus cryptographic truth.
OpenLedger’s own network docs describe an Optimistic Rollup model using the OP Stack for scalability while maintaining Ethereum as the parent chain. Transactions are processed off-chain and submitted to L1 for finality, with blocks produced every two seconds. That gives the system a practical scaling base instead of forcing every activity directly through the most expensive layer.
This matters because AI attribution is not a simple payment flow. It is closer to an accounting system for intelligence. A contributor submits data. The data enters a DataNet. A model trains or fine-tunes on that data. Later, during inference, the system has to identify which data influenced an output and how much weight that contribution deserves. If OpenLedger grows, that process has to survive heavy usage without losing the integrity of the record.
That is where cryptographic state transitions become important. Rollups can help handle throughput, but the final state still needs to be trustworthy. The point is not just to process more activity. The point is to protect the attribution record so rewards, contributor history, and model-data relationships cannot be quietly rewritten.
OpenLedger’s Data Attribution Pipeline shows how the system tries to structure this. Contributors submit domain-specific datasets, each dataset is attributed on-chain, influence is measured, training logs are recorded, rewards are distributed based on attribution, and low-quality or malicious contributions can be penalized. That is important because a contributor economy cannot only reward volume. It has to reward useful influence and resist spam.
The OpenLedger paper goes deeper. It describes Proof of Attribution as a system where DataNets allow contributors to build specialized datasets, models log training provenance, and attribution can support explainability and real-time reward distribution. It also explains that attribution must be both precise and scalable, using influence-function approximations for smaller models and suffix-array-based token attribution for larger models.
This is the part I find most serious. OpenLedger is not only saying “contributors should be paid.” It is trying to define how their impact can be measured across different model sizes and inference contexts. The paper describes influence weights being recorded on-chain with model identifiers, output hashes, and attribution metadata, creating a tamper-resistant trail from training data to output.
ZK proofs fit into this discussion as the broader verification question. If AI contribution needs privacy, scalability, and proof at the same time, then zero-knowledge methods may become useful for proving that certain attribution or state updates followed the rules without exposing every sensitive detail. But I would not treat ZK as a magic answer. The real question is whether verification can stay efficient when demand becomes real.
That is the stress test for OpenLedger.
Can it handle many contributors, many Datanets, repeated model updates, inference-level reward claims, and attempts to game the system? Can it keep attribution understandable when the model stack becomes more complex? Can contributors actually verify why they were rewarded, instead of simply trusting a dashboard?
I am not convinced this problem is solved yet. AI attribution is difficult, and economic incentives usually expose weaknesses that look small in early design. But I do think OpenLedger is asking the right infrastructure question.
If AI value comes from many invisible contributors, then those contributors need more than recognition. They need a record, a reward path, and a way to prove, that their work mattered.
That is why OpenLedger is worth watching. Not because it guarantees a perfect contributor economy today, but because it is building around one of the hardest questions in AI: can contribution become traceable enough to become an economic identity?