
最近一堆喊单群天天拿“AI+Web3”的宏大叙事洗脑,但我一贯对这种缝合怪赛道有生理性防备。今天闲着也是闲着,干脆来扒一扒,OpenLedger这套“给AI喂纯净水”的数据打假逻辑,到底是个什么成分。别急着反驳,我也不是逢新必喷,只是被各种挂羊头卖狗肉的AI空气币割出抗体了。他们这套数据处理模型确实切中了痛点,但离真正的“护城河”还有十万八千里。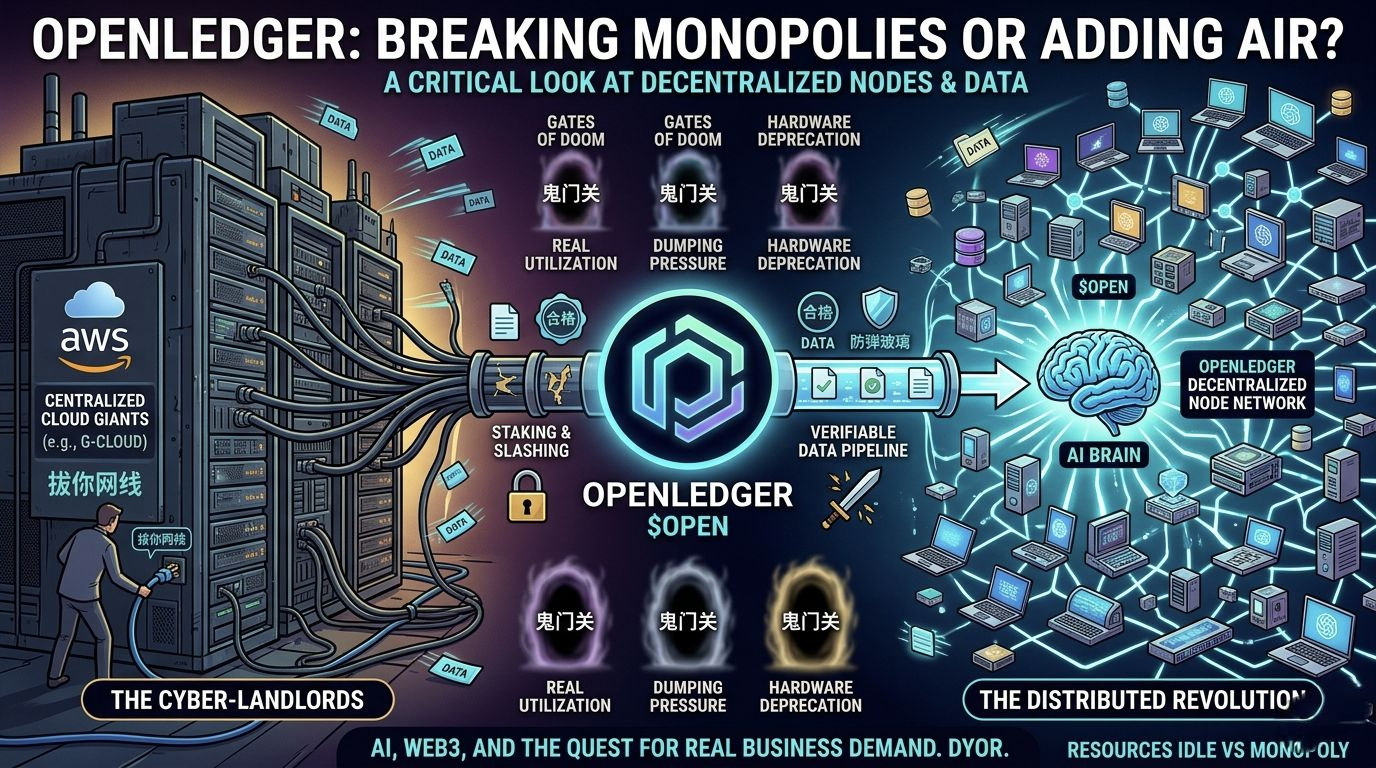
愿景挺性感:给AI的“饲料”贴上防伪溯源标
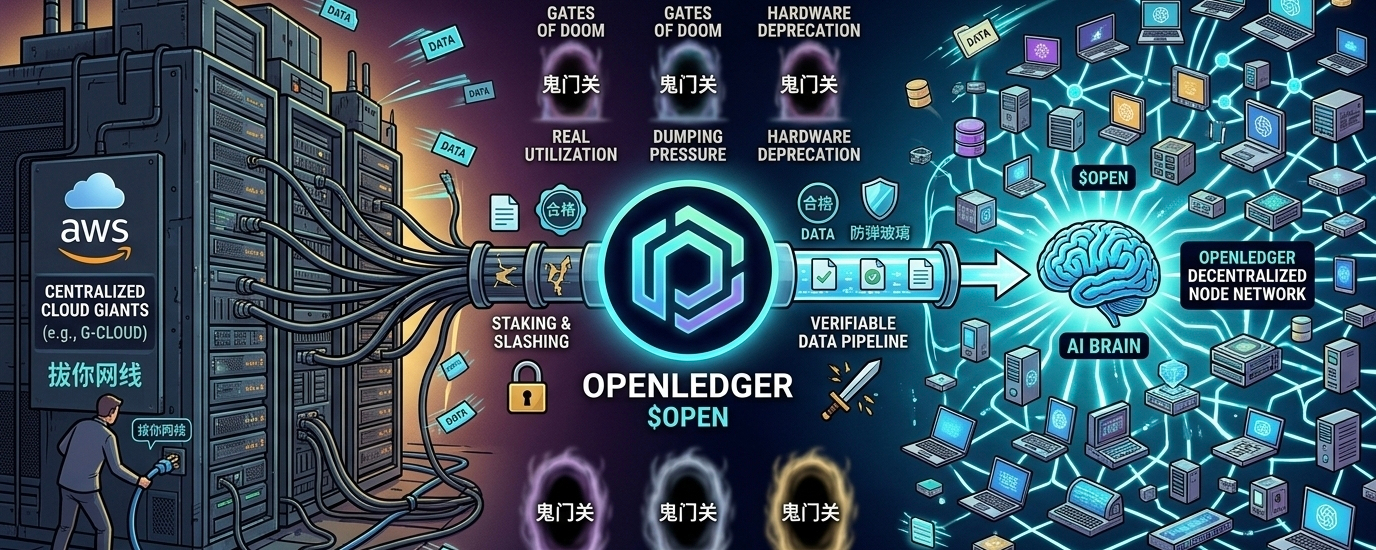
先聊聊@OpenLedger 这次切入的角度为什么还算讨巧。现在的AI巨头(比如OpenAI那些)其实挺流氓的,满世界狂暴爬取数据,根本不管什么版权,里面还掺着海量的垃圾信息、机器生成的废话。OpenLedger想干的事,就是搞一个可验证的数据管道(Verifiable Data Pipeline)。
我比较认可的是他们没有单纯搞个链上数据库就出来圈钱,而是想给数据上密码学“封条”。有点像给每一份喂给AI的语料做一份不可篡改的质检报告,保证这玩意在传输过程中没被动手脚。这套逻辑,对于现在深陷版权官司和“垃圾进,垃圾出(Garbage in, Garbage out)”窘境的AI大模型来说,确实是刚需。相比于那种虚无缥缈的“去中心化算力”,高质量的语料库更是现在AI大厂拼刺刀的核心资源。
现实很蛋疼:谁来鉴定“纯洁的垃圾”?
但咱们扒开这层高科技外衣看看内里,现实永远比白皮书骨感得多。去中心化验证听着牛逼,但这里有个最基础的“神谕机(Oracle)困境”——如果源头数据本身就是错的呢?
打个极端的比方:如果我雇了一波水军,或者直接用AI生成一堆“指鹿为马”的优质排版文本上传到网络里,你的链上技术再牛逼,密码学证明再严丝合缝,也只能证明“这坨垃圾原封不动地上链了”,并不能把垃圾变成黄金。
OpenLedger官方设计了一套质押和共识机制来过滤劣质数据,但这中间不可避免地又要陷入人性的博弈。只要有代币奖励,就绝对会有羊毛党写脚本疯狂刷数据。为了对抗这种女巫攻击,系统就不得不提高验证节点的门槛,最后搞不好又绕回了中心化审核的老路。这种“防君子不防小人”的数据验证网络,如果在冷启动阶段压不住刷子,整个数据池的质量就会瞬间崩塌。
跨不过的三道“鬼门关”
还是那句话,别光看推特大V吹得天花乱坠,理智点看,这条路离真正跑通还隔着好几道鬼门关。想在这个生态里做数据提供者或者投资人,先掂量掂量这几个疙瘩:
第一,真实的买方市场到底在哪里?
这是最核心的灵魂拷问。AI巨头现在自己爬数据虽然脏,但是零成本啊!凭什么要花真金白银去买你OpenLedger网络里所谓的高纯度数据?如果没有非币圈的传统AI企业来采购,没有外部的“活水”资金进场,全靠代币通胀来奖励数据上传者,这就依然是个左手倒右手的零和游戏。
第二,版权合规的死胡同怎么破?
你宣称帮人确权,那如果有人把《纽约时报》的付费文章扒下来,通过你们的网络上传并卖给AI模型,这算谁的锅?是上传者的,还是网络的?如果解决不了这种“洗稿”带来的法律风险,这个所谓的高质量数据市场随时可能吃官司,被一窝端。
第三,$OPEN 的价值捕获黑洞
这就涉及代币经济学了。如果OPEN只是用来奖励上传数据的散户,那它每天都在通胀。必须要有极强的消耗场景——比如AI公司必须质押/消耗OPEN才能调用高质量数据集。但这种商业模式到底能跑通多少流水?代币的消耗速度能不能跑赢羊毛党的挖提卖抛压?这都是要在主网上线后真刀真枪拼杀的。
结语
总而言之,OpenLedger死磕“AI数据可验证”这条路,比单纯做个二道贩子倒卖算力要有野心得多,但也难上十倍。这事儿要是真做成了,确实能在现在一众蹭AI热点的空气项目里杀出一条血路;但要是没把控好质量,那就是个披着区块链外衣的数据垃圾场。
看好归看好,但我根本不信那些KOL嘴里的“下一个百倍神话”。对于咱们来说,少听故事,多看数据。我就盯死一点:到底有没有真实世界的AI公司,在用真金白银(或等价代币)采购他们的数据池。 没有真实买单的业务,一切经济模型都是在沙滩上建城堡。
这就是这两天翻完他们数据流转架构的一点瞎哔哔。想在这个项目里打金或者屯币,别怪我没提醒你,先去把他们怎么防作弊的机制啃明白,护好自己的本金,DYOR。